

Fine-tuning LLMs for cost effective GenAI inference at scale


Data is the new oil, fueling the AI revolution. From user-tailored shopping assistants to AI researchers, to recreating the King, the applicability of AI models knows no bounds. Yet these models are only as good as the data we feed them.
State-of-the-art generative AI models offer the potential to automate information extraction processes, providing a unified and adaptable approach that can ingest vast amounts of raw data in a short timespan. However, integrating a large language model into a production pipeline can be both costly and challenging.
In this blog post, we'll explore an effective way to leverage a powerful model like GPT-4 to produce titles for unstructured text, and then fine-tune your own open-source LLM with Predibase to perform accurate, controlled, and cost-effective inference. This task falls under the umbrella of automatic summarization (i.e., computationally extracting a small subset of information, representative of a larger document), but these ideas are applicable to the whole category of information extraction problems. So, if you're interested in unlocking the full potential of your data, keep on reading.
The power of Large Language Models (LLMs)
LLMs are AI models that have been trained on vast amounts of data, enabling them to both digest and produce human-like text. Their ability to understand and generate text makes them perfect for the task of information extraction. Instead of having teams of manual laborers perform a mechanical and low-engagement task, a single data scientist can interact (”prompt”) with the LLM, asking it to produce the required information. Inspecting the produced information, the scientist can apply techniques such as prompt-engineering and retrieval-augmented generation (RAG) to refine the model’s results, further improving the quality of automated results.
These tasks can take the form of automatic summarization, but also of any other Natural Language Processing task such as sentiment analysis, classification and the wider category of information extraction in general. With the advent of Multimodal LLMs, source information doesn’t even need to be text, images, audio and any kind of digitized data can be processed.
We now have the information extractor that we need. We can’t quite call it a day yet though. While state-of-the-art LLMs such as GPT-4 are incredibly powerful, their size and complexity make them expensive to use, reducing their applicability on projects with high query volumes.
The strategy: training cheaper models with LLMs
The idea is simple yet powerful: use an expensive LLM to perform an initial, high-quality and zero-shot, low-volume first pass, then use this data as labels to fine-tune a cheaper LLM, that instead of being a generalist like GPT-4 focuses only on your specific problem.
This approach gives you the best of both worlds. You get the high-quality data labeling capabilities of an expensive LLM on your specific task, while also reaping much lower ongoing costs because of the smaller, more specific and cheaper model for your actual business operations. Inference costs of smaller models is orders of magnitude smaller than those of proprietary API calls, with typical cost reductions in the 40X-200X range.
Another advantage of fine-tuning is that you won’t need as specific prompts, leading to needing fewer input tokens and therefore lower cost.
A third, often neglected advantage is that these models are Open Source. You can export the weights of your finetuned model and use readily available Open Source libraries, like llama.cpp or vLLM, to serve them where you see fit. This allows for secure prompting without the need for sending your private data to third parties and also to design your own scaling solutions avoiding rate limits and ensuring required throughputs. Also, LLM API providers will make changes to their underlying models and possibly deprecate API versions, by self hosting your own language model this risk is avoided entirely.
This strategy is cost-effective, scalable, private, and achieves high-quality outputs, making it an ideal solution for businesses of all sizes.
Case study: leveraging GPT-4 for fine-tuning an inexpensive LLM for AI news summarization
In this section we’ll show a real life case study on how the problem of information extraction can be resolved in a high quality cost effective fashion.
The task we’ll solve is creating an AI agent capable of understanding News articles related to AI and producing meaningful titles for them. This falls under the umbrella of Automatic Summarization.
The dataset
For this, we compiled a database from the "AI News Shorts" section of MarkTechPost, a reputable source for current AI trends.

This dataset, consisting of numerous articles, posed a significant challenge for labeling, due to its sheer volume and the dense, technical nature of the content.
