

Top 5 tips to make your pandas code absurdly fast




If you've ever worked with tabular data, you probably know the process: import the data into pandas, clean and transform it, and use it as input for your models. But when the time comes to scale up and take your code to production, there's a good chance your pandas pipeline starts to break down and runs slowly.
But there's no need to panic! Given our extensive experience handling large datasets and using pandas in over 80% of our projects, Tryolabs has gained valuable insights into making your pandas code run faster.

Tip 1: Vectorize like there’s no tomorrow.
Using vectorized operations eliminates the need to manually iterate through rows.
Tip 2: Iterate like a semi-pro.
When vectorization is impossible, consider looping over the data frame using methods such as list comprehension with zip, lru_cache or parapply.
Tip 3: Embrace NumPy.
To enhance performance, consider working directly with the Numpy array through .to_numpy(); it can provide a significant bump in speed.
Tip 4: Know your dtypes.
Selecting the appropriate dtype is critical for memory and computation optimization.
Tip 5: Long-term storage.
Pandas can read many formats such as CSV, parquet, pickle, JSON, Excel, etc. We recommended using the parquet format, a compressed, efficient columnar data representation.
We'll also explain what can slow your pandas down and share a few bonus tips surrounding caching and parallelization. Keep reading, and you'll become a pandas pro in no time.


The best way to demonstrate the value of our recommendations is to test the techniques with real datasets. If you are curious about the specifics, take a look at the following section; otherwise, feel free to skip it.
Benchmarking setup
We conducted the benchmarks in the following sections on two anonymized data frames from actual projects. And we've made those datasets available to share.
Download the data frames to run the tests yourself.
Please note that depending on your computer's specifications, you may have trouble opening the data frames. The creator of pandas, Wes McKinney, stated that as a rule of thumb, it is recommended to have 5 to 10 times the amount of RAM as the dataset size.
To avoid these issues in running the benchmarks, we used a high-performance desktop computer with a 10-core/20-thread i9 10900K, 128GB of RAM, and a fast SSD running Ubuntu 20.04.
Regarding the software used, we chose Python 3.10, pandas 1.4.2, and pyarrow 8.0.0.
Let’s start with the best tip we have to share.
Tip 1: Vectorize like there’s no tomorrow
Vectorized operations in pandas allow you to manipulate entire data frame columns using just a few lines of code rather than manually looping through each row individually.
The importance of vectorization cannot be overstated, and it's a fundamental aspect of working with pandas. It's so crucial, in fact, that we even created a "catchy" rhyme to remind ourselves of its importance: "Hector Vector is a better mentor than Luke the for loop." In all seriousness, however, pandas lives and breathes vector operations, as should you. We strongly recommend you embrace vectorization and make it a core part of your pandas workflow.


How does it work?
A key element of vectorized operations is broadcasting shapes. Broadcasting allows you to manipulate objects of different shapes intuitively. Examples are shown below.

