

Top Python libraries of 2022




Welcome to the 8th edition of our Top Python Libraries list!
We are excited to present this year's picks for the most innovative developments in the Python ecosystem. From this edition, we are expanding our list to include not only libraries per-se, but also tools that are built to belong in the Python ecosystem — some of which are not written in Python as you’ll see.
The rules for selection are the same as in previous years. We are looking for libraries that were launched or gained popularity in the past year, are well-maintained, and are simply cool and worth checking out. Our picks are heavily influenced by AI and data science libraries, but we also include a number of libraries that can be useful for non-data science purposes.
In addition to our main picks, we have also included an "Extra picks" section with a longer tail of libraries that we are sure many of you will find interesting.
We hope that this list will showcase not only the best of what the Python community has to offer but also spark discussion about the libraries and tools that we may have missed. And unavoidably we do miss some every year, that's why we add the Misses from 2021 section as well.
Without further ado, let's get started!
The 10 main picks
1. Ruff — a fast linter
Was there anyone who did not use a linter in 2022?
Through the years, the community has come to acknowledge that linters are an essential part of the software development process. They analyze source code for potential errors and style issues, providing valuable feedback and suggestions for improvement. Ultimately, they help developers write cleaner, more efficient code. In order to make the most of this process, it is important to have a linter that is fast and effective. This is where Ruff comes in.
Ruff is an extremely fast Python linter that is written in Rust. It is 10-100x faster than existing linters and can be installed via pip.

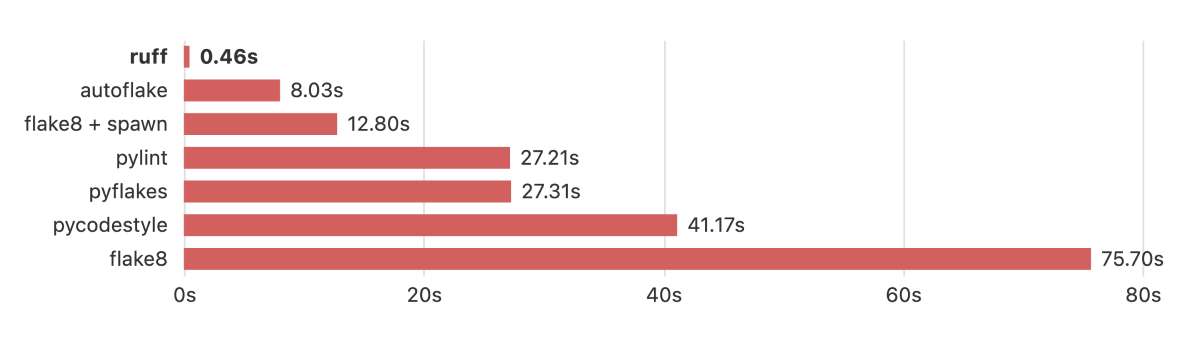
In addition to linting, Ruff can also be used as an advanced code transformation tool, capable of upgrading type annotations, rewriting class definitions, sorting imports, and more.
It is a powerful tool that aims to replace a variety of other tools, including Flake8, isort, pydocstyle, yesqa, eradicate, and even a subset of pyupgrade and autoflake, all while executing at lightning fast speeds.
Definitely a big highlight to add to your arsenal going into 2023!
2. python-benedict — a dict on steroids
Dictionaries are a vital data structure in Python, but working with complex dictionaries can be a challenge. The built-in dict type is powerful, but it lacks many features that make it easier to access and manipulate nested values or convert dictionaries to and from different data formats. If you've found yourself struggling to work with dictionaries in Python, python-benedict could be the solution you've been looking for.
benedict is a subclass of the built-in dict type, meaning that it is fully compatible with existing dictionaries and can be used as a drop-in replacement in most cases.
One of the key features of benedict is its support for keylists and keypaths. This makes it easy to access and manipulate values in complex dictionaries without having to manually dig through nested levels. For example:
In addition to its keylist and keypath support, benedict also provides a wide range of I/O shortcuts for working with various data formats. You can easily read and write dictionaries to and from formats such as JSON, YAML, and INI, as well as more specialized formats like CSV, TOML, and XML. It also has support for multiple I/O operations backends such as filepath (read/write), url (read-only),and s3 (read/write).
It has a gazillion more features, so make sure to check out the readme.
3. Memray — a memory profiler