Putting generative AI into action: by using GPT-4 Turbo, specifically the gpt-4-1106-preview model, we generated titles using this customized prompt:

You are a highly skilled marketing AI consultant trained in language comprehension, summarization and bizdev.
You have to read the following AI news text and extract a concise, catchy title, no more than 60 characters long.
Include in the title the name of the development and why it's relevant: this may be because of technological advancements, societal impact, business applications, investment opportunities, security and privacy, AI ethics, because the author is well known (ie Google, Meta, Apple, etc), or other factors.
These are some good example titles:
- Code Llama, an Open-Source LLM for coding
- DeciCoder, a 1B Params FOSS Code-Gen LLM by Deci
- Google Unveils Multimodal Gemini" AI
- TII released Falcon 180B
- Microsoft unveils custom AI chips
- SynthID, identifying AI-generated images
- Meta advances the development of social embodied AI agents
- Replit now offers free access to AI Assistant
- Milestone in AI breast cancer detection
- Microsoft brings Python to Excel
- GraphCast, faster, more accurate, global weather forecasting
- NExT-GPT, An any-to-any Multimodal LLM
- Grok, a Hitchhiker's Guide to the Galaxy based AI, by xAI
- Q-ALIGN, Aligning AI Image Assessment with Human Judgment
- LLMs Crack Visual Code, MIT CSAIL's Text-To-Image Synthesis
Include only the summarized title in the response.
AI News Text: {text}
The approach we just took is an application of synthetic data generation, where we had an AI model create the information for us.
For the sake of this example, we used this prompt to generate 400 titles that we manually curated one by one. During this process we found 59% of the generated titles needed no corrections while the remaining 41% needed some form of adjustment.
We took note of the “errors” the model made (in this context we wanted the model to generate user-friendly titles so we considered specialized acronyms and jargon as errors) and found titles like these:
DL3DV-10K: Pioneering NVS with Real-World Data
MoE LLMs Optimized for Consumer Hardware
Readers familiar with AI jargon may realize that V2V refers to Video-2-Video, NVS to Neural View Synthesis and MoE to Mixture of Experts, but for newcomers these acronyms may be difficult to read.
We also found the model had some issues identifying two kinds of news articles: tool compilations and dataset releases.
For the tool compilations, things such as “Top 40 Generative AI tools (December 2023)”, GPT-4 produced a title related to the first tool on the list, instead of realizing the article was a compilation. For the linked article, the first title GPT-4 produced was this:
In the case of dataset releases, such as a paper introducing DL3DV-10K—a large-scale scene dataset for 3D Vision—the main interest lies in the new data's availability for benchmarking aspects of AI. However, the titles generated often missed the mark, focusing incorrectly, as seen here:
Having identified these issues we reformulated the prompt to this (modifications highlighted in bold italic):
You are a highly skilled marketing AI consultant trained in language comprehension, summarization and bizdev.
You have to read the following AI news text and extract a concise, catchy title, no more than 60 characters long.
Avoid overly specialized tech jargon and little known acronyms, but use buzzwords and keywords related to the area of application.
Include in the title the name of the development and why it's relevant: this may be because of technological advancements, societal impact, business applications, investment opportunities, security and privacy, AI ethics, because the author is well known (ie Google, Meta, Apple, etc), or other factors.
These are some good example titles:
- Code Llama, an Open-Source LLM for coding
- DeciCoder, a 1B Params FOSS Code-Gen LLM by Deci
- Google Unveils Multimodal Gemini" AI
- TII released Falcon 180B
- Microsoft unveils custom AI chips
- SynthID, identifying AI-generated images
- Meta advances the development of social embodied AI agents
- Replit now offers free access to AI Assistant
- Milestone in AI breast cancer detection
- Microsoft brings Python to Excel
- GraphCast, faster, more accurate, global weather forecasting
- NExT-GPT, An any-to-any Multimodal LLM
- Grok, a Hitchhiker's Guide to the Galaxy based AI, by xAI
- Q-ALIGN, Aligning AI Image Assessment with Human Judgment
- LLMs Crack Visual Code, MIT CSAIL's Text-To-Image Synthesis
Include only the summarized title in the response. Don't enclose your title in quotes.
