

technical|Jul 17, 2019
Deep in the dark: enhancing malware traffic detection with deep learning


The IEEE Symposium on Security and Privacy (IEEE S&P) is one of the top-tier conferences in computer security and electronic privacy.
This year, the IEEE S&P was held in May, in San Francisco. It was not a regular edition, as this flagship conference marked its 40th anniversary. This year's symposium was a special celebration that included a plenary session with some exceptional panelists from the S&P community, Test of Time awards for papers that have made a lasting impact on the field, and even an amazing birthday cake! 🎂
I had the pleasure of presenting two research papers at two different workshops while at the conference: the Deep Learning and Security Workshop (DLS 2019) and the Workshop on Traffic Measurements for Cybersecurity (WTMC 2019).
Hmmm 🤔... display only?


Both papers were based on my master’s thesis, that I developed for the most part when I was a research intern at the Austrian Institute of Technology (AIT) in Vienna, Austria.
In this post, I will focus on my research paper Deep in the Dark — Deep Learning-Based Malware Traffic Detection without Expert Knowledge, which I presented at the DLS 2019. This paper was based on joint research I did with my supervisors Germán Capdehourat (Plan Ceibal and UDELAR, Uruguay) and Pedro Casas (AIT, Austria).
As suggested by the title of the paper, the work is about using deep learning models to perform malware traffic detection and classification while operating in the dark, i.e. without expert knowledge. Let's see what it’s all about!
Presenting my research on deep learning for malware detection at the DLS workshop.


Machine learning for network security
I’ll start with some background information. Nowadays, network security is a business cornerstone of Internet Service Providers (ISPs), who must cope with an increasing number of network attacks, which put the integrity of the entire network at risk.
Current network monitoring systems provide data with a high degree of dimensionality. This opens the door to the large-scale application of machine learning approaches to improve the detection and classification of network attacks.
In recent years, the use of machine learning based systems in network security applications has gained in popularity. Such use usually consists of incorporating traditional (and shallow) machine learning models, for which a set of expertly handcrafted features is required to pre-process the data prior to training the models.
Such an approach has been widely adopted, and under certain scenarios works well, but — and there’s always a but — it can have some drawbacks.
Firstly, there is a systematic lack of a consensual set of input features to tackle specific tasks. Each paper defines its own set of input features for the application at hand, hindering the generalization and benchmarking of different approaches.
Secondly, networking data is very dynamic and consists of constantly occurring concept drifts, i.e., changes in the underlying statistical properties, meaning static handcrafted features fail over time. The truth is that the feature engineering process is costly; it takes a lot of time and effort to reach a set of features that can work well for a specific issue.
Overcoming limitations with deep learning
To overcome these limitations, we decided to explore the end-to-end implementation of deep learning models to complement conventional approaches to the analysis of network traffic, all while examining different representations of the input data. We chose deep learning for its outstanding performance in multiple domains, including speech recognition, visual object recognition, and object detection and genomics. The key factor is the ability of such models to learn feature representations from raw, non-processed input data.
To fully formulate the problem, we asked ourselves the following three research questions:
- Is it possible to achieve high detection accuracy with low false positive rates employing deep learning based models fed raw input?
- Are the proposed models better than the commonly used shallow models, especially when feeding them raw input?
- How good are these models compared with traditional approaches, when domain expert knowledge is used to build the feature set?
The remainder of this post will seek to answer these questions. Feel free to leave a comment at the end or check out the full paper for further details 😉.
Input representations and datasets
Selecting the input representations for the networking data is one of the first things to address. Don’t forget that we are dealing with network traffic measurements here, so in actuality, several valid choices are possible: full packets, packet headers, packet payloads, unidirectional flows, bi-directional flows, and the list goes on.
The main goal here is to explore the feature representation power of deep learning models given non-processed data. With this in mind, we chose to treat decimal normalized representations of bytes of data of network packets as unique features. Under this scenario, we defined two different input representations: raw packets and raw flows.
In a nutshell, the raw packets approach treats each byte of data of each packet as a different feature, and each packet as a different instance; while the raw flows approach treats every group of data bytes as a different feature, and every group of packets (that conform to the flow) as a different instance. The concept of flow is defined as a group of packets that share the same 5-tuple: source IP, destination IP, source port, destination port, and transport layer protocol. Both representations are depicted in the following figure.
Raw packets input representation.


