

Taming LLMs: strategies and tools for controlling responses



In the ever-evolving landscape of natural language processing, the advent of Large Language Models (LLMs) has ushered in a new era of possibilities and challenges. While these models showcase remarkable capabilities in generating human-like text, the potential for unintended consequences raises concerns: hallucinations—instances where the model generates information that is factually incorrect or entirely fabricated, formatting problems, the use of harmful and biased language, and security issues to name a few. Generative AI is a double-edged sword and what makes LLMs helpful might also introduce significant risks.
To mitigate some of these issues, researchers are working on what they call model alignment, using strategies such as Reinforcement Learning from Human Feedback (RLHF) and fine-tuning. However, those strategies are often implemented before making the LLM available to the public. In this post, we will delve into techniques that can be used even when the model has been developed. For a more in depth exploration of these techniques, refer to this survey.
Understanding the need to address these challenges, developers often seek alternative ways to limit the outputs of LLMs to ensure the practical usability of LLM-generated content in diverse applications, enhance accuracy and security, and maintain ethical standards. As we explore strategies for controlling LLM outputs, we aim to strike a balance between harnessing the power of these models and addressing the inherent challenges they pose.
We’ve researched alternatives to address output limitation so you don’t have to. At a high level, there are 3 strategies that act at different stages of the process to ‘control’ an LLM:
- Effective prompting
- Parameters and guided generation
- Post-generation guardrails


Strategy 1: effective prompting
Prompting is the easiest strategy we’ll cover. Prompting, in essence, is about designing the initial query or statement in such a way that it effectively communicates our intent to the model, thereby influencing its response to align with our desired outcome. As the field advances, its focus expands beyond crafting prompts to encompass the design of systems where model queries serve as integral components.
Utilizing prompts represents a potent approach to augment the adaptability and manageability of large language models. A meticulously crafted prompt holds the potential to significantly amplify the productivity of LLMs. Some strategies that use prompting are templates, example libraries, or prompt optimization tools that structure user-inputted prompts. The advantages of these strategies are facilitating effortless interaction for non-technical users as well as optimizing interaction efficiency.
Chain of Thought (CoT) is one example of how a prompt can be adapted to align with an expected result. It’s a method that encourages the LLM to justify its “reasoning” and usually involves including examples on the prompt that better illustrate the intended answer.


Examples & tools
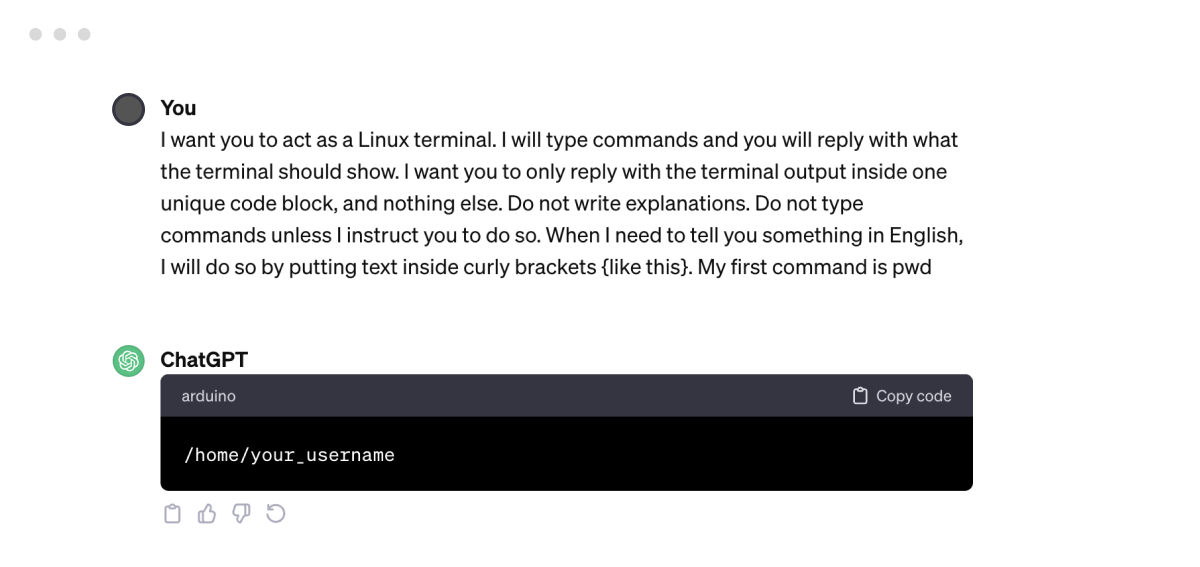
Awesome ChatGPT Prompts is an open-source collection of curated prompt templates for ChatGPT, each tailored for unique applications and use cases. LangGPT follows a similar approach. As an example, here’s a prompt template to turn ChatGPT into a Linux Terminal:

PromptSource is a toolkit for creating, sharing, and using natural language prompts. Prompts are saved in standalone structured files and are written in a simple templating language called Jinja. An example of a prompt available in PromptSource for SNLI is:
PromptLang is a custom programming language specifically designed for use in GPT-4 prompts and AI interactions. Promptify is used to solve Natural Language Processing (NLP) problems by generating different NLP task prompts for popular generative models like GPT, PaLM, and more.
