

LLMOps unpacked: the operational complexities of LLMs


Incorporating a Large Language Model (LLM) into a commercial product is a complex endeavor, far beyond the simplicity of prototyping. As Machine Learning and Generative AI (GenAI) evolve, so does the need for specialized operational practices, leading to the emergence of Large Language Model Operations (LLMOps). While some argue that LLMOps is an extension of MLOps, the unique challenges posed by the scale and complexity of LLMs require distinct strategies.
Much like AIOps (Artificial Intelligence for IT Operations) revolutionizes IT management by leveraging AI to enhance and automate operations, LLMOps addresses specific operational needs. The sheer size of LLMs introduces significant challenges and necessitates unique stages in project workflows.
This article explores these challenges and highlights the need for dedicated LLMOps practices.
LLMs’ unique operational needs
LLMOps builds on the foundational principles of MLOps but introduces distinct complexities due to the unique nature of LLMs. These models, with their immense size and intricate architecture, require tailored approaches to various operational aspects. Here are nine key points that highlight these specific considerations and why conventional MLOps practices must be adapted to manage and optimize LLM projects effectively.
1. Computational resources
LLMs demand significantly more computational resources compared to traditional Machine Learning models, both during training and inference. While an LLM pipeline follows similar fundamental steps as a classical Machine Learning one, it requires greater computing power and the capability to manage more complex, large-scale workloads. LLMOps aims to enhance performance while effectively managing the higher costs associated with these advanced models.
2. Prompt versioning
Prompt engineering is highly effective for guiding outputs. Managing prompt versions is crucial for monitoring progress and replicating results, making experiment tracking of utmost importance.
3. Human in-the-loop
Human input, though important in traditional Machine Learning, becomes critical in LLM pipelines. Techniques like Reinforcement Learning with Human Feedback (RLHF) are essential to align LLM outputs with human values and expectations.
4. Model management
LLMs are often hosted externally, meaning we don't have access to the training data, artifacts, or typically the architecture. This results in a more black-box approach with reduced explainability and increased dependency on external providers.
5. Evaluation
Validating generative models is much more complex than validating other Machine Learning models. Since LLMs create new content, standard evaluation metrics are often insufficient, requiring more nuanced validation methods.
6. Monitoring
Continuous monitoring of LLMs and LLM-based applications is crucial but more complex. It involves multiple aspects to ensure overall effectiveness and reliability, especially due to changes in provider models and the fact that we often don't host our base models.
7. Applying guardrails
LLMs can hallucinate, produce incorrect information, repeat training data, and even inadvertently offend users. There is a growing need to develop methods for implementing customized guardrails in systems that utilize these models. Dive into our article Taming LLMs: strategies and tools for controlling response to learn how guardrails works.
8. Hyper-parameter tuning
Adjusting hyperparameters in LLMs leads to significant changes in the cost and compute requirements for training and inference. In contrast, changes in hyperparameters in traditional Machine Learning models can affect training time and resource usage, but usually within a manageable scale for typical computing resources.
9. Inference
Inference for LLMs must be optimized, as loading these models is challenging and requires substantial memory. Providing accurate responses quickly is crucial for user experience. LLMOps ensures responses are delivered promptly, maintaining the fluidity of human-like interactions.

To synchronize and streamline these processes, strong operational practices are essential. This is where LLMOps comes in, guiding the experimentation, iteration, deployment, and continuous monitoring.
LLMOps pipeline and key concepts
The phases of an LLM project differ significantly from those of a traditional Machine Learning project.
LLM application development often concentrates on creating pipelines rather than creating new LLMs. Instead of training a model from scratch, evaluating, and performing hyperparameter tuning, we now focus on adapting pre-existing base models to our specific use cases. This shift requires new decisions and considerations, and a different approach to the entire process.
A typical LLMOps pipeline involves several key phases, each presenting unique challenges and requiring specialized tools and best practices. Let's explore these phases, the associated challenges, and the tools that can help navigate them effectively.
LLMOps pipeline key phases