Raw flow input representation.

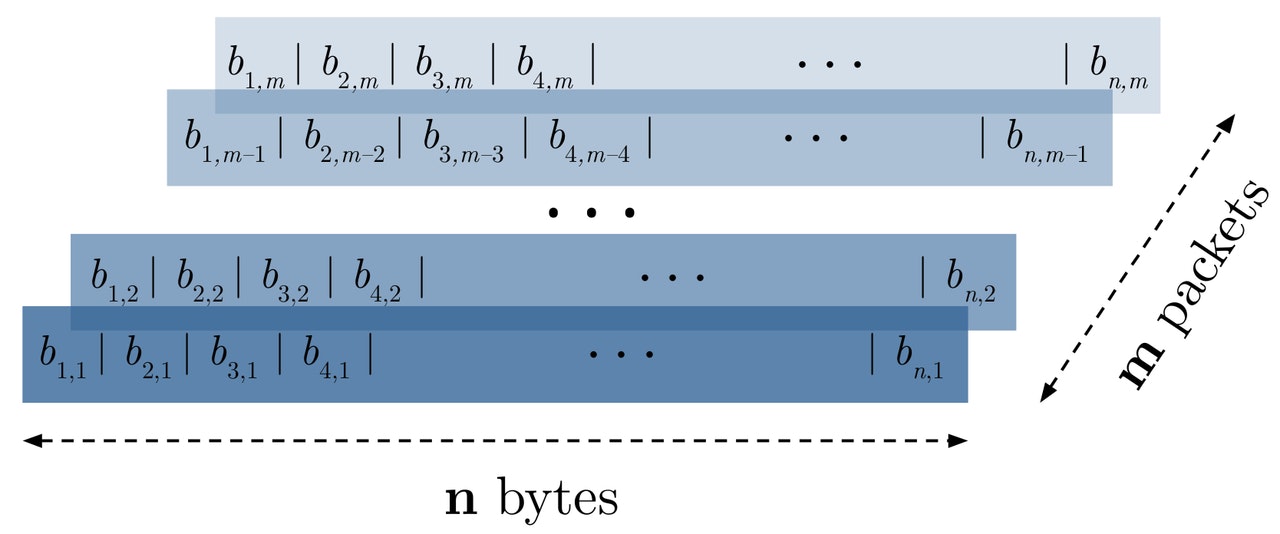
From the pictures above, you can see that there are two different parameters that need to be set: n refers to the number of bytes per packet and m refers to the number of packets per flow. Since both values vary according to each specific sample, we need to fix these two values to build the datasets. We won’t dig into the parameter selection details here, but note that our model shouldn't be dependent on the chosen values.
Spoiler alert: we’ll want to use small values for both parameters, specifically for the number of packets per flow, because we want our model to proactively detect and mitigate malicious flows (say, after one to four packets have been captured). This is known as early traffic classification or traffic classification on the fly. Also note that the value of n does not have to be the same for both representations.
Different from other AI-related domains, where well established datasets are publicly available for testing, evaluation, and benchmarking purposes (e.g. ImageNet for image processing), it is very difficult to find public datasets appropriate for assessing machine learning for networking. One of the main reasons for this is the data’s sensitive nature relating to end-user privacy. Other limitations arise from the grand effort required to build proper and representative networking datasets.
Nevertheless, there are several research groups that have put forth a lot of effort to build representative datasets useful in this field. An example is the Stratosphere IPS Project of CTU University in Prague, Czech Republic. We used malware and normal-labeled captures by this research team to build our versions of the datasets, all while considering the previously mentioned input representations.