If the article refers to the release of a dataset, identify the dataset's relevance. If the article isn't a news article but instead a compilation of developments, such as: 40 AI code tools you can try today, identify it and produce an according compilation title.
AI News Text: {text}
And proceeded to generate titles for the remaining 600 rows in the dataset.
Fine-tuning an LLM for the specific task
Finetuning a language model is a supervised form of training, requiring a labeled dataset, on which a subset of the models’ parameters are retrained to learn a specific task. This form of training is far cheaper to compute, since it doesn’t involve modifying the entire set of model weights, and is well suited for tuning a model to a specific kind of output.
Typical use cases of fine-tuning include adopting a writing style, efficient text compression, producing structured output such as JSON, and adopting task specific lexicon when the original training dataset didn’t have enough variety.
State-of-the-art code for parameter efficient fine-tuning algorithms can be found in HuggingFace’s excellent PEFT library. While the basic flow of implementing your own code to do fine-tuning with PEFT is pretty straightforward, you just instantiate a LoraConfig object with a few training parameters, and tell it to run off of a base model, executing this code is no small feat. You can see in PEFT’s own examples that fine-tuning a model as small as 3B parameters will use more than 14GB of video RAM. This can be alleviated with CPU offloading, but then training times will suffer. And this is just for the 3B parameter model, 7B models are shown to require as much as 55GB VRAM. Access to server-grade compute GPUs alleviates these issues.
While all this is doable, we’ll follow a more streamlined approach, that will both save us time and spare us trouble in the future.
Fine-tuning with Predibase
We want to go the easy route this time, so we’ll use Predibase for both the fine-tuning and the inference. Predibase is an LLM infrastructure provider for Open Source models, enabling its customers to serve customized language models at a fraction of the costs other services offer.
Moreover, their platform streamlines the fine-tuning process using state-of-the-art approaches such as LoRA and QLoRA, making experimentation and deployment as simple as a few clicks. Their compute instances include NVIDIA A100 80GB VRAM GPUs to finetune your models on.
As of the writing of this post, inference of a smaller 7B model on their infrastructure will cost 50 times less per input token than GPT-4 Turbo, and 150 times less per output token. You can simulate your savings by making a copy of this handy calculator we made. With a system similar to ours making 100k requests/day you can save ~$1200 per day from API calls only.
For the task at hand, we wanted to push the capabilities of the platform, so we trained 4 different model variants (we actually trained 10, but we’ll share the most interesting here):
llama2-13b-chat, an instruction tuned 13B parameters version of Meta’s Llama2.mistral-7b-instruct, an instruction tuned 7B param surpassing llama2-13b in several benchmarks.zephyr-7b-beta, an already finetuned version of mistral-7b using Direct Preference Optimization.mixtral-8x7b-instruct-v0-1, this one is the odd one out since it’s in a different weight class and its serving costs makes it less attractive for use. It’s a 47B parameter model but the interesting thing is it’s achieving similar performance to much heavier models such as Llama2-70B and GPT-3.5 so we wanted to see how it fared in the comparison.