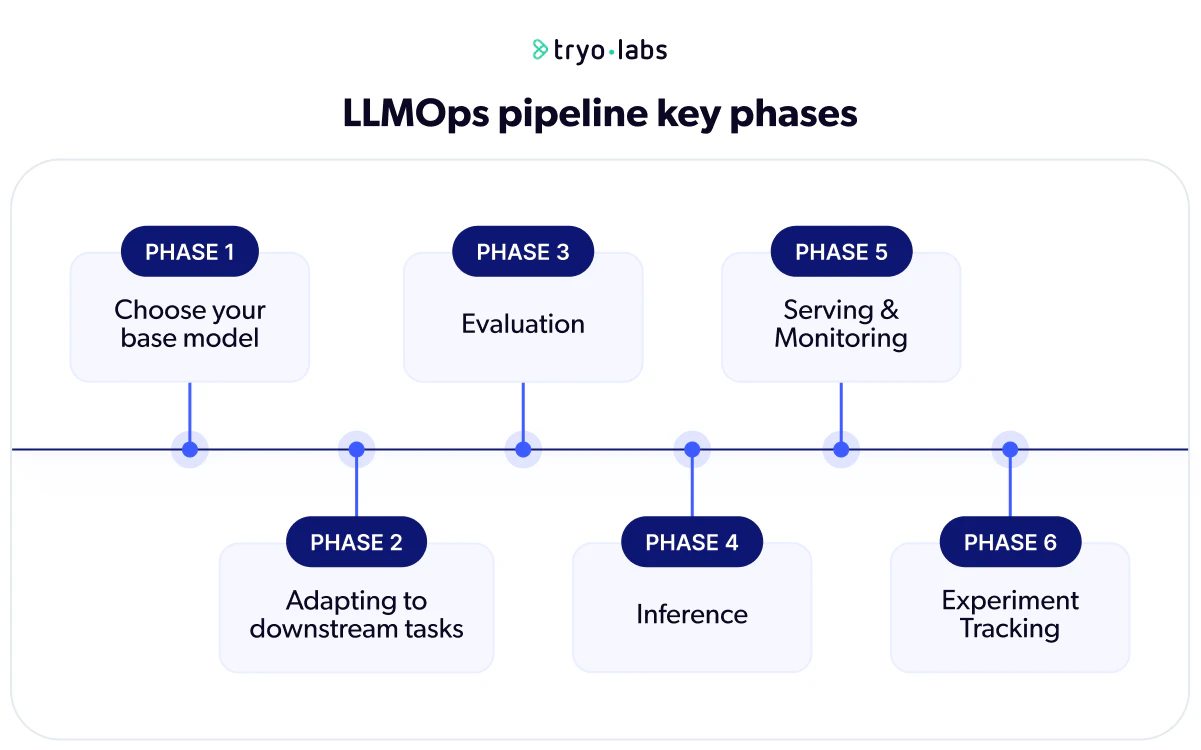
Phase 1: Choose your base model
Foundation models are models pre-trained on large amounts of data that can be used for a wide range of downstream tasks. Training a foundation model from scratch is complicated, time-consuming, and extremely expensive, which only a few institutions can afford.
Currently, developers choose between two types of foundation models: proprietary models or open-source models.
Proprietary models: These are closed-source foundation models owned by companies with large expert teams and big AI budgets. They are usually larger and have better performance compared to open-source models. They are off-the-shelf and generally easier to use. However, the main downside is their expensive APIs and the limited flexibility for adaptation.
Open-source models: Most open-source models are hosted on platforms like Hugging Face as a community hub. They are typically smaller and less capable than proprietary models but are more cost-effective and offer greater flexibility for developers.
So which one should you choose? When selecting a model for your project, it's always a tradeoff between cost, performance, ease of use, flexibility, the need for explainability and the available resources, to name but a few.
Pro tip:
At Tryolabs, we believe that starting with a proprietary model for an initial proof of concept is often beneficial. At this early stage, the costs are usually manageable, and it's valuable to observe how the problem we aim to solve responds to the best model available. From there, we can decide on the next steps.
Phase 2: Adapting to downstream tasks
Transitioning from choosing the right base model, the next critical step involves adapting these models to specific tasks to maximize their effectiveness.
Optimizing LLMs’ performance for specific tasks is essential. There are three primary strategies for achieving this: Prompt Engineering, Retrieval Augmented Generation (RAG), and Fine-tuning. Each approach serves distinct purposes and can be utilized in combination for the best results. Let's dive into these strategies and explore how they can transform the capabilities of LLMs.


