

MLOps: The strategic compass for AI-driven enterprises




As Artificial Intelligence (AI) continues to revolutionize industries and redefine operational strategies, the challenge emerges: how can enterprises efficiently deploy, manage, and scale these AI solutions? Navigating the intricacies of AI development and deployment can be a daunting task. This is where MLOps shines. Merging the best of Machine Learning with operational practices, MLOps is more than just a technical methodology—it's the strategic compass for AI-driven enterprises. In this exploration, we'll delve into the significance of MLOps, highlighting its pivotal role in translating the vast potential of AI into tangible business results. Embark with us on this illuminating journey.
Why MLOps is Crucial for AI-Driven Organizations
AI promises transformative power. From automation to predictive analytics, its potential applications are vast and varied. But harnessing that power in a way that aligns with business goals requires more than just stellar algorithms or accurate models. It requires a structured process that integrates AI advancements seamlessly into an organization's workflow. This is where MLOps comes to the fore.
Connecting AI Objectives with Business Ambitions
Before delving deep into the technicalities, it's paramount to understand the bigger picture: How does AI align with the overarching business objectives? Think of AI as the engine and MLOps as the steering wheel. While AI powers the drive, MLOps ensures the journey is in the right direction, aligning with the destination, the organization's business ambitions.
With MLOps, organizations can:
- Establish clear metrics that tie AI performance to business outcomes.
- Streamline the feedback loop, ensuring AI developments continually cater to evolving business needs.
- Foster collaboration between data scientists and business stakeholders, ensuring both are on the same strategic page.
Ensuring reproducibility, efficiency, and speed of AI deployments
MLOps isn't just about direction; it's also about efficiency and momentum. As AI-driven solutions scale, ensuring consistent performance becomes a challenge. Variability in data, environmental conditions, and deployment platforms can introduce unintended consequences or inefficiencies.
Key benefits of MLOps in this arena include:
- Reproducibility: With standardized processes and environments, models can be deployed and re-deployed consistently, ensuring stable performance over time.
- Efficiency: MLOps introduces practices like automated testing and continuous integration, minimizing manual interventions and reducing the chances of errors.
- Speed: Through streamlined pipelines, AI solutions can be swiftly moved from development to deployment, ensuring businesses can rapidly capitalize on AI insights and advantages.
In essence, MLOps serves as the bridge between the dynamism of AI and the structured ambitions of business enterprises. It's the linchpin ensuring AI doesn't just operate in a vacuum but is intricately and strategically tied to the broader organizational tapestry. By instilling reproducibility, efficiency, and speed into AI deployments, MLOps ensures that AI-driven organizations are not just running, but running in the right direction, at the right pace.
The MLOps Journey: Key Stages Explained


Stage 1: Getting your Data in order
The first step of any MLOps journey starts at the heart of every Machine Learning project: the data. Quality data is the foundation of successful AI, and initial efforts to enhance its usability can drastically boost the efficacy of your Data Science teams.

Common data challenges:
- Lack of centralization: Data dispersed across numerous databases creates a barrier to efficient data integration and interpretation.
- Poor data quality: Unreliable datasets plagued with missing values, free-text categorical descriptors, and other basic issues compromise the validity of results.
- Lack of documentation: Without a centralized repository detailing data specifics, teams over-rely on the tacit knowledge of seasoned members to navigate the data maze.
- No reusability: If each model requires unique SQL queries and lacks standard preprocessing, the wheel is being reinvented every time – an inefficient and error-prone process.
Strategies for Data enhancement:
- Centralization: Use a Data Warehouse like BigQuery or Snowflake to consolidate data. When this isn't viable, Data Catalogs like Alation, Amundsen, or AWS Glue can provide an organized directory of information across services.
- Data quality improvement: Regular manual checks by Data Scientists can flag potential issues. Open communication channels between data creators (typically Engineering and Data Engineering teams) and consumers (like Data Science teams) allow for collaborative issue resolution.
- Prioritize documentation: Data documentation is as pivotal as code documentation. Templates like Datasheets for Datasets, the Aether Data Documentation Template, or Data Nutrition Labels offer frameworks to record essential data characteristics and provenance.