Training these models using Predibase is a breeze. You upload your dataset (or connect one of the many available cloud storage provider integrations) to create a data connection:

Once your data is connected, creating a new model task is as simple and streamlined as selecting your parameters:

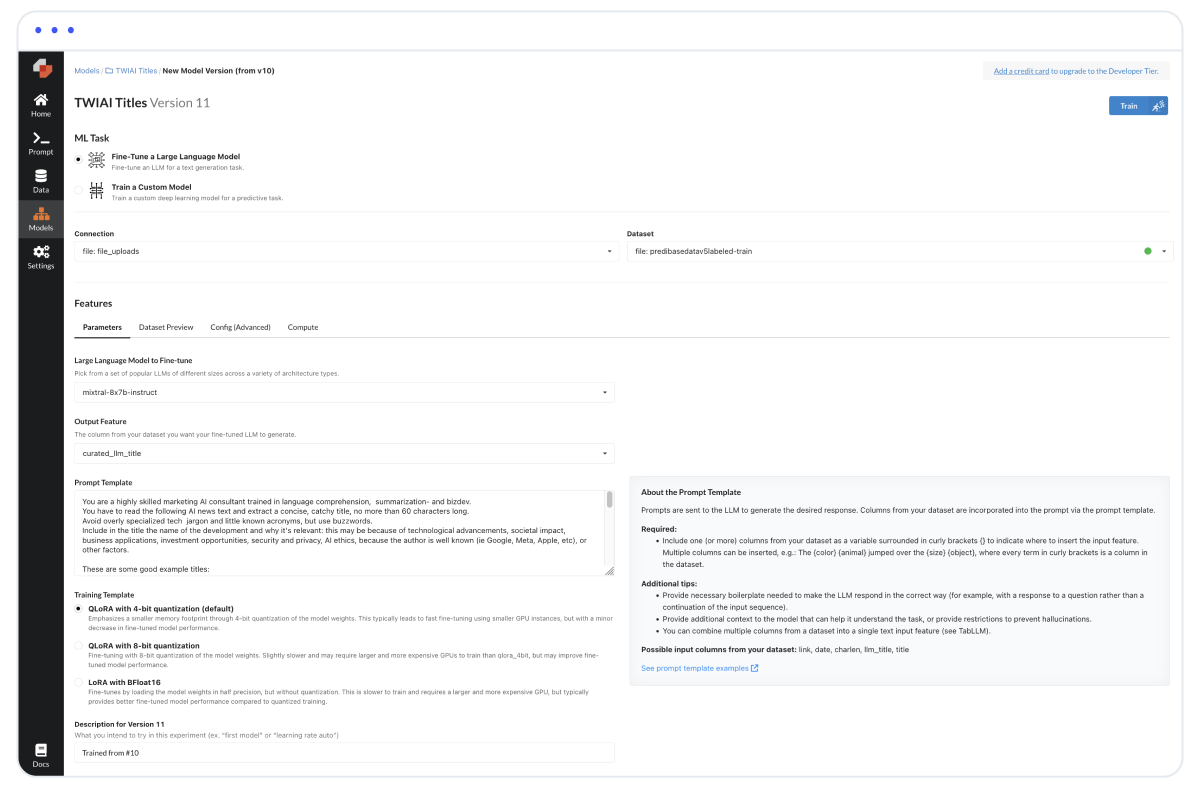
Predibase allows for both full custom model training (adjusting all model weights) as well as fine-tuning. Start by creating a model repository to organize your workflows. Then select your dataset, the base model you want to fine tune and introduce the prompt template. The prompt template uses a simple wildcard logic where you can replace any content with a dataset column by enclosing it in curly brackets. For example {text} gets replaced with the value of the text column for each row in the selected dataset.
Finally, you choose the target column the model should aim to replicate, and select whether you want to use QLoRA with 4 or 8 bit quantization, or no quantization LoRA. We tried all and found very little performance difference between them, hence we suggest going with the cheaper and faster QLoRA 4bit quantization, at least for quick experimentation.
And that’s it! Your model is trained and ready to serve with this code snippet:
Inquisitive readers might have realized that we get the model for
“TWIAI Titles”.TWIAI stands for This Week in AI, our weekly curated list of significant AI news.
That’s right, we use tools such as these to automatically catalog and summarize the content, but don’t worry, human curators revise, prioritize and decide which news are worthy of attention.
Evaluating model performance: beyond manual inspection
With cost-effective inference models at our disposal for information retrieval tasks, a critical question arises: How can we ascertain the quality of the generated titles?