Optimizing the memory usage of your systems is vital for improving their performance and stability. Memory leaks can cause programs to consume increasing amounts of memory, degrade overall system performance and eventually crash. Although garbage-collected and generally easy to work with, Python does not shield you from these issues. Nothing prevents circular references or unreachable objects (for more on this, read on how garbage collection works); even more so if we talk about C/C++ extensions.
A memory profiler can help you identify and fix these issues, making it an essential tool for optimizing the memory usage of your programs. This is where Memray comes in handy!
It is a memory profiler that tracks memory allocations in Python code, native extension modules, and the Python interpreter itself, providing a comprehensive view of memory usage. Memray generates various reports, including flame graphs, to help you analyze the collected data and identify issues such as leaks and hotspots. It is fast and works with Python and native threads, making it a versatile tool for debugging memory issues in multithreaded programs.
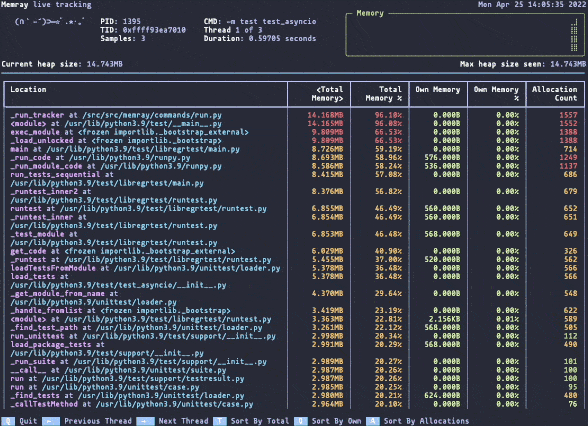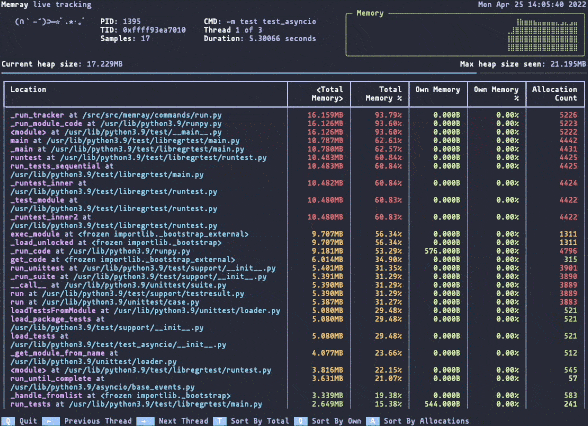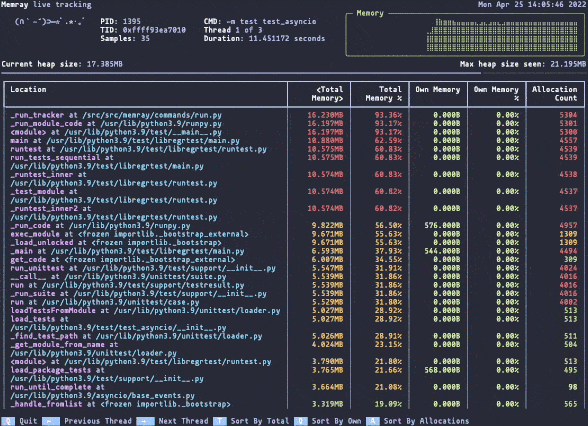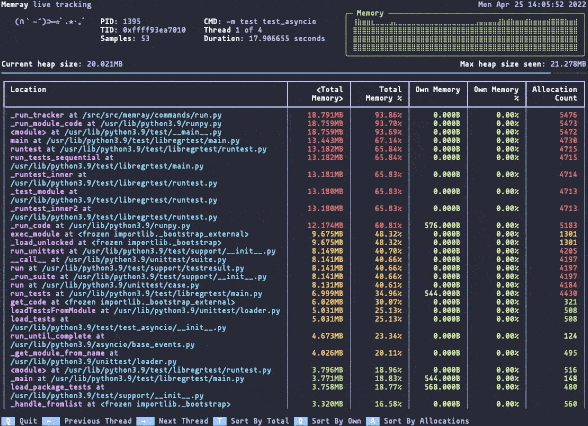 Memray live mode.
Memray live mode.Memray can be used as a command line tool or as a library for more fine-grained profiling tasks. Its live mode allows you to interactively inspect memory usage while a script or module is running, making it useful for debugging complex memory patterns.
A must-have tool by Bloomberg for the serious Python programmer.
4. Codon — a Python compiler using LLVM


