

Top Python libraries of 2021



Welcome to a new edition (7th!) of our yearly Top Python Libraries list!
Starting in December 2015 — and uninterruptedly since then — we have been compiling the best Python libraries that are launched or popularized every year (or late the previous year). It all started as a "Top 10" series, but although we still have 10 main picks, we are nowadays listing so many more libraries. The work the Python community has been doing is just too good, and we want to give YOU a chance to find these great libraries in case they haven't yet crossed your path.
In case you are not a fan of most top-10-style posts, bear with us and give this a chance. This is not your typical list of obvious choices everybody knows (no numpy, pandas, or TensorFlow here). I promise most of the libraries we picked will be new to you. We do our homework!
As a final disclaimer, we are an AI Solutions company, which will become evident in the picks. If you think we have missed some great libraries, especially for folks doing full-stack development, please mention them in the comments!
Let's get started!
The 10 main picks
1. Django Ninja


For several years, Django REST Framework has been sort of the go-to option to build RESTful APIs in Django applications. But in 2021, a new contender was born.
Meet Django Ninja, a fast web framework for building APIs with Django (which recently released 4.0 by the way) and, as we've come to expect from several of these libraries, type hints!
It makes it truly simple to build a REST API in which you get type casting and validation for your parameters (thanks again to Pydantic) and documentation for free. Adding to that, autocomplete in your favorite editor just works, and the library supports async views!
Did we miss that it's also based on the OpenAPI and JSON Schema open standards that will give you that edge in interoperability?
2. SQLModel


For the third year in a row and following the success of FastAPI and Typer, tiangolo makes it to this list with SQLModel, a library for interacting with SQL databases with Python objects.
Did you guess it already? Yes, SQLModel is based on Python's type annotations and powered by Pydantic and SQLAlchemy — of which you can leverage the full power.
You'll have an ORM that looks very intuitive, has great editor support (code completion, inline errors), and also data validation and documentation. As usual, the library's documentation is top-notch. What will the surprise for next year be, tiangolo? 😂
3. Awkward Array


You might be already familiar with numpy and its arrays. They are the central data structure: basically a grid of values (matrices for 2D or tensors for higher dimensions). They enable vectorized operations over chunks of data (like broadcasting), which leverage parallelism and optimizations in low level libraries, and therefore can run much faster than regular Python for loops.
But values in NumPy arrays have to be all of the same type. They cannot express variable-length structures. Although you can set dtype to object, this is not enough.
Awkward Arrays come to the rescue. They look like regular arrays to the user, but underneath, they are a general tree-like data structure (like JSON). They will store data efficiently, contiguous in memory and operate with it using compiled, vectorized code, just like NumPy does.
Consider the example listed in the project's GitHub README:
And the following snippets:
- Using regular Python:
- Using Awkward Arrays:
Both snippets generate the same output:
But not only is 2. much more concise, it is also orders of magnitude faster and uses less memory. When paired with Numba, it can be even faster. Sweet!
4. jupytext


Jupyter Notebooks are a great tool, but writing code in a browser and losing all the features of your favorite IDE is not that great. Even worse, notebooks often mean a lot of trouble for version control and collaboration as they ultimately are stored as JSON files.
Jupytext is a Jupyter plugin that comes to solve these issues and lets you save notebooks as markdown or scripts in several languages. With the resulting, plain-text files, it's easy to share them in version control, merge changes done by other people, and even use IDEs and their nice autocomplete or type checking features.
A must-have in the arsenal of the data scientist in 2021.
(Also related, check Jupyter Ascending from our extra picks).
5. Gradio