- Promote reusability: Encourage shared, stored queries. While a simple .sql file in a repository might suffice, creating views in your Data Warehouse can be even more beneficial. Regularly allocate time for team members to generalize and share these queries. Aim to shift data cleaning to the ETL phase, providing tables with pre-cleaned data.
Although vital, this blogpost doesn't delve into data security, compliance, and user privacy. However, mastering these foundational data steps allows for progressing to more intricate facets of your MLOps infrastructure.
Stage 2: Experiment and model tracking
As data teams progress from ensuring data quality and usability, the next pivotal stage in the MLOps journey is experiment and model tracking. This stage revolves around the systematic documentation, monitoring, and management of experiments and models. But why is this process so essential, and what challenges might one face?
Challenges in experimentation:
Difficulty reproducing results: Without structured tracking, re-creating experiments to achieve the same results becomes a maze. Losing track can translate to lost time, effort, and critical insights, acting as significant hindrances.
Collaboration barriers: The absence of a centralized system can lead to disjointed team efforts. Imagine multiple data scientists working independently on their Jupyter notebooks without versioning, causing a significant overlap and rework.
Inefficient experimentation: Tracking the myriad of experiments, understanding their outcomes, and discerning the reasons for their success or failure can get chaotic. An unorganized approach can slow down the experimentation process considerably.
Inability to track model performance: Choosing the best model becomes an uphill task when there’s no systematic way to compare the performance metrics of different models.
As organizations scale, these challenges can snowball, leading to considerable bottlenecks and stymied development. However, addressing these issues head-on can smooth out the workflow significantly.
Solutions and approaches
- Standardized experimentation environment: The foundation lies in ensuring that the entire Data Science team operates in a standardized setting. Tools like pyenv coupled with poetry or pip-tools can aid in managing Python dependencies. Moreover, integrating Docker into the workflow helps create containerized environments, making them shareable and consistent across various stages.

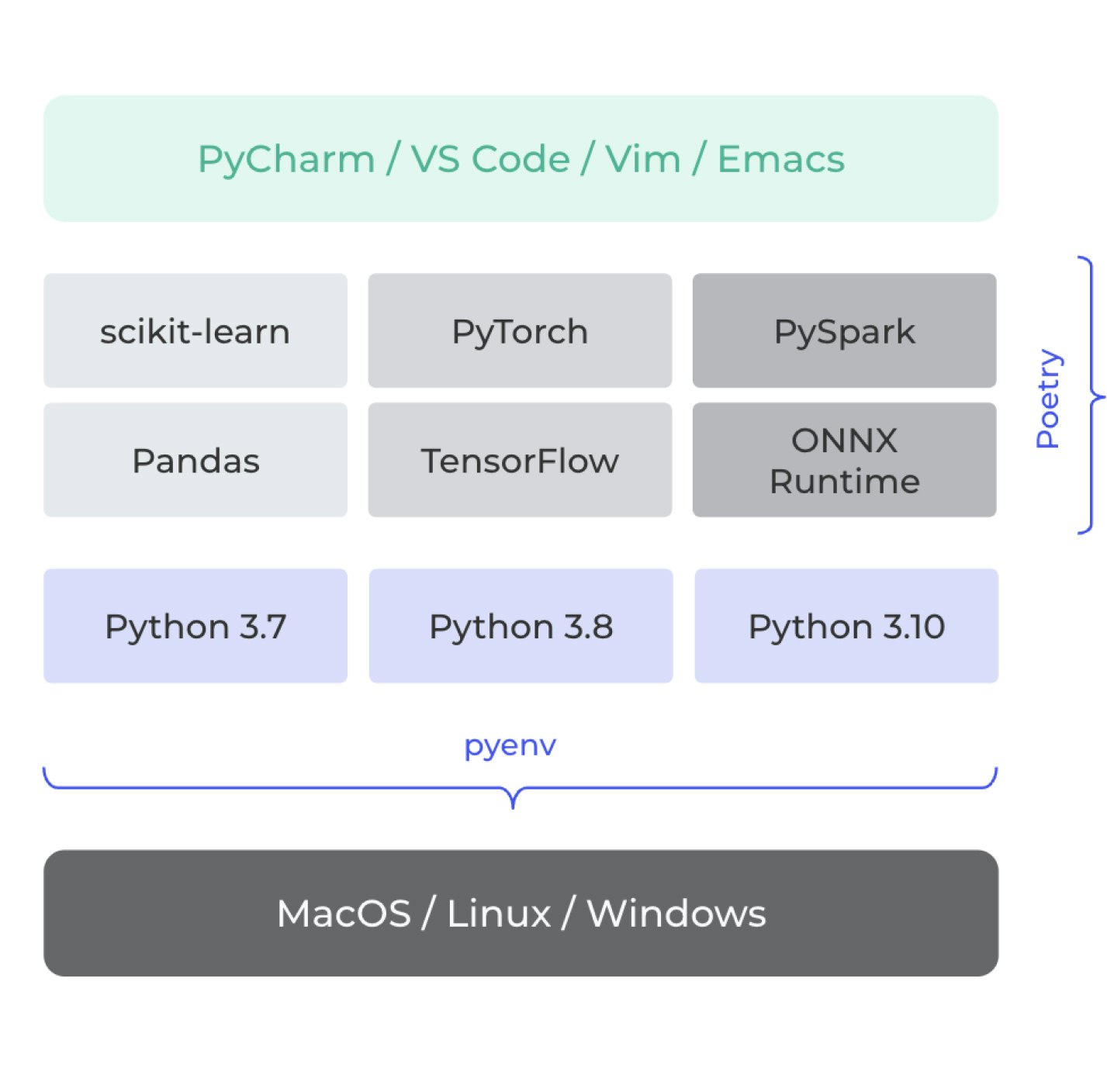
- Embrace experiment tracking tools: Tools dedicated to tracking experiments can be game-changers. They meticulously document everything from hyperparameters and input data to performance metrics, enabling data scientists to draw comparisons, spot trends, and assimilate learnings from past experiments. Examples of experiment-tracking tools include Weights & Biases, Comet ML, Studio by Iterative.ai, and even TensorBoard. You may also track your experiments directly on GCP Vertex AI or AWS SageMaker Experiments features.