The challenge of evaluating LLMs
Evaluation of LLMs remains a complex area of ongoing research. The challenge lies in quantitatively capturing behaviors such as "understanding the meaning" or "adhering to the prompt," which are inherently qualitative. Although manual inspection is often considered the most reliable method for assessing LLM outputs, striving for a degree of objectivity in our evaluations is essential.
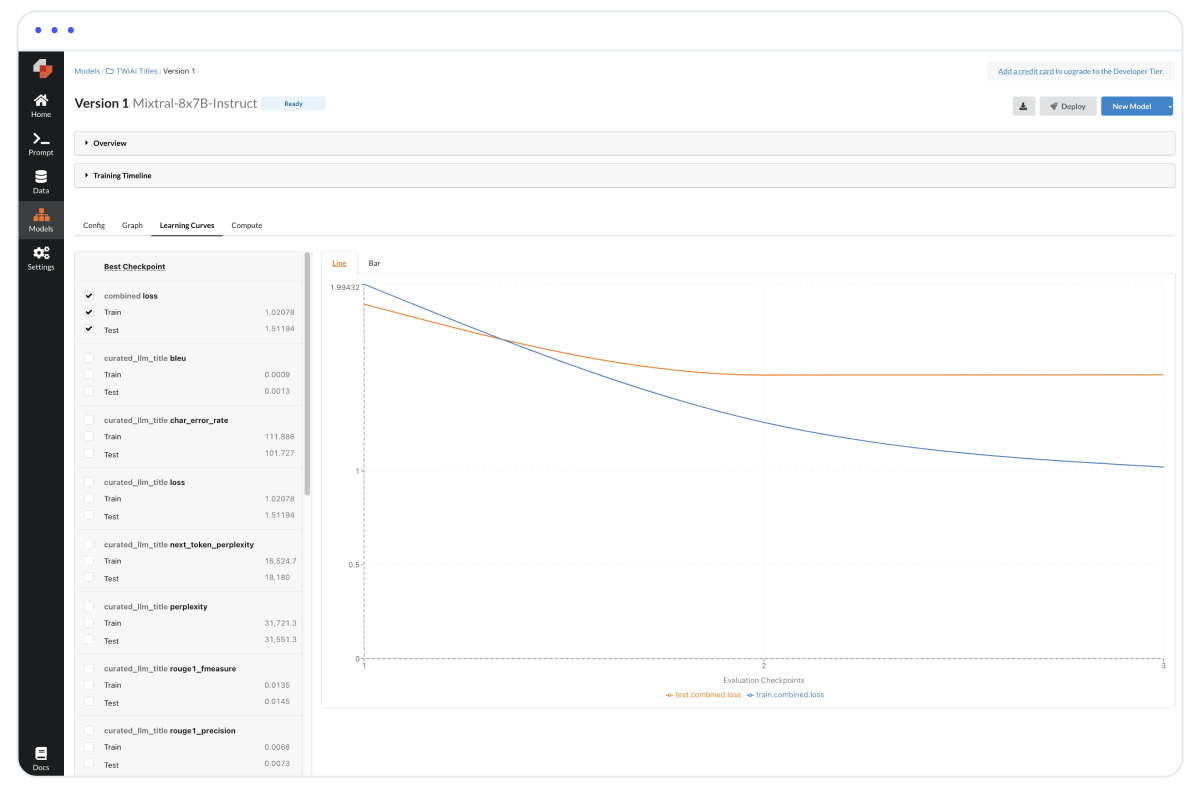
Predibase’s built-in metrics
Predibase enhances this process with a suite of built-in metrics for model evaluation. These metrics, include a combined loss that accounts for various factors like ROUGE, BLEU, perplexity, and others, offering a foundational layer for objective analysis and model training.