Solving the Rubik’s cube: the deep learning architectures
Personally, I wanted to name this section, Solving the Rubik’s cube: the art behind building and training deep learning based models for the future of mankind, but the editor in chief thought it was too long (or maybe too sexy 🤔) for this blog post.
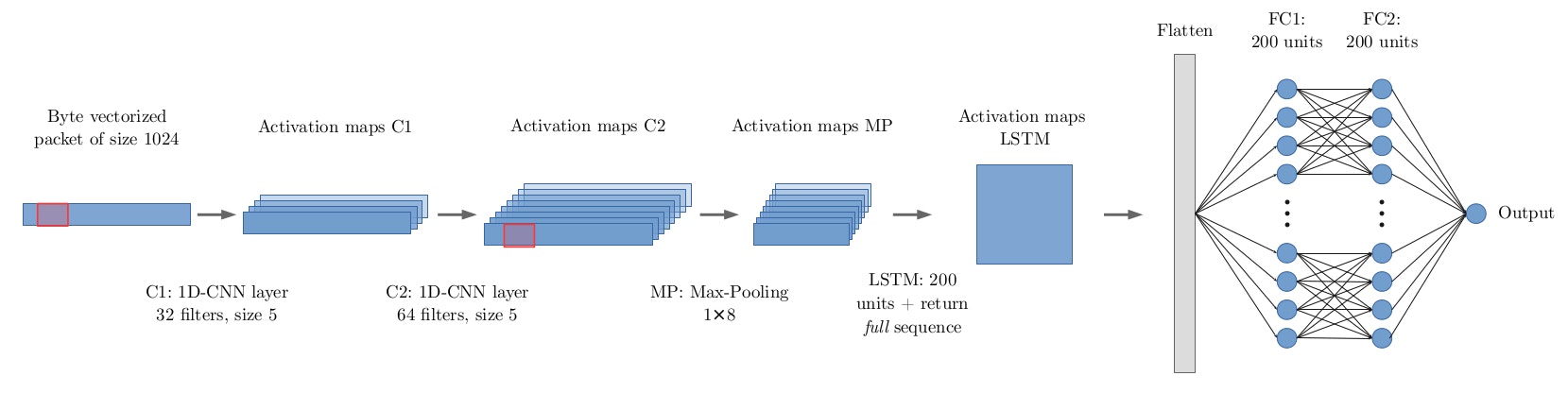
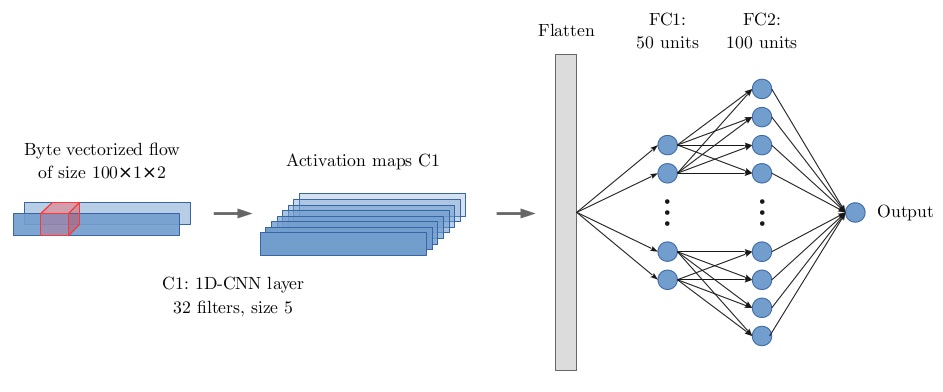
We chose two core layers for both models: convolutional and recurrent. The convolutional layers function to build the feature representation of the spatial data of the packets and flows. This is the principle area in which the model is expected to show improvement over shallow traditional methods.
On the other hand, the recurrent layers are incorporated with the raw packets input representation to improve performance and allow the model to keep track of temporal information.
Additionally, we utilize fully connected layers to address the different feature combinations in order to arrive at the final decisions (i.e., classify). Since the input representation, and dataset size and characteristics, are different, so will be the architectures designed for each model.
The following figures depict both the final raw packets and raw flows deep learning architectures. Of course, coming up with these final architectures was no easy task. The process was iterative and even included some trial and error.
Raw packets architecture.