We all love Python for its simplicity and ease of use, but sometimes we need a little extra runtime speed. Even with all the optimizations, Python interpreters (like CPython) can only go so far. When performance needs to be pushed even further, compilers come in. They convert our Python code into machine code that can be directly executed by the processor, skipping the interpreter step and giving us some serious performance boosts.
Codon is a high-performing ahead-of-time Python compiler that can even compete with C/C++ in terms of speed, with typical speedups reported to be 10-100x or more (on a single thread). It can be used within a larger Python codebase using the @codon.jit decorator or by calling plain Python functions and libraries from within Codon using Python interoperability.
There is no free lunch here, so you will likely have to make some modifications to your Python code so that it can be compiled by Codon. But the restrictions that Codon imposes over the language are what ultimately allow for the performance gains. Nevertheless, the compiler will guide you by producing detailed error messages that identify and help you resolve incompatibilities.


It's definitely worth checking out if you're looking to speed up your code. The FAQ is very informative for getting a quick glance at what this tool will do for you.
5. 🦜️🔗 LangChain — building LLM-powered apps
Unless you have been living under a rock, you are well aware that generative AI has been taking the world by storm this year. A large chunk of this is Large Language Models (LLMs).
A lot of code that we have written over these past years to solve AI problems can be just thrown away and replaced with a LLM (like GPT-3 or its evolutions — InstructGPT or ChatGPT — T5, or any other). Also, we have witnessed the birth of a new programming language for the LLM interface: text-based prompts.
LangChain comes in to help leverage the full power of LLMs.
First: in any serious use of LLM, one does not typically need to think of prompts as a one-off thing but rather a combination of things: templates, user input, and input/output examples that the LLM can take as reference. LangChain helps you streamline this “prompt management” by providing interfaces for building different prompts based on the individual components straightforwardly.
Second, for building the prompts, sometimes you need to inject external knowledge (or even other models). For example, imagine you need to perform a database query to extract a customer’s name for a personalized email. This is the concept of chains, and LangChain provides a unified interface for this.
Then there’s the concept of fetching and augmenting data so the LLM can work over your own data, contrary to the “generic” data over which the models are trained.
There are more things you can do with LangChain, such as being prepared to switch to another model/provider without changing your code, building agents with memory, etc.
Certainly, an innovative tool that we expect will grow a lot in 2023!
6. fugue — distributed computing done easy

If you're familiar with Pandas or SQL, you know that these tools are great for working with small to medium-sized datasets. But when dealing with larger amounts of data, you often need a distributed computing framework like Spark to process it efficiently. The thing is, Spark is a whole different beast from Pandas or SQL. The syntax and concepts are completely different, and it can be a challenge to migrate your code from one to the other. That's where Fugue comes in.
Fugue is a library that makes it easier to work with distributed computing frameworks like Spark, Dask, and Ray. It provides a unified interface for distributed computing that lets you execute Python, pandas, and SQL code on Spark, Dask, and Ray with minimal rewrites.
The best starting point is using Fugue’s transform() function. It lets you parallelize the execution of a single function by bringing it to Spark, Dask, or Ray. See the following example where the map_letter_to_food() function is brought to the Spark execution engine:
Fugue allows you to maintain one single codebase for Spark, Dask and Ray projects where logic and execution are completely decoupled, saving programmers from having to learn each of the different frameworks.
The library also has several other interesting features and a growing community, so make sure to check it out!
7. Diffusers — generative AI

2022 will always be remembered as the year when generative AI breached the frontiers of the AI community and expanded to the outside world. This was largely powered by Diffusion models, which gained much attention thanks to their impressive capabilities in generating high-quality images. DALL·E 2, Imagen, and Stable Diffusion are just a few examples of diffusion models that have made waves this year. Their results inspired discussion and admiration for their ability to generate images that push the boundaries of what was previously thought possible — even by AI experts.
Hugging Face's Diffusers library is a collection of tools and techniques for working with diffusion models, including the Stable Diffusion model, which has proven particularly effective at generating highly realistic and detailed images. The library also includes tools for optimizing the performance of image-generation models and analyzing the results of image-generation experiments.
Starting to use this library for text-to-image generation may be as simple as dropping these few lines of code:
But Diffusers doesn’t stop with images. Features for audio generation and even molecule generation (!) are coming soon.
It looks like most open-source implementations of Diffusion models will leverage the building blocks provided by this library. Sweet!
8. LineaPy — convert notebooks to production pipelines