Custom evaluation with BERT-Score
Yet, to align our evaluation closer with our specific needs—ensuring the generated titles accurately reflect the articles' main points—we turned to bert-score, a contextual similarity metric. BERT-score assesses how closely the meanings of two texts align by calculating microsoft/deberta-xlarge-mnli embeddings (a model derived from BERT) for each text's tokens. By employing cosine similarity, it measures the closeness of tokens in encoding space, with proximity indicating similarity in meaning.
For each input token, cosine similarities are calculated, and the most closely related output token is identified. Finally similarities are averaged across all input tokens to produce the final metric. The authors propose 3 pivotal metrics: precision (the relevance of the generated title to the original text), recall (how comprehensively the title covers the original content), and the F1 score (a harmonic mean of precision and recall). A perfect score of 1 in these metrics signifies an ideal match. For our problem we’ll be focusing on precision as our primary metric of interest. This choice stems from our goal to determine how well the generated title retains the original text's core information.
Analyzing the results
Now, let's delve into the data. We begin by comparing the performance metrics of GPT-4 against 400 manually curated labels:

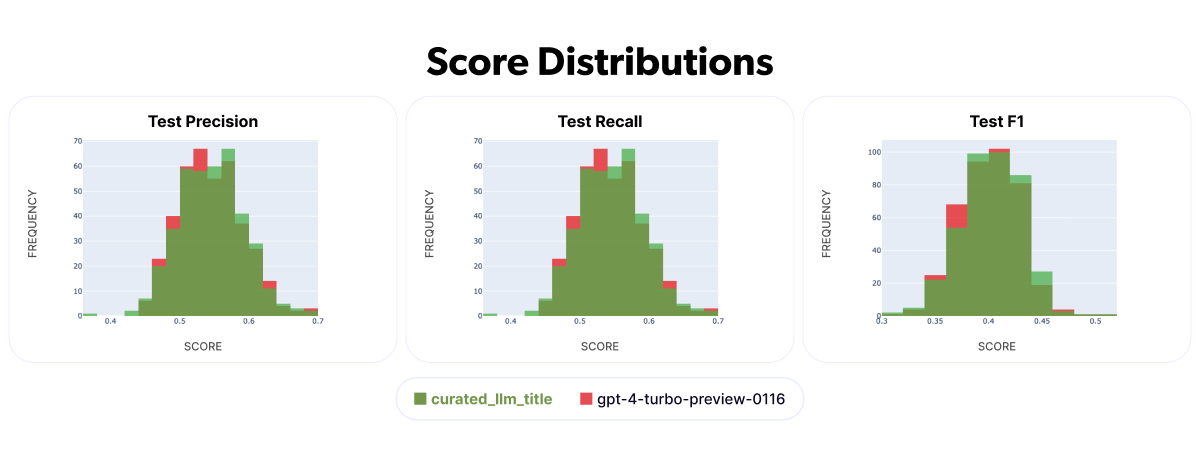
Don’t take these face-value, but in principle, all curated score distributions are shifted to the right, indicating that both our own subjective assessment of better titles produced by the curation and the objective metric, agree that the curation captures more of the original meanings than the zero shot titles that GPT-4 came up with.