Raw flows architecture.

A special note regarding hyperparameter optimization: hyperparameters are settings that are not learned by the learning algorithm itself, and therefore must be determined externally.
Deep learning models have several of these, and many of them greatly impact performance. The hyperparameter optimization process can be tedious and must be neat, i.e. modifying one parameter at a time is a must in order to discover what the real impact is on the learning process.
Think about trying to solve a Rubik’s cube. Frequently, when you finish solving one side and move on to the next, some of the minor cube units of the solved side are changed as a result of trying to solve the new one. This analogy applies to the process of optimizing the hyperparameters of deep learning models; you have to be meticulous and organized when modifying the different settings.
Experimental evaluation and results
We performed three different experimental evaluations so as to answer the three research questions mentioned above.
1. Deep learning vs. shallow models with raw input
To begin with, consider a simple evaluation scenario: detecting malware at the packet level. For this problem, the raw packets deep learning architecture was trained on its respective dataset, achieving a 77.6% accuracy given the test set. The figure presents the initial results obtained by this model in the detection of malware packets, in the form of an ROC curve.
We compared the performance of the raw packets model with that of a random forest one trained using exactly the same input features and an internal architecture of 100 trees. We chose the random forest model based on its generally outstanding detection performance in previous work, using domain expert input features. Note that the deep learning model detects approximately 60% of the malware traffic packets with a false positive rate of 6% and outperforms the random forest model by nearly 25%.
Raw packets ROC curve.

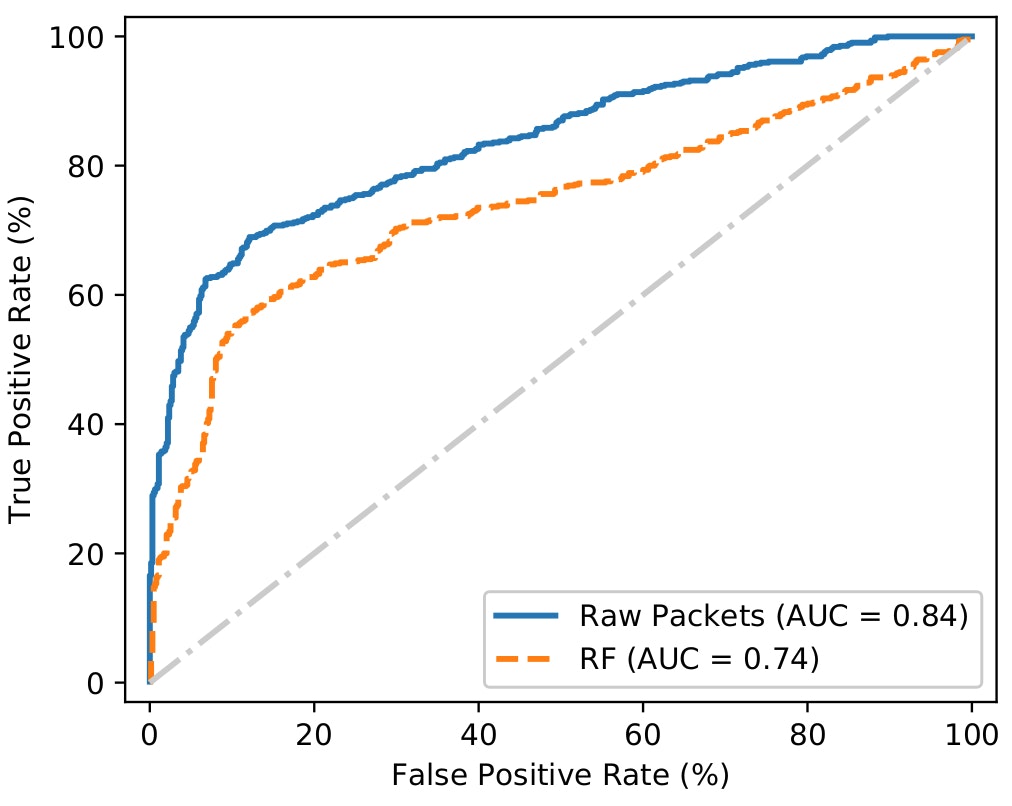
These initial results are highly encouraging, as they demonstrate the deep learning based model’s capacity to better capture the underlying details of the malware without requiring any specific handcrafted feature set.
However, the overall detection rate results are still not good enough to rely on such a deep learning model for malware detection with raw packet inputs in practice.
2. Packet vs. flow representation performance
Next, we go one step further by taking the raw flows representations as the input. Under this scenario, a 98.6% accuracy rate was achieved. Similar to before, the figure compares the detection performance of this model against a random forest model using exactly the same raw input features. In this case, the data was flattened to fit the input into the random forest. Once again, the deep learning architecture clearly outperformed the random forest model.
Raw flows ROC curve.