Prompt engineering: crafting the perfect input
Prompt engineering focuses on refining the input (prompt) given to an LLM to ensure the output aligns with desired outcomes. This technique involves various methods to guide the model effectively:
- Role prompting: Assign the LLM a specific role, providing clear instructions to maintain focus on the task.
- Few-shot prompting: Present a few examples of the expected answers to similar inputs, helping the model understand the desired pattern.
- Chain prompting: Use multiple calls to the LLM, where each call's response is used as part of the prompt for the next call. This iterative process refines the output until it meets the desired criteria.
- Chain of thought prompting: Encourage the model to explain its reasoning, enhancing accuracy in tasks requiring logical or arithmetic processing.
RAG: enhancing context with external data
RAG is a powerful technique that leverages high-quality, private data not seen by the model during training.
Here’s how it works:
- Data storage: Store the embeddings of relevant documents in a vector database.
- Query retrieval: For each query, retrieve the most relevant documents from the database before generating a response.
- Context injection: Inject these documents as context for the response generation process.
This approach ensures that the model has access to up-to-date and relevant information, significantly improving the quality and accuracy of its responses.
Discover how RAG can elevate your LLM's performance in our in-depth article on Mastering RAG.
Fine-tuning: customizing the model’s knowledge and style
Fine-tuning is particularly useful for emphasizing existing knowledge within the model or adapting it to a specific style or tone. However, it’s not always ideal for incorporating entirely new information due to the extensive data already present in LLMs. For instance, while LLMs are adept at generating documents during pre-training, fine-tuning can enhance their ability to provide chat-based responses using their vast existing knowledge.
It involves adjusting the model weights to learn specific information we require. This process can be considered as minor model surgery, as we need to extend the model's original vocabulary.
A significant risk with fine-tuning is catastrophic forgetting, where the model loses previously acquired knowledge. Despite this, fine-tuning can be advantageous in reducing the input length, minimizing the need for extensive prompt engineering and additional context.
The most effective optimization often involves a combination of these techniques. Starting with prompt engineering is usually simple, cost-effective and quick. As the prompt lengthens and becomes more complex, transitioning to fine-tuning can help manage the context window efficiently.
Learn more about fine-tuning LLMs for scalable and cost-effective GenAI in our article.
Phase 3: Evaluation
Evaluating LLMs presents unique challenges, especially when compared to traditional Machine Learning models. These challenges arise primarily because LLMs generate new content, making standard evaluation metrics often insufficient.
Key challenges and methods for evaluating LLMs
- Non-deterministic outputs: LLMs can produce a variety of possible outputs for the same input, which can be both correct and incorrect. This variability makes evaluation more complex.
- Subjective evaluation criteria: Evaluating LLMs involves assessing a range of behaviors, such as accuracy, security, consistency, bias, and toxicity. These criteria can be subjective and require careful consideration.
- Cost considerations: Using non-open source LLMs can lead to escalating costs with extensive testing.
- Data access: Often, there is limited or no access to the training data distribution of foundational models. Even when available, the sheer volume of data makes it impractical to review comprehensively.
Why evaluation is crucial
Despite these challenges, evaluating LLMs is essential for several reasons:
- Tracking the effectiveness of changes
- Building better intuition for what works and what doesn't
- Keeping up with updates from vendors who continually refine base models
- Constructing datasets for fine-tuning purposes
Methods for evaluating LLMs
Here are six methods to evaluate LLMs. These methods are often complementary, and multiple approaches may be used depending on the application and development stage.
- Benchmark: This is the most common method seen when a new model is released. Benchmarks provide a standard set of tasks and metrics to compare different models.
- Human evaluation: Involves experts reviewing outputs, which, despite being costly and prone to biases, is almost inevitable and useful at various project stages.
- Metrics: For cases with clear or unambiguous text outputs, traditional metrics like Precision, Recall, and F1-score can be applied.
- Deterministic approaches: Includes methods like regular expressions, schema validators, custom functions. These are simple tests to ensure the application functions as expected. Metrics like BLEU and ROUGE, which match various n-grams, also fall into this category.
- Model-assisted evaluation: Uses other models to test the application, such as text embeddings to assess similarity or Natural Language Processing (NLP) models to evaluate other text aspects.
- LLM-assisted evaluation: The latest approach, using one LLM to evaluate another. It offers scalability and cost advantages over human evaluators but requires careful calibration to ensure reliable results and may introduce biases.
Tips for a successful evaluation strategy:
Start early: Begin the evaluation process before deploying the system to production.
Generate synthetic data: Predict how users will interact with the system to create synthetic data.
Use your LLM to generate new test cases: LLM can be used to generate synthetic data, produce test cases, and even judge the answers.
Expand the test set: Continuously expand your test set as new use cases emerge.
Phase 4: Inference
Inference is the process of drawing conclusions based on evidence and reasoning. In the context of LLMs, it involves passing a prompt through a trained model to generate an appropriate output based on learned patterns and relationships.
It's crucial to distinguish between inference and serving:
- Inference specifically refers to making a prediction.
- Serving encompasses the entire process: loading the model, receiving inputs, preprocessing, performing inference, and returning results efficiently and scalably.
Key challenges in LLM inference include:
- Latency: Achieving near-human interaction speeds is challenging due to memory bandwidth limitations. GPUs are crucial here, as their higher vRAM bandwidth allows them to handle vast amounts of data more efficiently than CPUs.
- Memory management: LLMs require significant memory for their weights and complex architecture. Quantization helps by reducing weight size, but it introduces a trade-off between memory savings and processing time.
- KV Cache: Essential for handling long contexts and quick responses, but increases memory demand linearly with batch size and sequence length.
Optimization techniques include:
- Model-level optimizations. Quantization reduces model size by using lower-precision representations of weights. Sparsity reduces the number of non-essential weights, making the model more efficient. Distillation creates smaller, faster models from larger, more complex ones, preserving performance.
- Attention mechanisms: Improves how the model handles attention to different parts of the input. Techniques include: multi-head attention, multi-query attention, grouped-query attention and flash attention.
- Model parallelization: Distributes workload among multiple GPUs, improving efficiency and reducing latency. Methods include: pipeline parallelism, tensor parallelism and Sequence parallelism.
These techniques, when applied appropriately, can significantly enhance inference efficiency at various levels of the LLM architecture.
Tools leveraging these techniques