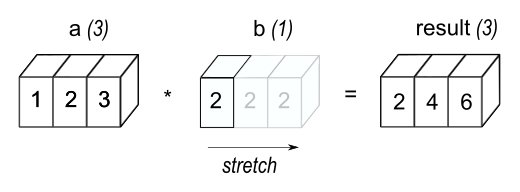

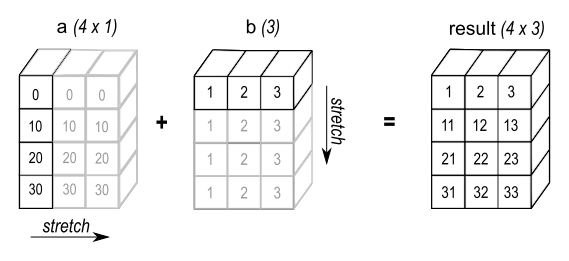
Much has been written about this (including these articles about NumPy Optimization and Array Programming with NumPy), and it's essential in deep learning, where massive matrix multiplications happen all the time. But we'll limit ourselves to 2 short examples.
First, imagine you want to count a given integer's occurrences in a column. Below are 2 possible ways of doing it.
In testing df1 and df2, we got a speedup of just 82x by using the count_vectorized method over the count_loop.
Now say you have a DataFrame with a date column and want to offset it by a given number of days. Below, you’ll find two ways of doing that. Can you guess the speedup factor of the vectorized operation?
By using vectorized operations rather than loops for this costly operation, we got an average speedup of 460x!
One small note on the offset_loop function: we construct d outside the list comprehension. Otherwise, it would get built in each iteration, which would double its runtime (this is noteworthy in its own right).
But you get the point, vectorized operations in actual data are a lifesaver. Remember, it isn't the few microseconds you can shave off a single operation that counts; the total time saved over multiple operations makes the difference. This can take a pipeline from "impossible to run" to "runs in a reasonable amount of time.”
Now that you know how vectorized operations can significantly improve your code's performance, it's time to implement it. Look at your current projects and see where you can apply this technique. You may be surprised at how much of a difference it can make in speed and efficiency.
Although vectorized operations in pandas are highly recommended for optimal performance and efficiency, it's important to note that not all operations can be vectorized, and there may be instances where alternative methods, such as iteration, will be necessary.
Tip 2: Iterate like a semi-pro
You might be wondering why you’re not able to iterate like a fully-fledged pro. The answer is simple: pros vectorize and rookies iterate.