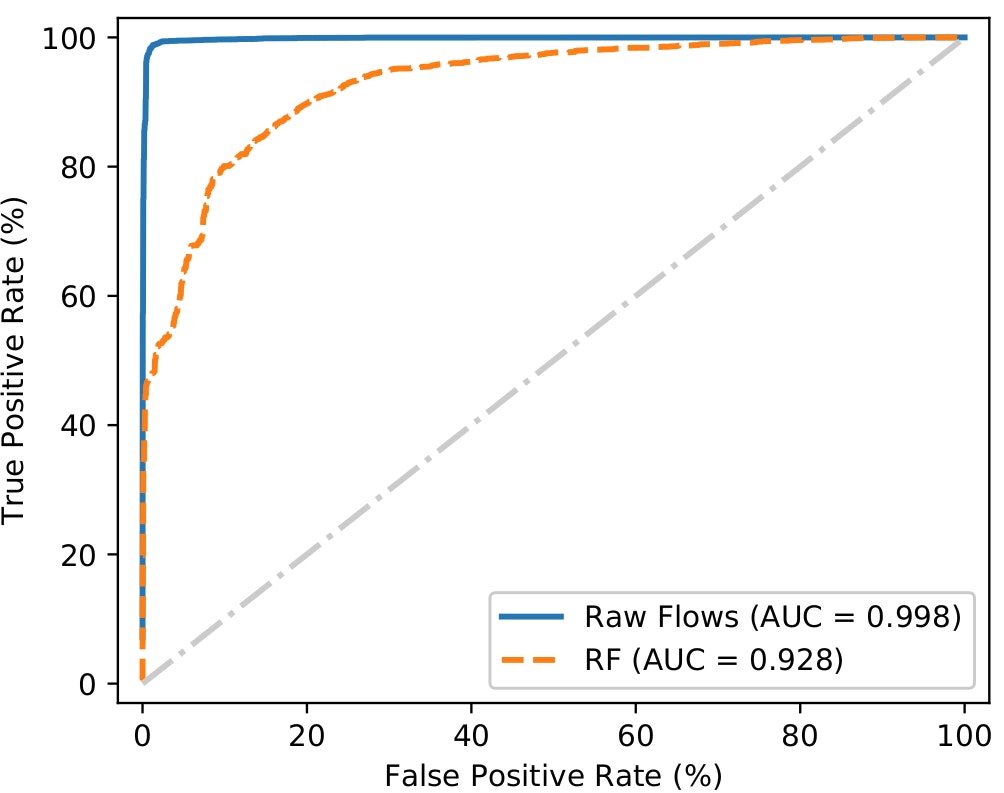
Given the raw flows representations, the deep learning model detects as much as 98% of all malware flows, with a false positive rate as low as 0.2%. This suggests that, when operating at the flow level, raw input representation and associated deep learning architecture can provide highly accurate results, applicable to the real world.
3. Domain knowledge vs. raw input
The last step of the evaluation aims to answer the third question regarding the benefits of the proposed approach over the standard approach for machine learning based malware detection.
In particular, that means studying the enhanced performance of the raw flows deep learning based model as compared to a random forest based model, the latter which uses specific handcrafted features based on domain expert knowledge as input.
We built a set of almost 200 flow-level features to feed a random forest model. Not surprisingly, the results suggest that the random forest model with domain expert features is highly accurate, detecting about 97% of all malware instances with a less than 1% false positive rate.
However, the deep learning-based model using the raw flows representations as input, slightly outperforms this domain expert knowledge based detector.
Furthermore, the raw flows deep learning model creates the set of input features on its own without requiring a specific handcrafted feature set.
Conclusion
Based on our three-pronged evaluation, with the random forest model serving as a performance benchmark, we can conclude that the proposed deep learning model, given raw flows representations as input in particular, can:
- Provide highly accurate malware detection results applicable to real world scenarios.
- Classify malware and normal traffic better than a shallow, random forest based model.
- Achieve results as good as those obtained through a domain expert knowledge based detector, without requiring any sort of handcrafted features.
Thus, we have dived into the dark waters of network security using traffic measurements, leveraging deep learning's feature representation power to complement traditional approaches that need expert knowledge to engineer features.
Check out the the slides of the presentation of my research at the DLS 2019.
It’s my hope that you enjoyed reading this post. Please use the comments section below to discuss any questions you may have. Happy malware detection!

Wondering how AI
can help you?

Terms and Conditions | © 2026. All rights reserved.
Get the playbook