If you are in the data science world, you have probably heard about Streamlit (which made it to our top 10 in 2019). Streamlit makes it easy to turn data scripts into shareable web apps, so you can demo your results as an actual app and not a Jupyter Notebook.
Gradio is a new tool that takes this a step further: if you want to build a demo of a ML model, it makes things even easier than Streamlit.
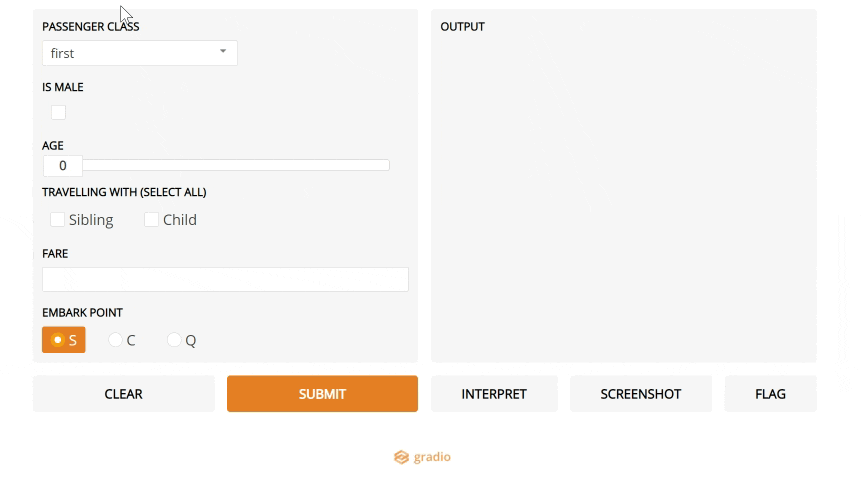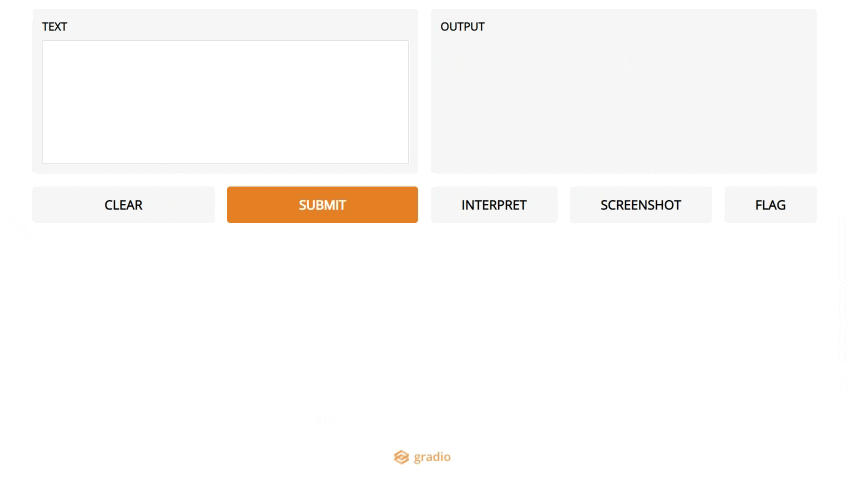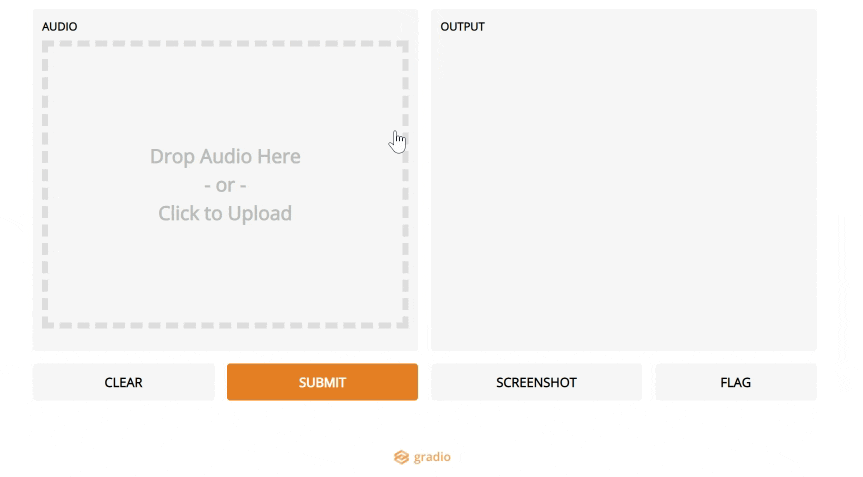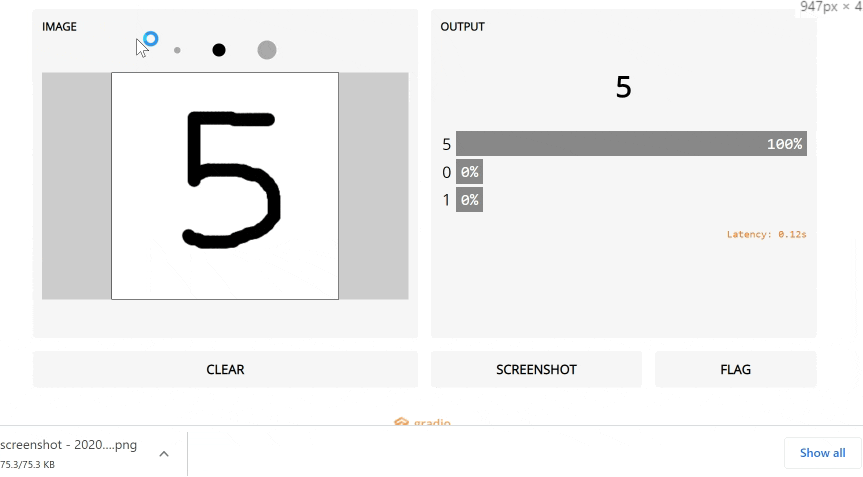 Gradio in action.
Gradio in action.It's the simplest way to create a web UI specific to your model, and let a user play around by changing parameters using sliders, or uploading images, writing text and even recording voice.
Definitely a step in the right direction to make models more accessible and data scientists focus on what matters most to them, rather than UI work.
It looks like Gradio has just been acquired by HuggingFace!
6. AugLy


