

How to tame a frenzy of tasks with Celery



Using Celery in our projects is not a constant, but from time to time we need to deal with some kind of asynchronous tasks for example, sending emails, calling APIs, and such. But this time we faced another kind of challenge, we needed to implement a processing intensive pipeline to download tweets, un-short URLs, get the sentiment using MonkeyLearn among other tasks. Celery looks like a perfect tool but, as in other aspects of life itself, it all depends on how you use the tool.
A brief introduction, we have a chain of 7 tasks where tasks schedules new tasks in cascade and here is an image that tries to reflect how it is done (read it top-down).

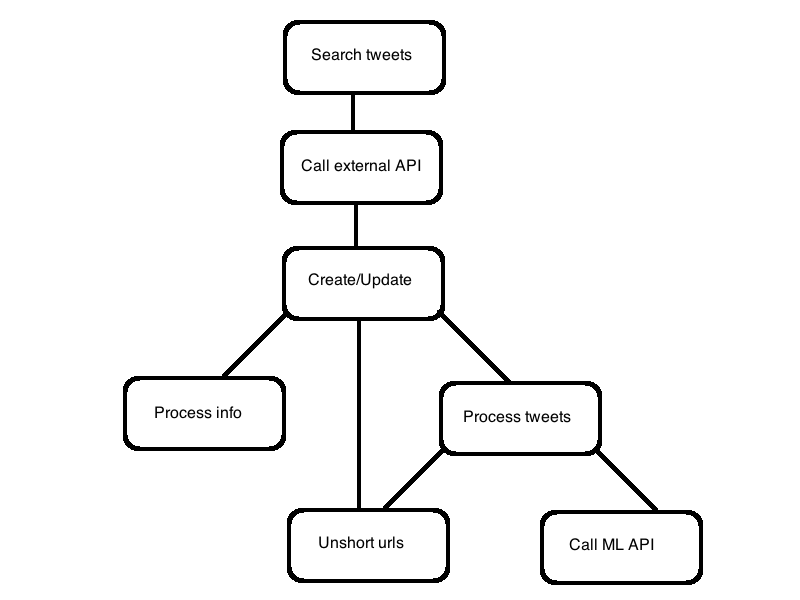
Let's see what were the requirements and technical challenges:
- We need to see results as they are available and as soon as possible, a result is available after we have un-shorten the url and categorised the content (the last two boxes in the image).
- Corollary, the naïve approach of linear programming is not an option.
- We used an external API to organize user and content.
- If a new process request arrives, we have to cancel the current run and start processing the new request.
- To unshort a url takes time, a lot of time, because they have several redirects.
- Twitter API throttling.
- To give a rough estimate of the number of tweets and users is about 100.000+ tweets and about 100+ users.
- Did I mention we need to see results ASAP?
Lets see how to solve these requirements and constraints.
Getting results quickly
Our first approach had one queue, one worker with autoscale, just as it is out of the box. This approach seemed fine beforehand because it started executing the tasks as they were applied (FIFO), this means we first search for tweets, then we wait for all external API calls and then we start creating/updating and after all these tasks finishes we started the other set of tasks. I've just described the problem with this approach, although it is more efficient than the naïve approach because we are parallelising tasks and there are no dead times, it was still too slow since we needed to execute many tasks until we get results (remember, the results appeared after the last task is executed).
So this requirement wasn’t quite solved with this approach. Down the road we changed our approach and our final implementation had one queue per task with one worker listening to each queue with many concurrent threads. By doing this we make sure that we don’t block a task if it has all the information it needs and also we keep spawning new tasks.
It is worthy to tell that these two approaches will take the same amount of time to finish all the tasks but it is the order in which those tasks finish that makes the difference.
Priorities
So, we have one queue for each task. But now we want to execute tasks in order regarding the relevance of the content. In the past you would have to manually route tasks to different queues to emulate priority queues as they suggested in their documentation but since version 3.5 of RabbitMQ and emulation from Redis Celery 4 now supports prioritising tasks as you can see in their documentation.
Twitter API throttling
First, an intro to the problem. Twitter API is very restrictive with the limits, and hitting the limits means no more access for 15 minutes. So it is very important to avoid this situation.
Until now we have a very aggressive set of tasks, we need a way to control them. There is a Celery feature that comes very handy called rate limit. Basically you tell Celery how many of this tasks can be executed in certain amount of time. This is declared when you are decorating the task and has the the notation of "# tasks/minute", further information regarding this can be found in their documentation.
The key here is to split the tasks and perform one API call each time the task executes, this is not always possible and there you should use another approach like decreasing the frequency.
Cancelling scheduled, reserved and active tasks
I had faced this problem before, so I knew where to start. Celery comes with a handy inspector that you can use to see what tasks are active (currently running), reserved (that have been prefetched by the worker from the broker), scheduled (reserved by the worker because they have the ETA or countdown).
But if you want to have a fresh start for a new set of tasks, you also have to flush the broker queues as well, and Celery also gives you an interface to communicate with the AMQP server and execute actions over queues.
Also, mind the execution order, first purge the queues, second cancel the reserved and scheduled and finally the active tasks.
Final thoughts
As I mentioned at the top of the post, it all depends on how you use the tool and Celery ended up being the right tool, but needed some tweaking. Not using it correctly was nearly as bad as not using it at all. Celery is very complete and loaded with many features, you need to learn them and you will get the most of the tool.

Wondering how AI
can help you?

Terms and Conditions | © 2026. All rights reserved.