Moving on to the finetuned models, we’ll focus on the precision metric only, and compare GPT-4 (in red) to all finetuned models:

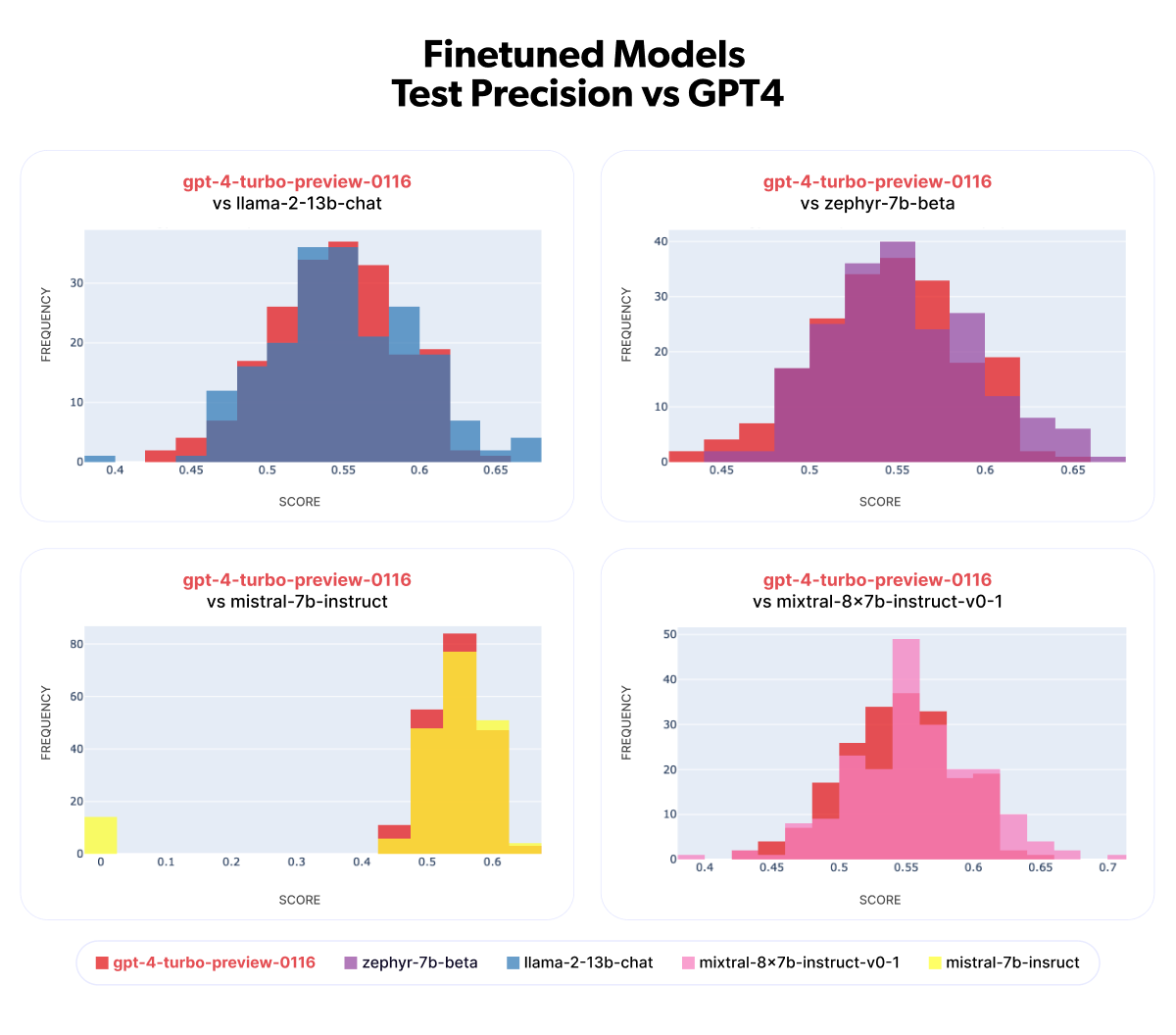
You can see that, save mistral-7b which produced a few empty titles resulting in 0 Precision, all finetuned precision distributions are slightly shifted to the right. mixtral-8x7b-instruct-v0-1 is the best performing model in terms of this average precision but the much smaller and chepear zepyhr-7b-beta is so close behind that we’re opting for it. You can find average and standard deviation of precision for each of these in the Test Precision Stats sheet.