Originally used for training more robust models in computer vision, data augmentation has quickly proved crucial for all machine learning disciplines. As we know, labeled data is scarce, so getting the most out of it is very important. Moreover, data augmentation is at the heart of several disciplines that have greatly advanced SoTA in 2021, like self-supervised learning.
AugLy, by Facebook Research (now Meta Research) is a data augmentation library that supports over 100 types of augmentations in audio, images, text, and video. The augmentations can be configured with metadata, and composed to achieve the effects you want.
Apart from the usual image scale, flipping, resizing or color jittering you can usually find in other libraries, there are many non-classical types of augmentation: turning images into memes or screenshots, overlaying text to images, changing some words to their emoji equivalents, or Instagram-like filters. Definitely, one to keep on your radar!
7. skweak


Until large, multi-task pre-trained multi-lingual models become great at zero-shot learning, we are going to continue needing labeled data to solve specific business problems using NLP.
But labeling data is expensive. The problem gets worse if your use case is on a language that is not English, where labeled data is more abundant.
skweak helps you solve the problem of label scarcity using a technique called weak supervision. The idea is simple: you define a set of labeling functions with some heuristics that can automatically label your document (say using gazetteers, regular expressions, or even other weak ML models), and skweak can aggregate the outputs of these into a single most likely label, using a statistical model.
It's really cool to see it in action and will save you a lot of effort in manual labeling. Also, it integrates with spaCy and therefore can be used in your existing NLP pipeline.
8. Evidently


After teams of data scientists and ML engineers have done their work for the past few months, a ML model gets into production. It starts receiving data and sending its predictions to populate very important dashboards. The ML people move to tackle some other, important problem. Business stakeholders are happy. Or should they?
In reality, there are a lot of things that can go wrong, often in unexpected ways. Maybe the kind of data that the model is receiving in production is different than what it was used for training, causing it to underperform. Maybe the data is right, but the predictions start slowly misbehaving, leading you to make all sorts of bad business decisions in the process (losing lots of money!).
Our advice: if you are going to rely on ML continuously in time, you need to have a ML monitoring system in place that will alert you when stuff goes wrong.
Welcome to Evidently, a tool that helps evaluate ML models during validation, and monitor them in production. This tool will not directly detect anomalies in the data but will help you detect what is called data drift and target drift, as well as model performance in production if you happen to obtain ground truth labels (which is often the case if there are humans in the loop).
Evidently can build interactive visual reports that can be checked manually by data scientists to make sure everything is ok, and can also generate and JSON profiles from pandas DataFrame or csv files that can be integrated into automated prediction pipelines or used with other tools.
Here is a video demonstrating the use of Evidently in a Jupyter Notebook. It makes it easy, right?
9. Jina and Finetuner