We know it’s not that simple in practice. You can’t vectorize all operations all the time, but hear us out: whenever you can, vectorize ruthlessly; you’ll thank yourself later.
There will be times when there’s no alternative to looping over the millions of rows in a data frame. You may choose to perform these complex operations yourself or solicit help from an external service. Whatever the case, we’ll go through various iteration methods.
Key takeaways:
- Vectorize if possible.
- Use a list comprehension with
zip. - Look into
lru_cacheif your columns have several repeats. - Look into
parapply.
The benchmark
We’ll apply the following function to the datasets:
It removes all the words appearing in the phrase words_to_remove from the given remove_from phrase and eliminates HTML tags while keeping the words with a length greater than or equal to min_include_word_length.
Think of remove_from as a long description from which you want to remove some words that already appear in another data column.
For instance, say you have the following data frame:
Applying remove_words to all rows would result in the following list:
for loops
The first and most intuitive way to iterate would be to use a Python for loop.
There’s overhead everywhere: accessing single values of df and dynamically creating a list with append mean this will be the slowest method and we’ll use it as our baseline for comparison. But you want to avoid this at all costs.
apply
An easy next step would be to use pandas' apply method, which handles the looping internally. You’d expect this to be blazing fast, but it’s only about 1.9x faster than baseline. The code is below. But because better methods are readily available, you should avoid this as well.
In each iteration of df.apply, the provided callable gets a Series whose index is df.columns and whose values are the row’s. This means that pandas has to generate that series in each loop, which is costly. To cut the costs, it’s better to call apply on the subset of df you know you’ll use, like so:
This simple tweak makes the operation 2.1x faster than the baseline, but we’d still recommend avoiding this method.
list-comp + itertuples
Using itertuples combined with the beloved list comprehension to iterate is definitely better. itertuples yields (named) tuples with the data on the rows. Notice that we subset df again. This is, on average, 4.6x faster than baseline.
list-comp + zip
A slightly different approach that yields about the same performance (4.6x faster than baseline) is to use a list comprehension again but iterate over the desired columns with zip. zip takes iterables and yields tuples where the i-th tuple has the i-th element of all the given iterables in order. This approach looks like this:
list-comp + to_dict
A slower variant of this approach is to use to_dict(orient="records") to iterate over dicts of rows of the dataset. This is about 3.9x faster than the baseline. It was achieved using the following code:
This is not a hard rule but, from observation, we determined that using to_dict almost tripled the memory footprint of our program, so be judicious when using it.
Bonus method 1: caching
In addition to the iteration techniques we've discussed, two other methods can help improve your code's performance: caching and parallelization.
Caching can be particularly useful if your pandas function is called multiple times with the same arguments. For example, if remove_words is applied to a dataset with many repeated values, you can use functools.lru_cache to store the results of the function and avoid recalculating them each time. To use lru_cache, simply add the @lru_cache decorator to the declaration of remove_words, then use your preferred iteration method to apply the function to your dataset. This can significantly improve your code's speed and efficiency. Take, for example, the following code:
Adding this decorator produces a function that "remembers" the output for inputs it previously encountered, removing the need to run all the code again. You can read more about it in Python's official documentation here. Don’t forget to play with the maxsize parameter to explore the speed vs memory tradeoff.
You may notice that the cached function’s performance for df1 is similar to its non-cached counterpart. This goes to show that caching isn’t the be-all and end-all. In our case, df1's structure doesn’t have as much repetition, so caching doesn’t help as much as it does fo df2 where the speedup is 46x.
Bonus method 2: parallelization
The last ace up our sleeve is using pandarallel to parallelize our function calls across multiple independent chunks of df. The tool is easy to use: you simply import and initialize it and then change all your .applys for .parallel_applys.
In our case, we measured an 12-fold improvement.
However powerful, parallel_apply is no silver bullet. It pickles each chunk of the df into /dev/shm (which is effectively RAM); therefore, you might run out of memory!
If this happens, you can limit pandarallel's memory usage by initializing it with fewer processes, which will also impact performance.
Why not combine both? Well, we tried and saw no practical benefit. It either went as fast as bare parallel_apply or slower than a bare list comprehension with cache. This might have something to do with how parallelization is achieved and the fact that the cache might not be shared. However, we would need to pursue our investigation further to draw any firm conclusions.
Results
A summary of the results is shown below:
| Description | df1 | df1 | df2 | df2 |
|---|---|---|---|---|
| Description | Time [s] | Speedup | Time [s] | Speedup |
| loop | 546.6 | 1 | 245.9 | 1 |
| apply | 289.3 | 1.9 | 135.7 | 1.8 |
| apply (only used cols) | 263.9 | 2.1 | 121.7 | 2.0 |
| itertuples (only used cols) | 116.1 | 4.7 | 54.7 | 4.5 |
| zip (only used cols) | 115.6 | 4.7 | 54.2 | 4.5 |
| to_dict (only used cols) | 137.8 | 4.0 | 64.0 | 3.8 |
| cached zip (only used cols) | 118.1 | 4.6 | 5.3 | 46.4 |
| parapply (only used cols) | 44.5 | 12.3 | 19.3 | 12.7 |
| cached parapply (only used cols) | 45.5 | 12.0 | 10.6 | 23.2 |
Remember to use the above tips to optimize performance when iterating with pandas in the future.
Tip 3: Embrace NumPy
Pandas is built on top of NumPy, which is known for its performance and speed in handling large arrays and matrices of numerical data. This helps make pandas efficient and fast when working with large datasets. Now that you’re an expert in vectorizing operations embracing numpy is a natural next step. This section is short and sweet: if you need a bit of extra performance, consider going down to numpy by using .to_numpy() and the numpy methods directly.
Benchmarking this method is close to impossible. Results will vary wildly between the use case and the implementation details of your code. In our tests, we observed speedups from anywhere between 2x to an absurd 3000x.
Continuing with the above examples, what if we tried counting or offsetting directly in numpy? Have a look at the following code:
As you can see, it’s easy to accomplish: add .to_numpy() and use numpy objects. Regarding the count, this gives a total 185x speedup (2.2x over the vectorized pandas method). In regards to the offset, this gives a whopping 1200x speedup over the loop operation.
We hear you! These numbers are somewhat artificial because no one in their right mind would offset a day column like this. But this may happen to beginners familiar with other programming languages, and these examples should serve as a cautionary tale.
These speedups are made possible by compounding the benefits of vectorization and the direct use of numpy. This also eliminates the overhead added by pandas' killer feature set.