vLLM:
- Ideal use case: Performance-driven applications requiring ultra-fast inference and low latency. Delivers outstanding serving throughput, significantly surpassing Hugging Face Transformers and TGI.
- Key features: Precisionaged attention, batch inference, optimized CUDA kernels, tensor parallelism, robust scheduler (capable of swapping, creating, and destroying memory blocks) and tensor parallelism (facilitates distribution across GPUs).
- Limitations: No fine-tuning, adapters, or quantization.
Note:
Paged Attention can be described as an 'intelligent KV cache' that handles memory extremely effectively by continuously tracking the exact location of specific pieces of information and pre-allocating the necessary memory.
TGI:
- Ideal use case: When native Hugging Face support is needed and adapters are not required.
- Key features: Tensor parallelism, quantization, continuous batching, accelerated weight loading (reduces startup time), logits warping (temperature scaling, top-k, repetition penalty), paged attention, flash attention, fine-tuning support (allows for more customization) and quantization (supports methods like ‘bitsandbytes’).
- Limitations: No support for adapters from the Transformers library yet.
OpenLLM:
- Ideal use case: When you want to connect adapters to the core model and utilize Hugging Face Agents, especially if not exclusively relying on PyTorch.
- Key features: Execute open-source LLMs with OpenAI-compatible APIs (which facilitates easy vendor switching), quantization and fine-tuning (essential for memory-efficient models), adapters (supports connecting adapters to the central model). It's a comprehensive platform (covers various aspects of LLM deployment, including fine-tuning, serving, monitoring, and quantization). Supports vLLM and PyTorch with different quantization options for each.
- Limitations: No streaming, no distributed inference, no batching.
By understanding these challenges and leveraging appropriate tools, organizations can optimize their LLM inference processes for maximum efficiency and performance.
Phase 5: Serving & monitoring
When it comes to deploying LLMs, there’s no one-size-fits-all solution. Several factors influence the decision, including the expertise of your team, available resources, time constraints, desired level of customization, and whether you need real-time responses or can work in batch mode.
Key consideration: external API vs. self-hosting
A crucial decision in LLMOps is whether to use an external API or host the model in-house:
- External APIs (e.g., OpenAI, Google, Cohere, or Anthropic)
- Pros: Quicker and simpler to implement; removes infrastructure management burden.
- Cons: Generally more expensive; less control over model, data, and infrastructure.
- Self-hosting
- Pros: More control over model, data, and infrastructure.
- Cons: Requires significant investment in infrastructure and expertise; complex management of large models demanding low latency.
Deployment options: cloud, on-premise, and edge
Depending on your specific needs, consider different deployment environments.