There is a quiet revolution happening behind the scenes. You surely have been using search engines like Google for a while, but might not have noticed how they are substantially better than what they were a few years ago.
What has been happening: keyword-based search is being slowly phased out.
The newcomer? Neural search. It's all about using the representations that deep neural networks can learn, to power the components of a search system. Instead of splitting your text in discrete tokens and using that for matching, neural search feeds the entire text to neural networks, which turn it into vectors. Then, the vectors in space that are closer to those, can be your matching documents. So if you search for synonyms of "please help me", you might get "I need some assistance" as the first match, even if those don't share a single word.
But it doesn't only work on text. It can work on virtually any kind of data. You can search images that match some text. You can query for images that look like other images. Audio, video... you name it.
Jina is a neural search framework that empowers anyone to build scalable deep learning search applications in minutes. It basically provides you with abstractions that will make your life much easier while implementing neural search systems, both from the code and deploy perspective. It has a distributed architecture, is scalable, and cloud-native.
Accompanying Jina, Finetuner allows you to finetune the neural network representations to get the best results for neural search tasks. It provides a web interface for the human-in-the-loop approach. First, you get results with the pre-trained NN for a batch and start selecting which results you like the most and which ones you don't. Based on this, Finetuner will adjust the weights of the NN and present to you a new batch, with results that will become increasingly better.
We are very excited to see what 2022 will bring to these libraries!
10. Hub