Be warned that sometimes this isn’t as simple as placing .to_numpy() after each series in your operation. Case in point: a team member reported that using.to_numpy() in datetime data with timezones actually dropped the timezone. This should be fine if all the data is at the same timezone and you’re calculating differences. Still, it’s something to keep in mind.
Another team member experienced some weirdness with dates as well. When calling .to_numpy() on a Series of date times, they would get an array of datetime64[ns]. However, when calling .to_numpy() on a single pd.Timestamp, an int was returned. Hence, trying to subtract a single date from an array of dates will return gibberish unless you do .to_numpy().astype(int).
Given these speedup factors and despite its caveats, you want this tool in your arsenal, and you shouldn't hesitate to use it.
Tip 4: Know your dtypes
In pandas DataFrames, the dtype is a critical attribute that specifies the data type for each column. Therefore, selecting the appropriate dtype for each column in a DataFrame is key.
On the one hand, we can downcast numerics into types that use fewer bits to save memory. Conversely we can use specialized types for specific data that will reduce memory costs and optimize computation by orders of magnitude.
We’ll talk about some of the most prevalent types in pandas, like int, float, bool, and strings. But first, here’s a a primer on the dreaded object.
The object type
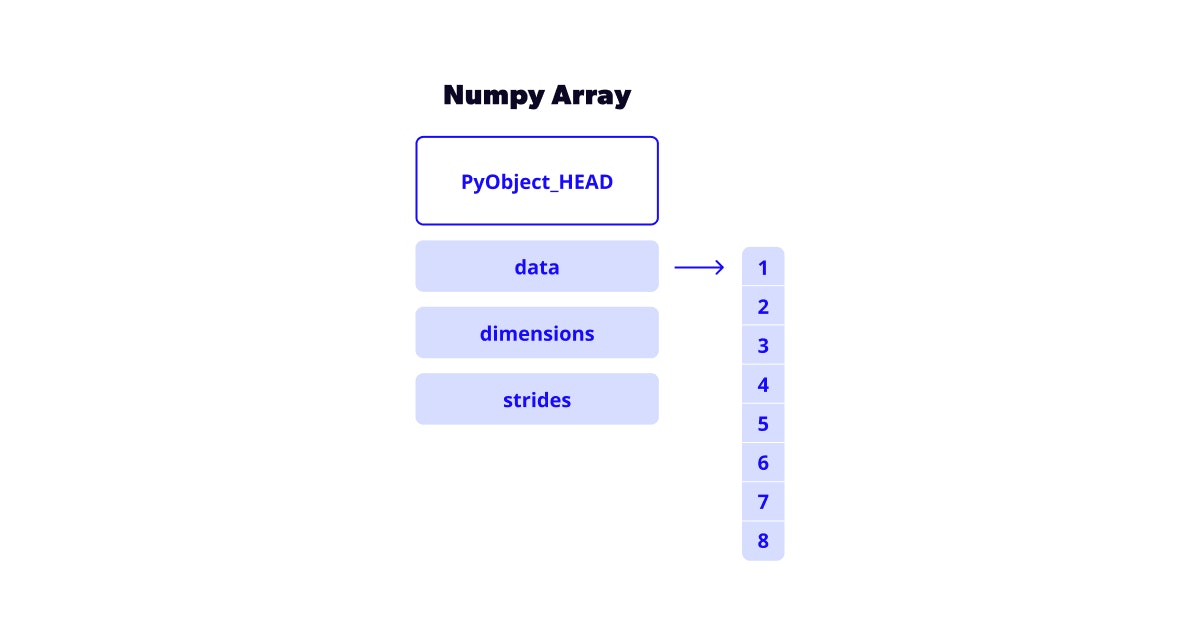
Regarding datatypes, pandas has many types that efficiently map to numpy types at the fast C level. However, when there’s no easy mapping, it falls back on python objects. For the uninitiated, object is the parent class of all objects in the language [source]. This leads to inefficiencies due to how memory is handled.


The fact that numpy's core is written in C means that an array points directly to all its values located in a contiguous block of memory. This allows for much faster execution time as the cache memory can leverage the spatial locality of the data. You can read more about it here.