Choose your deployment strategy by weighing the benefits and trade-offs of each approach against your specific requirements and constraints.
Monitoring best practices
Given the potential for unexpected or incorrect responses from LLMs, and possible performance degradation due to changing data and usage patterns, robust monitoring is crucial.
1. Choose the right metrics
Adopt a comprehensive set of metrics covering:
- Quality
- Relevance
- Sentiment
- Security
2. Set up effective alerting and feedback systems
Develop a responsive and precise alerting mechanism for prompt intervention and continuous improvement.
3. Ensure reliability and scalability
Monitor key operational metrics:
- Time to First Token (TTFT)
- Time per Output Token (TPOT)
- Latency = TTFT + (TPOT × number of tokens to be generated)
- Error rates
- Resource utilization
4. Run adversarial tests
Challenge the model in controlled environments to identify and mitigate potential vulnerabilities. Examples include:
- Token manipulation
- Jailbreak prompting
- Training adversarial models
5. Ensure data integrity and model input
Maintain data integrity through:
- Ethical adherence
- Bias detection
- Drift detection
Phase 6: Experiment tracking
Experiment tracking in LLMOps is not just a final phase but a continuous process spanning the entire lifecycle of working with Large Language Models (LLMs). Its goal is to transform prompt engineering from mere experimentation into a disciplined engineering practice.
Why experiment tracking is crucial in LLMOps
In LLMOps, rapid iteration cycles are a hallmark of working with large language models. Unlike traditional Machine Learning, where hyperparameter tuning can be a lengthy process, LLM experimentation happens quickly, making it easy to lose track of previous prompts. The non-deterministic nature of LLMs further complicates this, as the same prompt can generate different outputs each time, necessitating meticulous tracking.
Moreover, prompts are frequently and significantly modified to fine-tune the model's output. The precision required when dealing with human language demands continuous and substantial adjustments. This dynamic environment highlights the critical need for robust experiment tracking to ensure consistency and progress in model development.
Effective experiment tracking
To effectively manage this, we need robust experiment tracking systems. This involves meticulously recording each experiment, the prompts used, the changes made, the results obtained, and some pertinent metrics. By doing so, we can ensure that valuable insights are not lost and that we can iterate and improve our models systematically. This approach not only enhances efficiency but also contributes to the overall reliability and reproducibility of our work with LLMs.
Tools for experiment tracking


1. Weights & Biases
- Team collaboration and visualization
- Comprehensive experiment tracking and visualization tools
2. Comet
- Special SDK for LLMs to log prompts
- Detailed tracking of LLM-specific experiments
3. MLflow
- Excellent for serving and deployment
- Integrates experiment tracking with model deployment workflows
4. TruLens
- Provides multiple feedback functions with interesting insights out of the box
- Offers unique perspectives on LLM performance and behavior
While these tools offer a great starting point, feel free to explore other options as the field of LLMOps continues to evolve rapidly.
By implementing robust experiment tracking practices and leveraging appropriate tools, organizations can ensure systematic improvement and reproducibility in their work with these powerful models.
Future trends
The future of LLMOps is set to be shaped by several key trends, each addressing emerging challenges and opportunities in the field.
- Enhanced model explainability: As LLMs become more integrated into critical applications, developing methods to understand and interpret their decisions will be crucial. This focus on explainability will help build trust and ensure the responsible use of AI.
- Advanced guardrails and ethical AI: The need for more robust frameworks to prevent undesirable outputs from LLMs is growing. Future developments will likely include stronger regulations and more sophisticated tools to manage model behavior and data ethics.
- Green AI and sustainable practices: The environmental impact of training and deploying large language models is a growing concern. Future trends in LLMOps will prioritize green AI initiatives, focusing on reducing the carbon footprint through more efficient algorithms, energy-efficient hardware, and optimized data centers.
- Federated learning and data privacy: As concerns about data privacy grow, federated learning will play a larger role in LLMOps. This approach allows models to be trained across decentralized devices without compromising user data privacy.
- Real-time adaptation and continuous learning: LLMs will increasingly support real-time learning, allowing them to adapt continuously to new information and user interactions. This trend will necessitate robust frameworks for continuous model updating and real-time deployment, ensuring that LLMs remain up-to-date and effective in dynamic environments.
- Human-AI collaboration tools: The future will see the development of tools that enhance collaboration between humans and AI, recognizing that human oversight remains essential for evaluating and refining LLM outputs.
- Integration with edge computing: To improve latency and reduce reliance on centralized data centers, deploying LLMs in edge environments will become more prevalent. This shift will enable faster, more localized processing, enhancing performance in various applications.
Final thoughts
Handling LLMs in production presents unique challenges that necessitate a dedicated operational framework. As we've explored, LLMOps extends beyond traditional MLOps by addressing the distinct complexities of working with large language models. From choosing the right base model to managing inference and tracking experiments, each phase of LLMOps requires specialized strategies to ensure success.
In this rapidly advancing field, staying ahead means embracing new trends such as enhanced model explainability, ethical AI practices, and sustainable operations. By adopting these advanced LLMOps practices, organizations can effectively manage, scale, and maintain LLMs, unlocking their full potential across a wide range of applications.
If your organization is looking to harness the power of LLMs or refine your existing AI strategies, adopting a comprehensive LLMOps approach is essential. Contact us to explore how we can help you bring to life cutting-edge LLMOps strategies.

LLMOps strategies tailored to your business needs

Terms and Conditions | © 2026. All rights reserved.