- Adopting a model registry: Think of a Model Registry as a centralized library for your trained models. Such a registry helps streamline model lifecycle management, making collaboration a breeze and ensuring that insights and models are retained and not lost in the shuffle. While GCP Vertex AI and AWS Sagemaker offer built-in registry capabilities, they often require a custom interaction layer to suit specific organizational needs.
In this stage, the importance of structured and systematic tracking of experiments and models cannot be understated. Adopting the right tools and practices ensures that the organization can scale its Machine Learning efforts without getting entangled in its own web of experiments.
Stage 3: Standardizing production process
Upon streamlining data quality and ensuring a well-documented trail of experiments and models, teams often hit a new roadblock: transitioning models from proof of concept to production swiftly and efficiently.
Production challenges
- Lack of reusable code: Every model's deployment seems like reinventing the wheel, with custom code and infrastructure required every single time.
- Maintainability concerns: Ensuring active models function flawlessly in production becomes a challenge with the increasing complexity of code and infrastructure.
- Delay in deployment: The gap between acknowledging a model's efficacy and its first live prediction in production feels extended and cumbersome.
To swiftly navigate these challenges, the key lies in consistency in development environments and strategic model-serving approaches.
Model serving approaches
There are two predominant methods for serving Machine Learning models. These methods, each with its own unique approach, are integral to the process of making predictions and interpreting results. Let's take a deeper look:
- Batch Predictions: This method involves a series of systematic steps. Initially, scripts or jobs pull data, which is then preprocessed. The model is loaded, predictions are made, and these predictions are diligently stored for future reference.
- Online Prediction APIs: This process is a bit more immediate. The model's raw features are inputted, undergoing only light preprocessing. Predictions are swiftly made, and the results are immediately presented, providing real-time insights.
Guidelines for Model Serving
Instead of reinventing the wheel each time, standard practices streamline the decision-making process concerning model formats, infrastructure, and serving frameworks. Platforms like SageMaker Models (AWS), VertexAI endpoints (GCP), MLFlow Models (Databricks), or NVIDIA Triton offer an almost plug-and-play experience, simplifying model deployment to a few clicks or commands.