Strategy 2: parameters and guided generation
Moving on to the second category of strategies, we focus on the techniques employed when calling the LLM. This stage involves the use of specific methods that can further refine the model's output during the generation process. One such powerful tool is logit filtering. Before covering this strategy, let’s discuss how text generation works under the hood. After getting the prompt, the model generates logits (raw, unnormalized predictions) for each possible output token (which isn’t necessarily a word). These logits are then passed to a softmax function, generating a probability for each possible output and a probability distribution over the entire model’s vocabulary.
By accessing the logits themselves, we can manipulate them and scope the response, for example by:
- Setting some logits to zero: useful to filter out words, topics, etc.
- Applying a weighted mask: useful to allow for more control and aligns with a probabilistic approach.
- Increasing/decreasing desired logits: useful to adjust the chances of some tokens being generated over others.

Take into account that directly manipulating logits can sometimes lead to unnatural responses if done too aggressively
Examples & tools
LM-Format-Enforcer is a library that enforces the output format of language models by filtering tokens. It works by combining a character-level parser and a tokenizer prefix tree into a smart token filtering mechanism. When the language model generates a token, the character level parser gets advanced according to the new characters, ready to filter the next timestep.
Here is an example using the regular expression format Michael Jordan was Born in (\d)+.
| idx | generated_token | leading_token | generated_score | leading_score | generated_token_idx | leading_token_idx |
|---|---|---|---|---|---|---|
| 0 | ▁ | ▁ | 1.000000 | 1.000000 | 29871 | 29871 |
| 1 | Michael | ▁Sure | 0.000027 | 0.959473 | 24083 | 18585 |
| 2 | ▁Jordan | ▁Jordan | 1.000000 | 1.000000 | 18284 | 18284 |
| 3 | ▁was | ▁was | 1.000000 | 1.000000 | 471 | 471 |
| 4 | ▁Born | ▁born | 0.000008 | 1.000000 | 19298 | 6345 |
| 5 | ▁in | ▁in | 0.994629 | 0.994629 | 297 | 297 |
| 6 | ▁ | ▁ | 0.982422 | 0.982422 | 29871 | 29871 |
| 7 | 1 | 1 | 1.000000 | 1.000000 | 29896 | 29896 |
| 8 | 9 | 9 | 1.000000 | 1.000000 | 29929 | 29929 |
| 9 | 6 | 6 | 1.000000 | 1.000000 | 29953 | 29953 |
| 10 | 3 | 3 | 1.000000 | 1.000000 | 29941 | 29941 |
| 11 | . | . | 0.999512 | 0.999512 | 29889 | 29889 |
| 12 | < /s > | < /s > | 0.981445 | 0.981445 | 2 | 2 |
The model "wanted" to start the answer using Sure, but the format enforcer forced it to use Michael. Afterward, almost all of the leading scores are within the allowed token set, meaning the model likely did not hallucinate due to the token forcing. The only exception was timestep 4 - " Born" was forced while the LLM wanted to choose "born". This is a hint for the prompt engineer, to change the prompt to use a lowercase “b” instead.
The obvious limitation of this method is that it requires a Python API to process the output logits of the LLM. This means that, at least for now, it cannot be used with OpenAI ChatGPT and similar API-based solutions because those APIs don’t offer that kind of access.
ReLLM (an acronym for ‘Regular Expressions for Language Model Completions’) is another library that works at the token level. After providing a prompt and a regular expression, ReLLM filters non-matching tokens pre-generation. For each token, ReLLM tests every possible completion against a partial regex. For the potential completions that do not match the pattern, ReLLM masks the logits so that the language model does not generate them. Here is an example of GPT2 responses with and without ReLLM:
ParserLLM extends ReLLM to handle context-free grammar and a parser generator to determine valid next tokens for an LLM generation.