The unfortunate reality of data science is that the majority of time is not spent in tuning models or thinking about clever approaches to novel problems. Nope. Data scientists spend a lot of their time fetching data, putting it in the right format, and writing boilerplate code.
For dealing with important quantities of data (several GBs), there is also the need to build infrastructure code that can support each workflow.
But as the tools mature, maybe this becomes a problem of the past?
Meet Hub, a dataset format with a simple API that can help you work with any kind of dataset without worrying about where it is stored and how large it is. It makes sure the data is stored in a compressed format (chunked arrays) that are basically binary blobs that can be stored anywhere. Yes, this means you can use any storage option like AWS S3, a GCP bucket, or — if you dare — local storage, transparently and without changes in your code.
Did we mention Hub works lazily, meaning the data is only fetched when needed? You don't need to have a multi-TB hard drive to work with multi-TB datasets. There is also an API for connecting Hub datasets to your most used tools like PyTorch or TensorFlow, building pipelines, and also doing data version control. And you can do distributed transformations to your datasets. And visualize them. And, who knows what else is coming in 2022? Exciting!
Extra picks — Don't miss these
Various
- Textual — TUI (Text User Interface) framework for Python inspired by modern web development, from the author of our beloved rich.
- chime — Python sound notifications made easy.
- Jupyter Ascending — sync Jupyter Notebooks so you can type the code from your favorite code editor.
Model deployment & training
- transformer-deploy — deploy 🤗 Transformers models in production, behind an API with submillisecond inference️ time using TensorRT and Nvidia Triton.
- opyrator — turn your Python functions into production-ready microservices, powered by FastAPI, Streamlit, and Pydantic.
- koila — prevent PyTorch's
CUDA error: out of memoryin just 1 line of code.
Vision
- VISSL — a library for state-of-the-art self-supervised learning from images, by Meta Research.
- YOLOX — an anchor-free version of YOLO, a fast and accurate object detection model, with a simpler design but better performance.
- layout-parser — deep learning-based document image analysis: detect paragraphs, titles, images, and more in pages with complex layouts.
- SAHI — clever library to perform object detection in large images, without sacrificing performance, by using slicing. Supports both bounding boxes or masks by categories!
NLP / Topic modeling
- lightseq — a high-performance training and inference library for sequence processing and generation implemented in CUDA, enabling efficient computation of modern NLP models such as BERT, GPT, Transformer, and more.
- Top2Vec — automatically detects topics present in text and generates jointly embedded topic, document and word vectors.
- BERTopic — leverages 🤗 Transformers and c-TF-IDF to create dense clusters allowing for easily interpretable topics whilst keeping important words in the topic descriptions.
Time series
- Greykite — flexible, intuitive and fast forecasts through its flagship algorithm, Silverkite, which provides interpretable forecasts. By LinkedIn.
- Kats — toolkit for time series analysis, from understanding the key statistics and characteristics, detecting change points and anomalies, to forecasting. By Meta Research.
- Merlion — an end-to-end machine learning framework for loading and transforming data, building and training models, post-processing model outputs, and evaluating model performance, supporting several tasks.
- Spice.ai — for developers who want to build intelligent applications leveraging time series data without too much hassle.
Graphs / Geospatial / Spatiotemporal
- prettymaps — a small set of Python functions to draw pretty maps from OpenStreetMap data.
- TorchGeo — torchvision for geospatial data, providing datasets, transforms, samplers, and pre-trained models. By Microsoft.
- pytorch_geometric — easily write and train Graph Neural Networks (GNNs) for a wide range of applications related to structured data, built on PyTorch.
- nodevectors — fast and scalable node embedding algorithms.
- PyTorch Geometric Temporal — temporal (dynamic) extension library for PyTorch Geometric.
Audio
- pedalboard — Spotify's library for programmatically adding effects to audio.
- SpeechBrain — an all-in-one speech toolkit based on PyTorch.
Metric learning
- PyTorch Metric Learning — the easiest way to use deep metric learning in your application. Modular, flexible, and extensible. Implements several losses, distance metrics, miners, and more.
- TensorFlow Similarity — Google's take on their tool for metric and contrastive learning.
Optimization
- Hyperactive — optimization and data collection toolbox for convenient and fast prototyping of computationally expensive models.
- Gradient-Free-Optimizers — simple and reliable optimization with local, global, population-based and sequential techniques in numerical discrete search spaces
- higher — PyTorch library allowing users to obtain higher-order gradients over losses spanning training loops, by Meta Research.
Explainability / monitoring / causality
- Ecco — visualize and explore NLP language models.
- explainerdashboard — quickly deploy a dashboard web app that explains the workings of a (scikit-learn compatible) machine learning model.
- Transformers Interpret — explain models in the 🤗 transformers package with 2 lines of code.
- Shapley — various methods to compute (approximate) the Shapley value of players (models) in weighted voting games (ensemble games).
- UpliftML — uplift modeling, great for studying causality in personalization/marketing.
Reinforcement learning
- maro — Multi-Agent Resource Optimization (MARO) platform is an instance of Reinforcement learning as a Service (RaaS) for real-world resource optimization. By Microsoft.
Some worthy misses from 2020 (sorry!)
- pqdm a parallel version of tqdm (widely used progress bar for Python and CLI).
- AutoScraper — a neat library implementing auto scraping using clever ideas that don't require you to write or maintain selectors or XPath expressions.
- Aim — easy-to-use and performant open-source experiment tracker.
- NeuralProphet — NN-based time series model, inspired by Facebook Prophet and AR-Net, built on PyTorch.
- glacier — build Python CLIs really easily, using type hints.
- Haystack — an open-source NLP framework that leverages Transformer models to implement production-ready neural search, question answering, semantic document search and summarization for a wide range of applications.
- MPIRE — an almost drop-in replacement for multiprocessing, will save you from writing a lot of code for things you probably need when designing applications leveraging multiprocessing: init and exit functions for workers (where for example you can handle stuff like DB connections), managing of worker state and handling of exceptions. It also has a nice feature where you can pass objects as copy-on-write.

Wondering how AI
can help you?

Terms and Conditions | © 2026. All rights reserved.