Standard Production Environments
One may wonder: how can we align AI models with the plethora of deployment options? The answer resides in the standardization of production environments, a technique that, when correctly mirrored to development environments, can result in notable time and effort savings. The use of dependency managers (examples include poetry and pip-tools) adequately caters to a majority of development needs. However, when transitioning into production, a more robust solution is often required for consistency and predictability. In this respect, Docker stands out as a reliable choice, effectively minimizing unwelcome surprises during deployment.

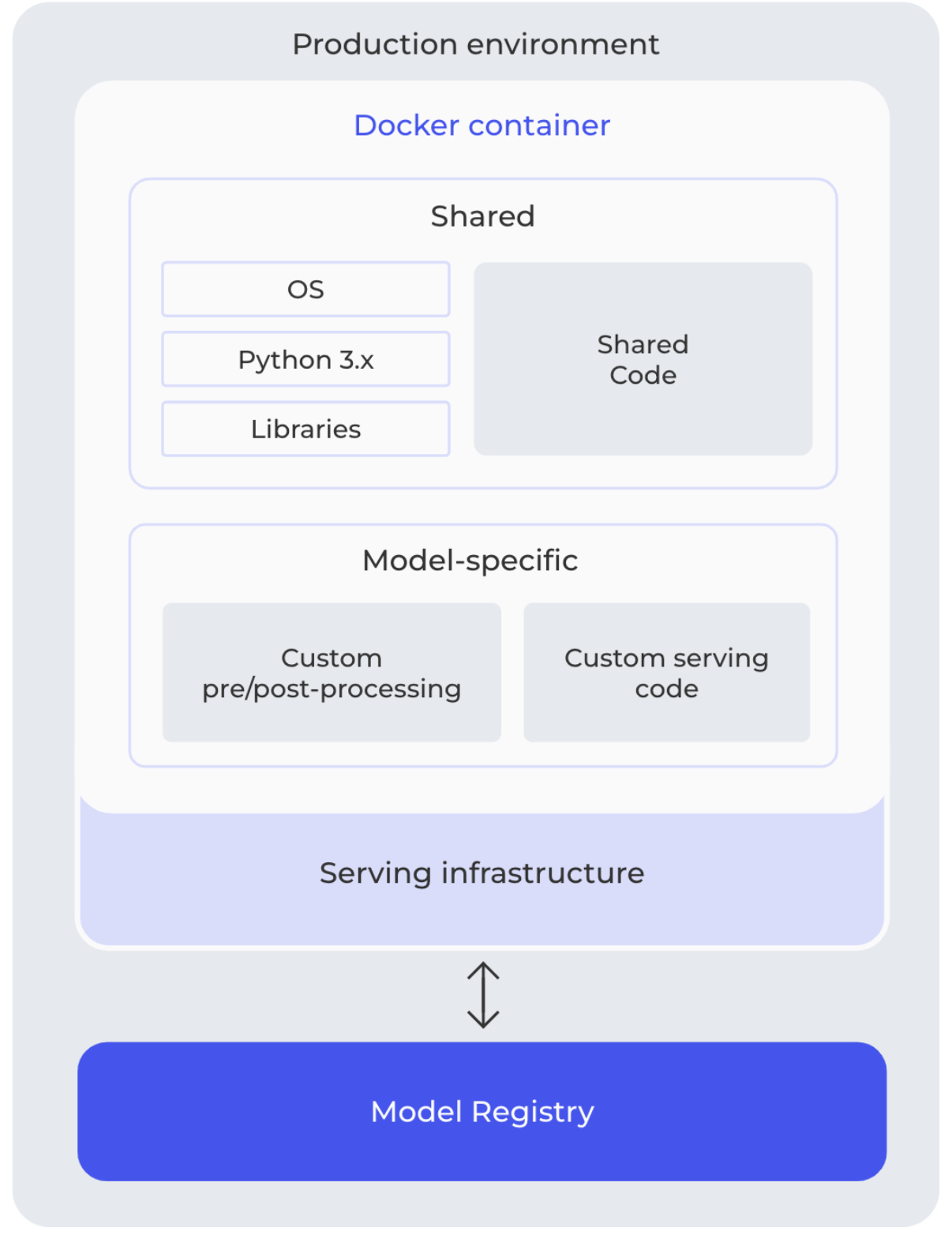
The same way you would use a dependency manager to standardize a development environment, we recommend using Docker for a standard production environment.