Another key strategy when calling the LLM is tuning certain parameters and leveraging the features exposed by the LLM. It is worth taking the time to familiarize yourself with the documentation and parameters of the model you intend to use.
One example of this is OpenAI’s function calling, which “allows you to more reliably get structured data back from the model”. Another strategy is using the JSON mode, although OpenAI’s documentation includes the following disclaimer: “While this does work in some cases, occasionally the models may generate output that does not parse to valid JSON objects”.
Another strategy is using OpenAI’s Moderation endpoint, free to use when monitoring the inputs and outputs of OpenAI APIs, which classifies the following categories: hate, threatening, harassment, self-harm, sexual, minors, and violence. The endpoint returns the following fields:
flagged: Set totrueif the model classifies the content as violating OpenAI's usage policies,falseotherwise.categories: Contains a dictionary of per-category binary usage policies violation flags. For each category, the value istrueif the model flags the corresponding category as violated,falseotherwise.category_scores: Contains a dictionary of per-category raw scores output by the model, denoting the model's confidence that the input violates the OpenAI's policy for the category. The value is between 0 and 1, where higher values denote higher confidence. The scores should not be interpreted as probabilities.
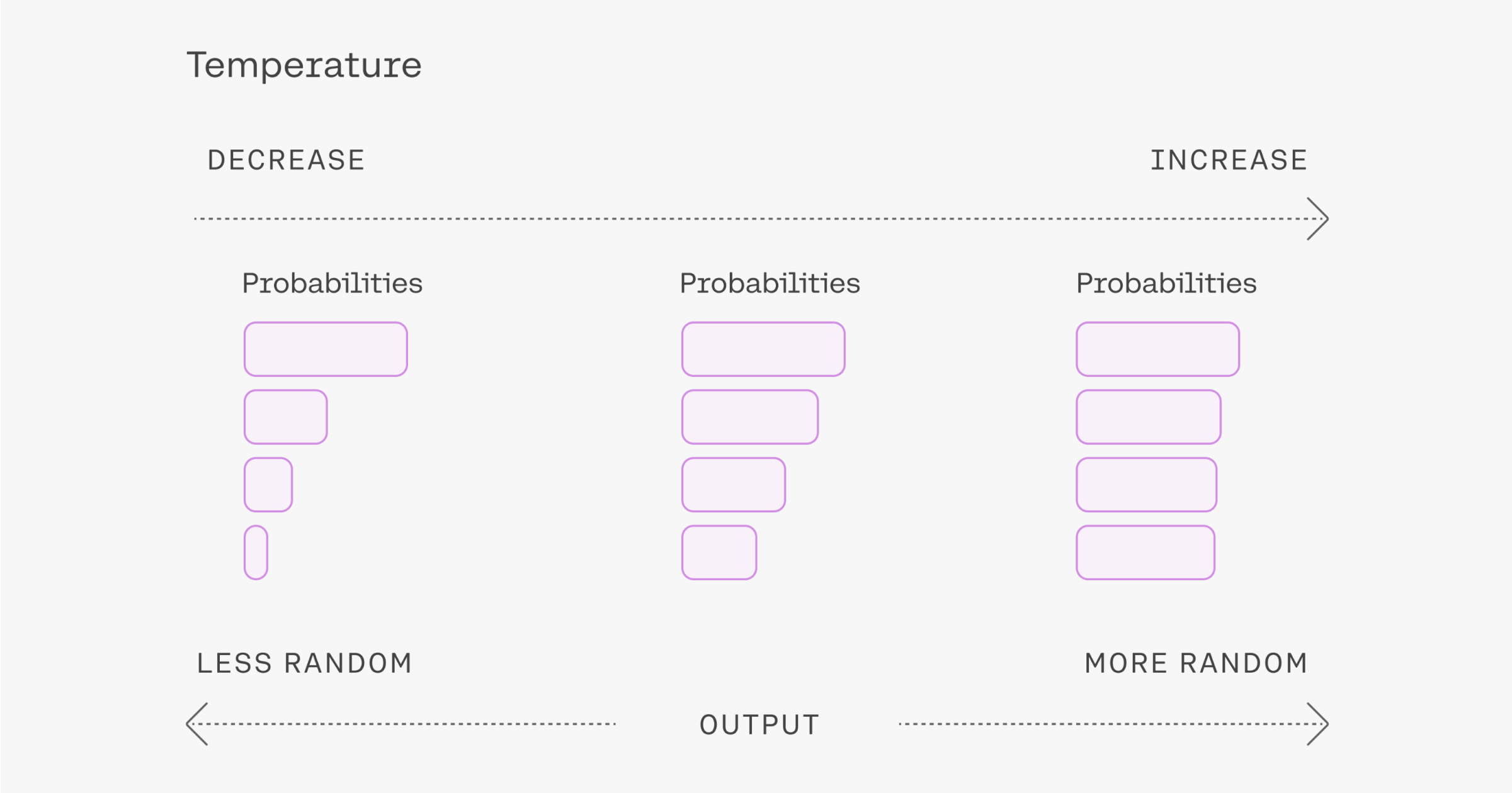
Most LLMs also provide parameters that can be tuned. Parameters such as temperature, top-k and top-p sampling can be used to somewhat control the model’s output. The temperature strikes a balance between randomness and predictability, adjusting the probability distribution used for token selection. A higher temperature increases randomness by flattening the distribution, while a lower temperature concentrates probability on a smaller set of tokens, resulting in more deterministic output. Top-k just considers the K most likely tokens and ignores all others, then samples one of them by considering their likelihood scores. Top-p dynamically sets the size of the shortlist of tokens whose sum of likelihoods does not exceed a certain value p.