Subjective evaluation and conclusion
We said that manual evaluation was best for these models. So let’s take a look at some of the examples produced by zephyr and GPT-4. This is a sneak peek of the data, you can find the full data in the Test Manual Comparison sheet of this doc:

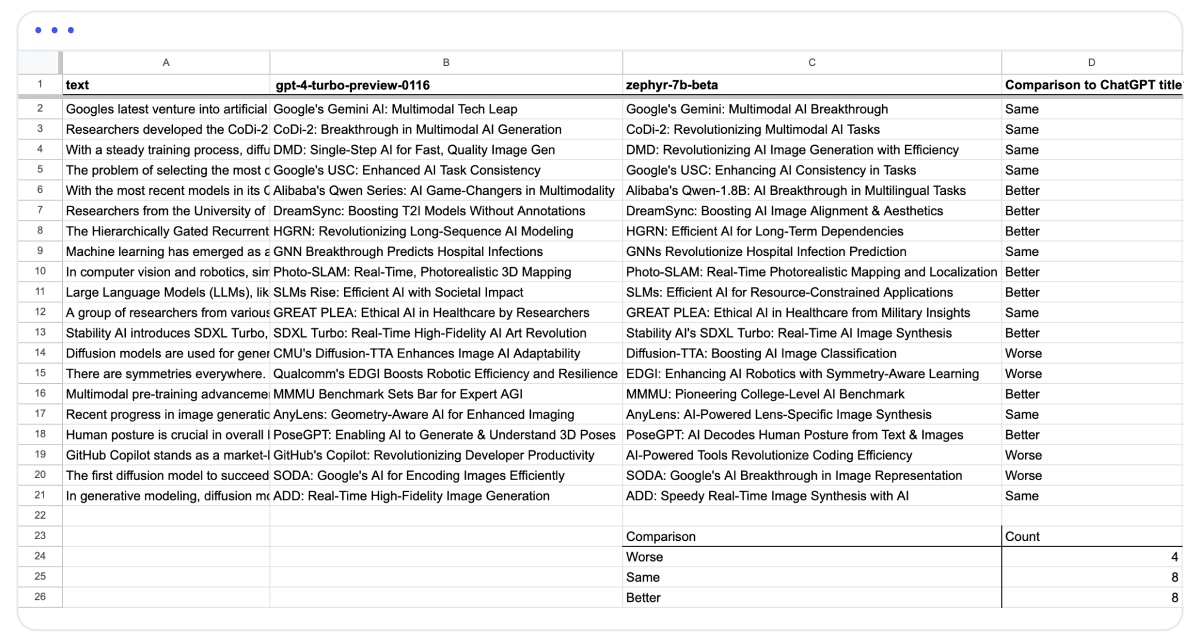
This conclusive evidence aligns our objective metrics with subjective evaluations, consistently demonstrating that the smaller model frequently generate titles of comparable or superior quality.
Conclusion
Thus concludes our comprehensive exploration: from sourcing a publicly available dataset and initially employing a high-cost, generalist LLM for rapid, zero-shot auto-labeling, creating an initial synthetic dataset, to refining quality through manual curation, and ultimately fine-tuning a smaller LLM for efficient and precise inference in production settings.
Further work could involve refining the prompt into shorter a less specific version, for additional savings now that our model has been finetuned. Another avenue could be enriching the synthetic data generation process by building a retrieval augmented generation system that would feed articles and titles similar to the one being summarized instead of the generic examples we provided in the prompt.
Balancing AI performance and cost
Navigating the complexities of AI integration into your business operations doesn't have to be a daunting task. With the right approach, leveraging advanced LLMs for data labeling and subsequently fine-tuning less expensive models allows for the exploitation of GenAI's potential in a manner that is both impactful and cost-efficient. At Tryolabs, our mission is to transform this potential into your competitive advantage.
We are committed to crafting bespoke AI solutions that not only meet but exceed your unique business requirements. Our expertise lies in identifying and executing the most effective strategies for each project, ensuring that cost-effectiveness is not just an option but a priority. Let us guide you through the process of making AI work for you — efficiently and economically.
Ready to take the next step? Let’s talk!

Wondering how AI
can help you?

Terms and Conditions | © 2026. All rights reserved.