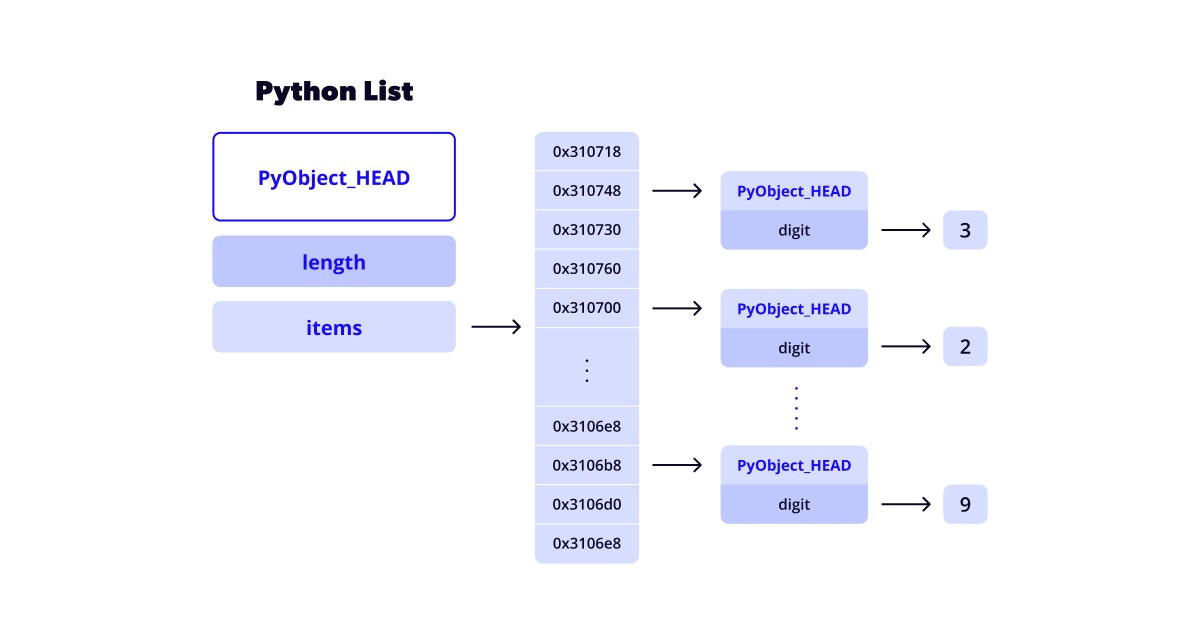
Because pandas stores strings as an array of objects, it has to fall back on slow Python arrays. In contrast to numpy, a Python list has a pointer to a memory-contiguous buffer of pointers, which point to objects stored in memory, but which also reference data stored in other locations. Hence, accessing this data during runtime will be quite slow in comparison.

In a nutshell, pandas is constrained in part by the ecosystem. But how can we make the best of the tools we have right here, right now? Well, it’s a different story for numerical and string data.
Numerical types
Regarding ints and floats, downcasting is the key to saving memory. Pandas supports 8, 16, 32, and 64-bit signed and unsigned integers and 16, 32, and 64-bit floats. By default, it opts to use 64-bit variants for both types.


The trick is to choose the smallest type that can comfortably hold your data. You should consider both current and new valid data. You don't want to limit yourself to unsigned ints in your pipeline if signed ints are a real possibility.
In practice, and for your current dataset, you can easily do this with pandas' own pd.to_numeric like so:
Just like that, we reduced df's size by 1/3. But your mileage will vary based on your data. As a side note: pd.to_numeric only downcasts floats to float32, it doesn’t use float16 even though it is compatible with pandas.
Regarding data types, we found that bool should be favored if you have no nulls. It occupies the same amount of memory as an uint8 , but makes the column’s content much clearer.
“What if I have NaN values?” We hear you. In principle, you can cast your ints and bools to float32 and call it a day. You’ll take a memory hit, but NaNs will be handled natively.
Somewhat recently, pandas has added its own Nullable integer and Nullable boolean data types. They can be more memory efficient than float32 but with the caveat that neither .values nor .to_numpy() return correct numpy arrays with np.nan (because it is itself a float, not an int). Internally, these arrays hold a _data array with the appropriate numpy dtype and a _mask, where True means that the value in _data is missing. This can be an issue if you’re trying to use numpy. The latter and their experimental nature are why we can't fully recommend their use for now.
This is also why we don’t recommend using .convert_dtypes just yet because it uses nullable types.
String types
With numbers out of the way, let's dive into strings. Strings are used everywhere, but they're the bane of our existence when manipulating data. As mentioned before, they're stored with the inefficient object type, and that's why they use lots of space and are slower than more specialized types.
But there’s a glimmer of hope with StringDType. Like the other nullable types we mentioned, StringDType is still experimental, so we don't recommend using it in production code for now. Looking ahead, it promises correct handling of missing values and performance improvements over object.