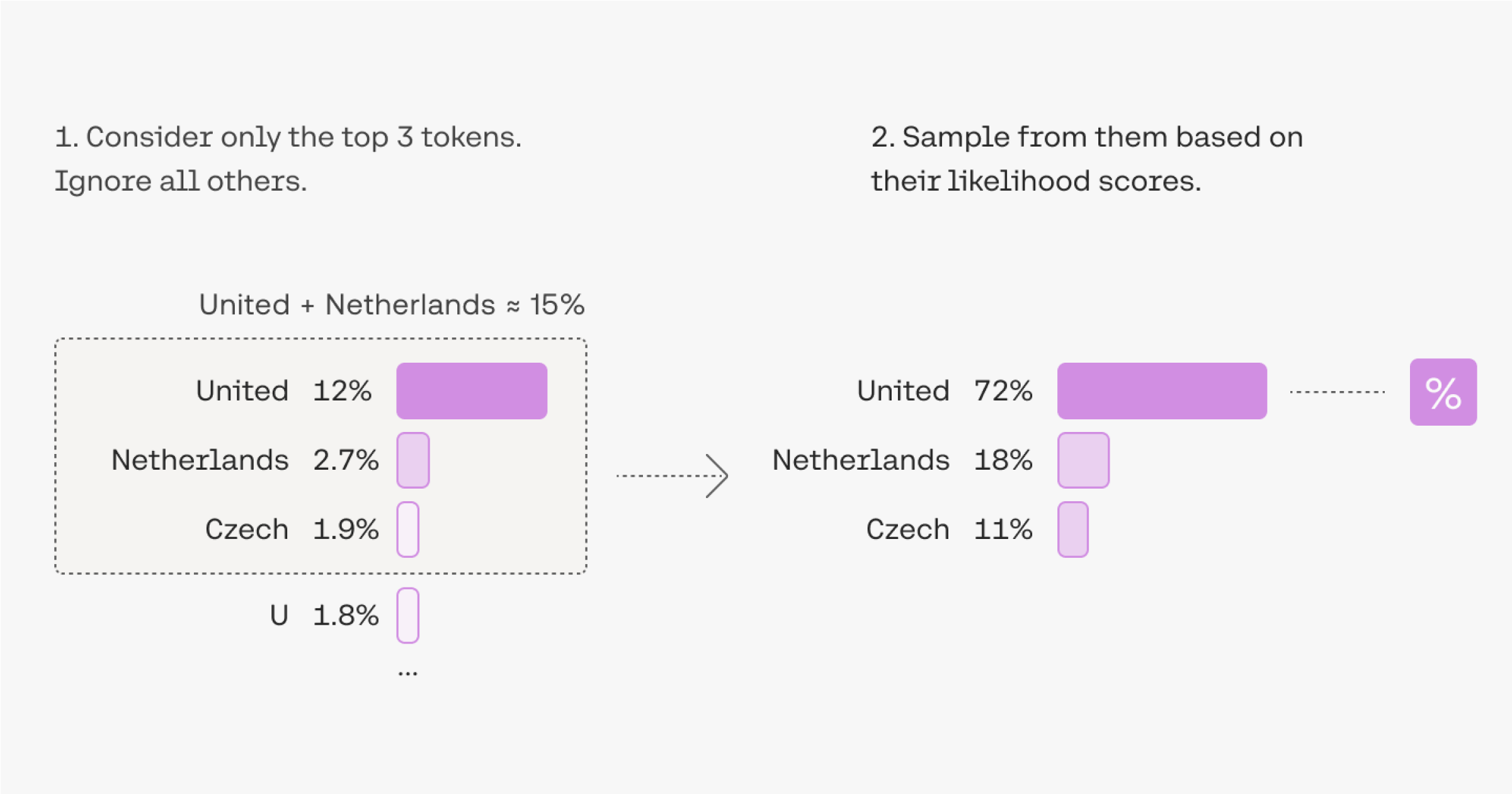
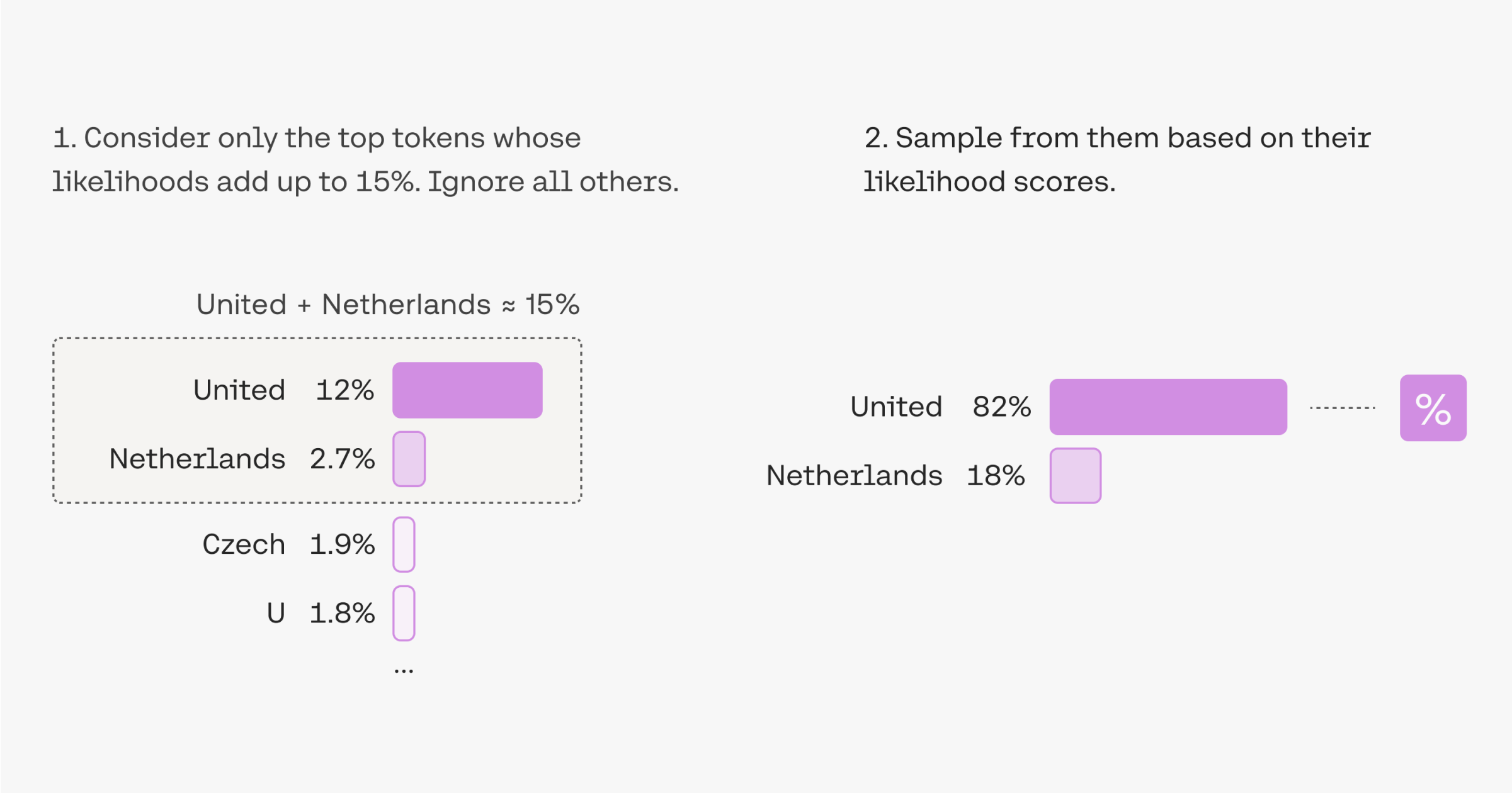
Another interesting parameter is known as logit_bias. It can be used to exclude words (or actually, tokens) from the generated response. The way it works is the following: a user can specify a bias (positive or negative) to add/subtract to the logits of a specific token generated by the model before sampling.