Myriad strategies exist to standardize and expedite the transition from PoC to production. Identifying the perfect blend that complements the team's capabilities and the tech stack is pivotal. Prioritizing consistency in both development and production environments ensures that models trained are seamlessly integrated into the standardized serving process.
Stage 4: Model and Data Monitoring
As organizations standardize the serving process of models, the logical next step is scalability. Initially, manual oversight might suffice for monitoring performance, but true scalability demands automation in model and data monitoring. Without this automated vigilance, a model's efficiency can plummet, adversely affecting end-users, oftentimes unbeknownst to the organization until complaints start pouring in.
Recognizing the need for monitoring
- External feedback: Are most of your insights on model performance stemming from external feedback? If so, it’s a red flag. Efficient systems should internally detect and rectify issues before end-users even notice.
- Emerging biases: If the model's outputs display a consistent bias towards specific segments, it's indicative of data bias, which can be a subtle, yet detrimental issue.
- System failures: Just as in traditional software, an ML system's failure should be promptly detected and rectified. Efficient monitoring can be a savior here.
Solutions to consider
- Data monitoring: Data is the lifeblood of models. Monitoring it can preemptively flag issues like data drift, biases, or missing values. It ensures the model's training data remains representative, maintaining the integrity of its outputs. Moreover, detecting shifts in data distribution can hint towards the need for model retraining.
- Model monitoring: This is a continuous process of overseeing key performance metrics, often set in collaboration with stakeholders. Early identification of performance dips or biases allows timely interventions – from retraining to fine-tuning. Furthermore, resource utilization insights can lead to cost optimizations.
- Observability: Beyond monitoring, observability aids in understanding the "why" behind any issues, facilitating quicker resolutions. This includes deep dives into logs, metrics, and system traces.
Generic cloud monitoring and observability tools, such as Datadog, AWS CloudWatch, GCP Cloud Operations, or Azure Monitor, provide broad oversight. Sentry and Bugsnag excel in issue detection and troubleshooting. For specialized ML monitoring, Whylabs stands out, offering in-depth insights for data and ML systems. The beauty lies in the harmonious coexistence of these tools. Instead of choosing one over the other, they can be synergistically integrated to craft a comprehensive monitoring and observability solution.
Take the next step in your MLOps journey
We've only scratched the surface of what's possible in the Data Science ecosystem. Beyond these preliminary stages, a myriad of strategies, nuances, and insights await you, insights that could revolutionize your organization's approach to AI and data.
At Tryolabs, we pride ourselves on being more than mere service providers. We are your partners and your strategic allies on the road to MLOps excellence. Our team, boasting of seasoned experts equipped with extensive knowledge and experience, is committed to ensuring your MLOps journey is smooth, strategic, and successful.
Why trust Tryolabs? Let's delve into what makes us stand out:
- Expertise: Our team comprises seasoned professionals who have honed their skills over years of practice. Not only experts in MLOps, but also in various aspects of Machine Learning, and data science.
- Experience: With a rich and diverse portfolio of complex MLOps projects under our belt, we are adept at navigating and addressing varied challenges.
- Strategic insight: We don't just execute projects, we strategize. We take the time to understand your business, goals, and specific needs, allowing us to provide you with the most effective and efficient solutions.
As your MLOps partner, Tryolabs brings deep expertise, real-world experience, and commitment to guide you every step of the way. We understand the complexities of MLOps and have the solutions to help you succeed.
Ready to start your MLOps journey? Here are 3 ways we can help:
- Immerse yourself in our comprehensive white paper on MLOps. This guide provides actionable strategies on team building, governance, and more. It's the roadmap you need to achieve data-driven excellence. Download the Tryolabs MLOps White Paper now.
- Have questions? Want hands-on guidance? Our experts are ready to advise and accompany you. Reach out to us at hello@tryolabs.com and we'll help make your MLOps implementation smooth and successful.
- Bring the learning to your team with a customized MLOps Talk. Our in-house sessions deliver practical insights to skill up your staff. Book an AI Talk today and let's explore MLOps together.
With Tryolabs as your guide, you don't have to navigate the MLOps path alone. Take the first step now and let our experts help drive your success. The future of AI is bright when we work together!

Wondering how AI
can help you?

Terms and Conditions | © 2026. All rights reserved.