If your column has low cardinality (many repeated values), the smartest move will be to use pd.Category. nternally, a categorical column holds a mapping from the actual column value (i.e., the contents of your column before conversion) to some arbitrary integer. Then, the column is saved as an int type, exploiting the advantages of contiguous memory and efficient storage. Furthermore, Run Length Encoding is used to reduce the storage size even further (if an integer is repeated, it only saves the integer and the number of instances rather than all the integers).
This results in excellent compression and processing speed, as seen in the results subsection.
Results
Now that you have a better understanding of the different dtypes and their efficiency, let's look at some of the tests we ran and their results:
- We tried using pandas'
convert_dtypesin bothdf1anddf2. - We ran a custom
convert_dtypesthat doesn’t use pandas' nullable types. - We converted applicable string columns into categoricals.
- We downcasted numeric types into their smaller types.
Of course, these results will vary according to your data, but we wanted to highlight the benefits of choosing the correct data type. Here are the results in table form:
| Description | df1 | df1 | df2 | df2 |
|---|---|---|---|---|
| Description | Size [GB] | Ratio | Size [GB] | Ratio |
| Size on RAM (unoptimized) | 24.8 | 1 | 12.0 | 1 |
| pandas' convert_dtypes | 24.9 | 1.004 | 12.5 | 1.04 |
| Our convert_dtypes | 24.7 | 0.996 | 12.6 | 1.05 |
| Convert to Category | 13.8 | 0.556 | 2.3 | 0.19 |
| Downcasting | 12.5 | 0.504 | 1.7 | 0.14 |
We managed to reduce the dataset size to about 1/2 and 1/8, respectively, as soon as pandas finished loading it.
This is important because we can now process the data in more ways than before simply because we have more free RAM. And our entire system will likely be snappier as well.
Also note that pandas' convert_dtypes enlarges the dataset in both cases.
Again, you might be asking, why bother with convert_dtypes if it barely saves any memory?” Or, for that matter, how come these people always know the questions I’m about to ask? Well, our job is to predict the future, so we've gotten quite good at it. And we're glad you asked because the speed improvements completely dwarfed the memory reduction benefit. Try running the following code to compare your times:
With our data, we saw speedups of between 12x to 50x. For the mean, the speedups were 12x to 25x. For the standard deviation, they were 20x to 50x. For value_counts, they were about 15x. That’s not bad for such a small amount of work!
Categoricals, in particular, reap the benefits twofold. Not only is the memory usage reduction reason enough to use them, but they make operations (like groupby or str.lower()) much faster. Notably, .str.lower() was about 22.5x faster on categorical columns than on regular object columns (or StringDType columns for that matter).
groupbys are another can of worms. In our testing, when grouping with 1 column, categoricals were about 1.5x faster. However, when grouping with multiple columns, where at least one of them is categorical, pandas defaults to creating an index that is the cartesian product between all categories in said columns. You can imagine how this explodes in size and complexity quickly.
But don’t despair. There’s a solution! Okay, you can despair just a little because the solution isn’t a catch-all. Some categories are mutually exclusive; therefore, their combination, which would appear in the cartesian product, would never be observed in the data. You can use the observed=True kwarg of groupby to instruct pandas to execute the operation in this way.
IIn our tests, we measured a 2.5x speedup using observed=True , while we got a slowdown of about 2x when we didn’t. If you notice this doesn’t work well for you, converting to object, performing the groupby, and converting back to categorical could be the way to go.
Tip 5: Long-term storage
CSV, parquet, pickle, JSON, XML, HDF5, Feather, ORC, STATA, SAS, SPSS, or, dare I say it, Excel (yuck!) are some of the formats that pandas supports. Argghhh! There are too many options! How are we supposed to choose?
We might start, as any responsible engineer would, by reviewing the pros and cons of each format. We’d then test a few that stand out in the real world and come to some conclusion about which format we’d favor and when. Life is tough, though, and with looming deadlines imposing time constraints, the selection process looks more like this:
Fear not! We've done our homework - and we promise that our method is more scientific than Homer's. We recommend you take a good look at parquet. You don't need to constantly be making these decisions anymore.
Parquet was created to help developers reap the benefits of a "compressed, efficient columnar data representation." It supports different encodings and can compress on a per-column basis. That fits the ML practitioner's use case like a glove!
It sounds awesome; sign me up! Right? Go on, try to do a simple df.to_parquet. I’ll wait…
Already back? Did you get an ImportError? Parquet is technically a format, which is more like a spec than an implementation. So, to use it, you need to install another library that implements the format. Currently, pandas supports pyarrow and fastparquet.
But you promised no more decisions! Well, we believe pandas’ use of pyarrow by default is the right choice. We found it to be more reliable than fastparquet. For example, when trying to save and then immediately read df2, fastparquet complained about an overflow.
Below is a table with read/write durations and the resulting sizes of the datasets saved in different ways (with pyarrow). It boils down to this: use parquet and change the compression method to fit your needs. Uncompressed or snappy parquet ought to be your choice during development, resorting to gzip compression for long-term archival.
| Description | df1 | df1 | df1 | df2 | df2 | df2 |
|---|---|---|---|---|---|---|
| Description | write [s] | read [s] | size [GB] | write [s] | read [s] | size [GB] |
| pickle | 17.7 | 9.9 | 6.5 | 0.9 | 0.6 | 1.3 |
| pickle gzip | 532.2 | 40.1 | 3.8 | 99.8 | 3.0 | 0.2 |
| pickle lzma | 2670.5 | 158.0 | 3.2 | 187.9 | 7.7 | 0.1 |
| pickle bz2 | 455.3 | 218.1 | 3.5 | 127.9 | 19.5 | 0.2 |
| parquet | 22.3 | 16.0 | 6.4 | 3.6 | 1.3 | 0.4 |
| parquet gzip | 299.5 | 24.7 | 4.0 | 21.5 | 1.5 | 0.2 |
| parquet snappy | 25.5 | 15.5 | 5.9 | 4.0 | 1.3 | 0.3 |
CSV is probably in the top 5 data distribution formats, and that's in part thanks to its ease of use. With a simple df.to_csv, you can create a file that anyone (and their dogs) can open in the program of their choice. But, and that's a big but, CSV is severely limited in terms of volume, size, and speed. When you hit these limitations, it's time to start exploring parquet.
The latest pickle version is fast but has substantial security and long-term storage issues. The words "execute arbitrary code during unpickling" should send shivers down your spine, and those are the exact words in the massive, red warning in pickle's official documentation.
You might think, "well, that's a non-issue; I'll only unpickle stuff I've
pickled," but that won't save you either. When unpickling, the object's definition at that time is used to load it from storage. That means that if your objects change, your pickles could break. In the example below, which raises an AttributeError, we show how removing an attribute from class C after saving the pickle results in the loaded object losing the attribute despite it being there when it was saved.
Now imagine pandas changes something in the DataFrame class. You might run into issues when unpickling older DataFrames. Favor (uncompressed) parquets over pickles to avoid this.
We recently came across a tool called Lance that aims to simplify machine learning workflows. It supports a columnar data format called Lance Format, which claims to be 50 to 100 times faster than other popular options such as Parquet, Iceberg, and Delta. Although we have yet to thoroughly test it, the potential speed increase is intriguing, and we encourage you to give it a try.
Conclusion
Phew! That was a loaded blog post, full of insights and valuable information. We hope you apply some of these tips in the real world and supercharge your codebase to be faster and more powerful.
Here are some of the key concepts to keep in mind:
- Python’s dynamic nature makes it slower than compiled languages. This issue is exacerbated in scientific computing because we run simple operations millions of times.
- Don’t loop over your data. Instead, vectorize your operations (remember Hector Vector).
- You can use
numpydirectly by calling.to_numpy()on the Dataframe, which can be even faster. - Choose the smallest possible numerical dtypes, use categoricals, and prefer
float32over the newish nullable dtypes (for now). - Use parquet to store your data. Use
snappycompression (or none at all) during development, resorting togzipfor long-term archival.

Wondering how AI
can help you?

Terms and Conditions | © 2026. All rights reserved.