As stated in OpenAI's API documentation, the impact of specific values will differ depending on the individual model used. Typically, values ranging between -1 and 1 tend to decrease or increase the likelihood of a token being selected, respectively. In contrast, extreme values such as -100 or 100 are likely to result in either a complete ban or an exclusive selection of the relevant token.
More advanced techniques can be used to mitigate certain behaviors. For example, DoLa (Decoding by Contrasting Layers) is a decoding strategy for reducing hallucinations with pretrained LLMs. The approach obtains the next-token distribution by contrasting the differences in logits obtained from projecting the later layers versus earlier layers to the vocabulary space, exploiting the fact that factual knowledge in an LLMs has generally been shown to be localized to particular transformer layers.
Bear in mind that a caveat of Strategy 2 is the need to have a more granular access to the LLM (e.g. logits), because APIs don’t tend to expose everything that might be needed.
Strategy 3: post-generation control
Prompts are a flexible way to implement limitations, but they cannot guarantee that the same model will generate the same output for the same prompt.
Security guardrails are a way of letting the user add structure, type, and quality guarantees to the outputs of LLMs. Examples of guardrails include semantic validation (checking for bias or harmful content in generated text, checking for bugs in generated code, etc.) and enforcing structure and type guarantees (e.g. JSON).
This technique works with the LLMs output, providing a posteriori methods that guarantee that the output will match certain criteria: regular expressions, follow a JSON schema, be parseable into a Pydantic model, etc.
Examples
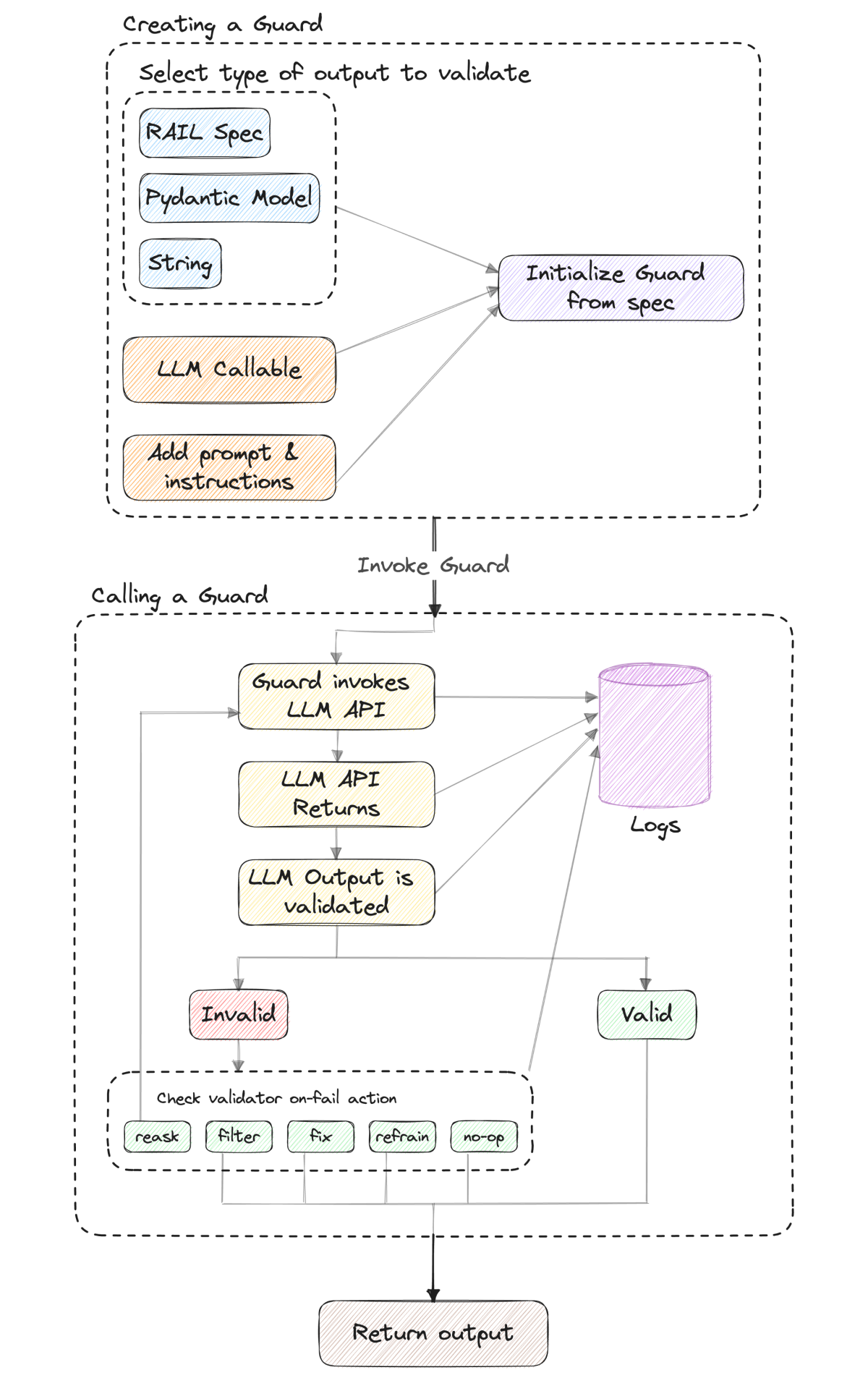
Guardrails does pydantic-style validation of LLM outputs (including semantic validation), takes corrective actions (e.g. re-asking LLM or filtering out the invalid output) when validation fails, and enforces structure and type guarantees (e.g. JSON). Under the hood, it provides a file format (.rail) for enforcing a specification on an LLM output, and a lightweight wrapper around LLM API calls to implement this spec.
Let’s review some validators from the library to better understand the kind of checks that can be applied. Some are used to check code (e.g. BugFreePython, BugFreeSQL, DetectSecrets, ExcludeSqlPredicates, SqlColumnPresence). Others have to do with text format (e.g. EndsWith, LowerCase, OneLine, RegexMatch, TwoWords) and some validate the text’s content itself (e.g. Provenance, IsProfanityFree, CompetitorCheck). Users can also create their own custom validator that enforces what the application is intended to do.
Guardrails logs all of the steps it takes to enforce the RAIL spec, which can later be inspected. Here’s a diagram with the full flow:

One validator called OnTopic can be used to verify that a response is related to a provided topic (or one of many provided topics). Under the hood, it uses an ensemble of Zero-Shot classification model combined with an LLM to determine if the condition is met. Here’s an example that illustrates how to use it:
We recently collaborated with Guardrails in the definition and implementation of some Validators, including OnTopic.
Alternatively, NeMo Guardrails (an open-source toolkit developed by NVIDIA) and Guardrail ML offer similar features.
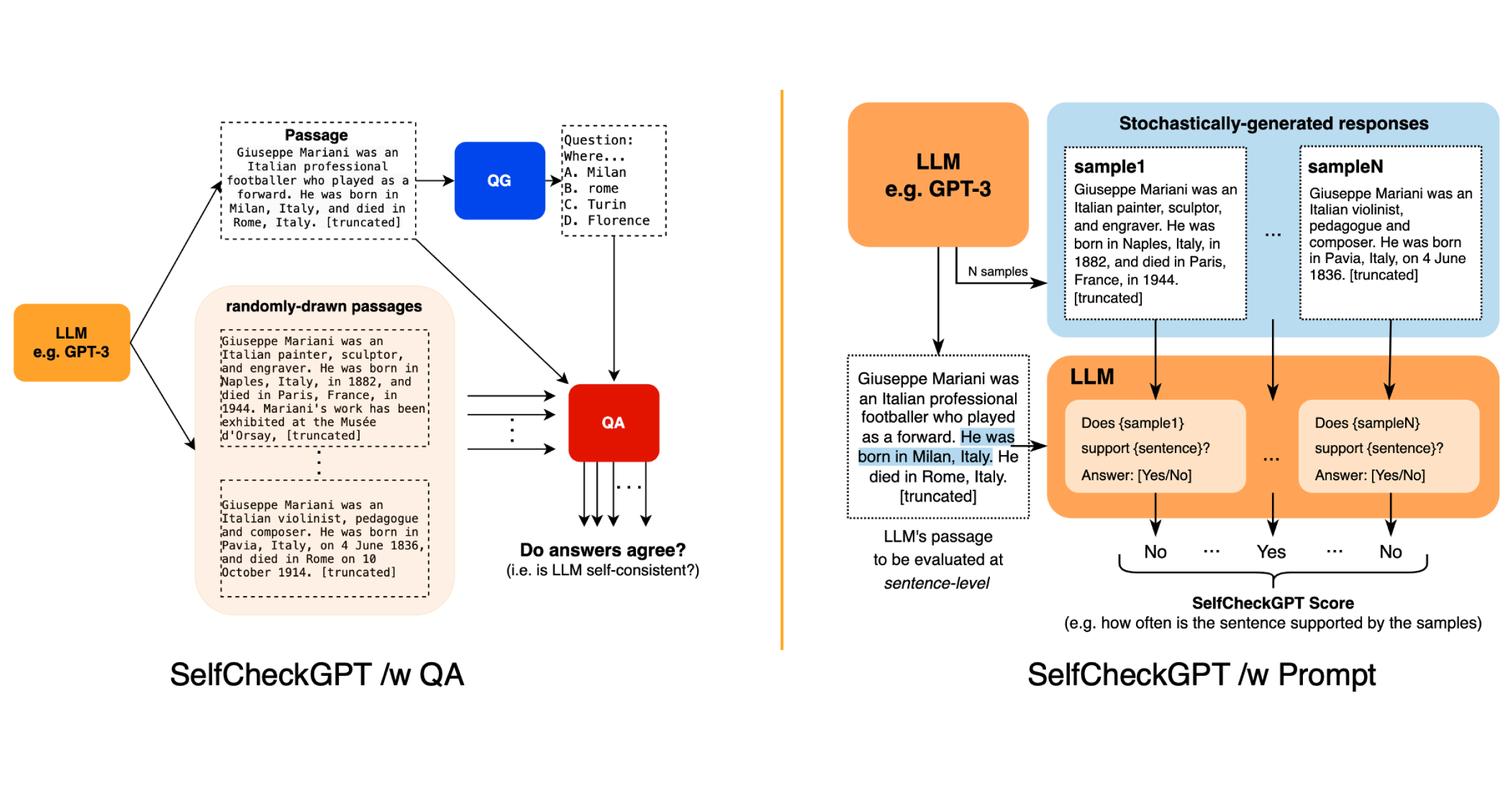
In addition to guardrails, there are countless strategies when processing the response. One example is SelfCheckGPT, a zero-resource hallucination detection solution that can be applied to black-box systems. The basic idea behind it is that if an LLM knows a given concept, sampled responses are likely to be similar and contain consistent facts. By sampling multiple responses from an LLM, one can measure information consistency between the different responses and determine if statements are factual or hallucinated.
Output parsers are a simple way to get more structured information from the LLM’s response or enforce an expected format. LangChain, a framework for developing applications powered by language models, offers an implementation and this example to illustrate how to use it:
There are other similar libraries (e.g. Guidance, JsonFormer, Outlines, Griptape) that also work by using different techniques to enforce an output format.
Conclusions
Each of these techniques has its unique strengths and weaknesses, and their applicability depends on the specific requirements of the task at hand and the kind of output filtering intended.
Prompt tuning is a powerful tool for guiding the model's output. By carefully crafting the input prompt, one can influence the model's responses. However, this method requires a deep understanding of how the model interprets prompts and may not always yield consistent results due to the inherent randomness in the model's output.
Logit filtering is a more advanced technique that involves manipulating the model's logits to prevent it from generating certain words or phrases. This method can be highly effective, but it requires a deep understanding of the model's inner workings and can be computationally expensive.
Parameter tuning, such as adjusting the temperature and top-k sampling, provides a way to control the randomness and diversity of the model's output. While these methods offer a degree of control, they do not guarantee the elimination of harmful or inappropriate content.
Guardrails are a proactive approach to limit the model's output by setting predefined rules or boundaries. This method can be effective in preventing the model from generating certain types of content. However, it may also limit the model's creativity and versatility, and there's always a risk that some unwanted content may slip through.
Parsing involves analyzing the model's output after it has been generated, allowing for the removal or modification of unwanted content. This method can be effective, but it is reactive rather than proactive, meaning that harmful or inappropriate content may be generated before it is caught and removed.
In conclusion, the choice of strategy for controlling and limiting the output of LLMs depends on the specific needs and constraints of the task at hand. A combination of these techniques may often be the best approach, providing a balance between harnessing the power of LLMs and mitigating their potential risks. Also keep in mind that if you want to limit a particular type of output, there may be more strategies for that specific behavior. For example, this survey gathers many hallucination mitigation techniques.
It's important to note that the field of controlling and limiting the output of LLMs is an active area of research. As we continue to explore the capabilities and challenges of these models, new techniques and tools are being developed continuously. This ongoing innovation is expanding our toolkit for managing LLMs, enabling us to better align these models with our goals and values. The strategies discussed in this post represent the current state of the art, but we can expect to see further advancements in the near future. As we navigate this evolving landscape, the key is to remain adaptable, continually learning and applying new methods as they emerge.

Wondering how AI
can help you?

Terms and Conditions | © 2026. All rights reserved.