Jupyter notebooks are an extremely useful tool for prototyping and developing code. They allow you to easily mix code, plots, media, and interactive widgets in a single document, making it easy to document and understand your code as you develop it. They are the perfect playground for experimenting with code and testing out ideas, which can be especially handy for data analysis and machine learning tasks. But as the ideas progress and one is happy with the result and wants to put code into production, challenges start to show.
Code within notebooks may not always be structured in a way that is easy to deploy to a production environment. Should you take the notebook’s code and rewrite it elsewhere, modularize it and make it follow the best practices? This is the most common approach, but the drawback is that if, later down the road, you want to improve or debug something, you lost the interactivity of the notebook. So now you have to maintain both a notebook and separate production code, which is far from ideal.
There is a path to do better, thanks to LineaPy.
LineaPy is a Python library that helps you move quickly from prototyping to creating robust data pipelines. It takes your messy notebook and helps clean up and refactor code, making it easier to run in an orchestration system or job schedulers, such as cron, Apache Airflow, or Prefect.
It also helps with reproducibility: it has the concept of “artifacts” that encapsulate both data and code that can help you trace back how values were produced. At a high level, LineaPy traces the sequence of code execution to form a comprehensive understanding of the code and its context.
The best part? It’s very simple to integrate, and can run in a Notebook environment with just two lines of code!
Make sure to check out the documentation, which does a great job showcasing the problems the tool solves with very comprehensive examples.
9. whylogs — model monitoring

As AI models make their way to produce actual value for a business, their behavior in production must be monitored continuously to make sure that the value is sustained over time. That is, one must have a way to tell that model predictions are reliable and accurate and that the inputs that are being fed to the model do not deviate significantly from the type of data that was used to train it.
But model monitoring is not just limited to AI models — it can be applied to any kind of model, including statistical and mathematical models. Hence the usefulness of this pick.
whylogs is an open-source library that enables you to log and analyze any kind of data. It provides a range of features, starting with the ability to generate summaries of datasets: whylogs profiles.
The profiles capture statistics over the original data, such as distribution, missing values, and many other configurable metrics. They are computed locally using the library and can even be merged to allow for analysis over distributed and streaming systems. They form a representation of the data that conveniently does not need to expose the data itself, but only metrics derived from it — which is good for privacy.
Profiles are straightforward to generate. For example, to generate a profile from a Pandas DataFrame you would do:
But profiles are only as useful as what you decide to do with them. For this, visualization is a must. You can install the viz module using pip install "whylogs[viz]" which can create interactive reports for you. Here’s a sample drift report inside a Jupyter Notebook:

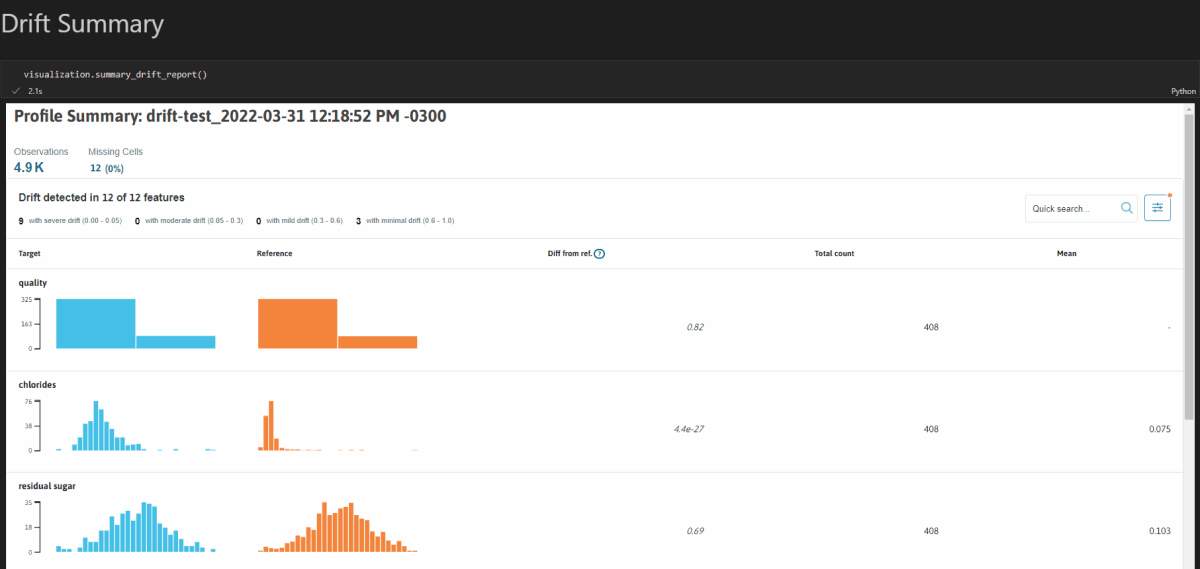
You can also set constraints so that you are notified when data doesn’t match the expectations, effectively doing some kind of testing on your data/model. After all, isn’t this what we were set to do from the beginning?
If you prefer managed solutions (remember you do not need to share your data, but only statistics!), you can opt for the parent company’s SaaS ML monitoring and AI observability platform, which will make setting all this up very easy and also has a free starter edition. Nice!
10. Mito — spreadsheet inside notebooks

In the era of data science, many people are transitioning from analyzing data manually in spreadsheets to wring code to do that. But there’s no denying that spreadsheets are an attractive tool, providing a streamlined interface for editing and immediate feedback that allows for fast iterations.
Many times, we process data using spreadsheets. But if we want to do the same thing again over new data, we must start from scratch! Code is so much better at this, saving us precious time.
Could we get the best of both worlds? Meet Mito.
Mito comes in handy as it is a library that allows you to work with data in a spreadsheet-like interface within Jupyter Notebooks. It allows you to import and edit CSV and XLSX files, generate pivot tables and graphs, filter and sort data, merge data sets, and perform a variety of other data manipulation tasks.
And the most important feature: Mito will generate Python code that corresponds to each of your edits!
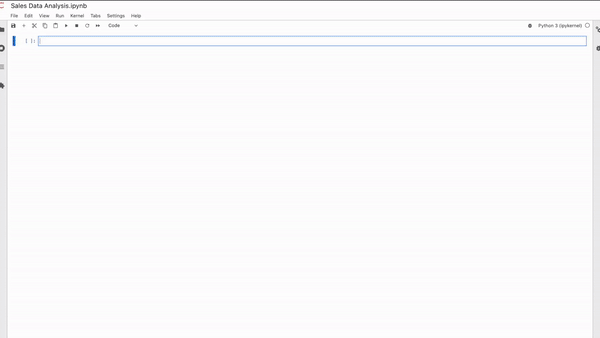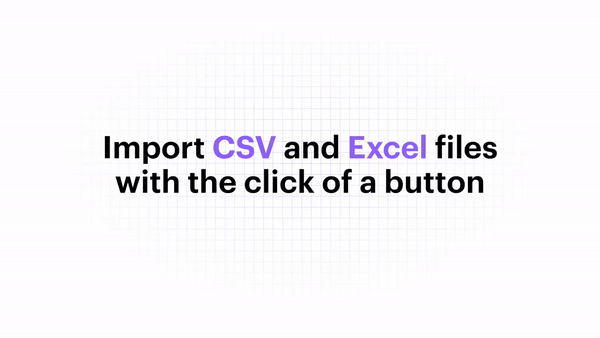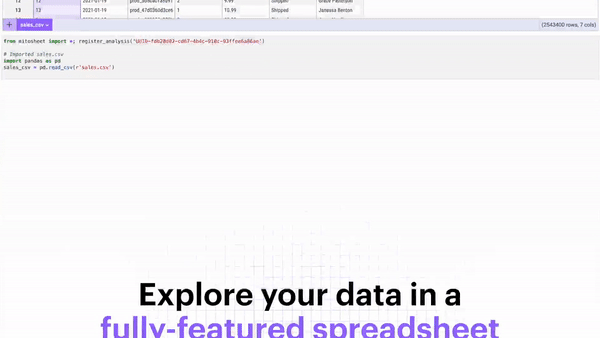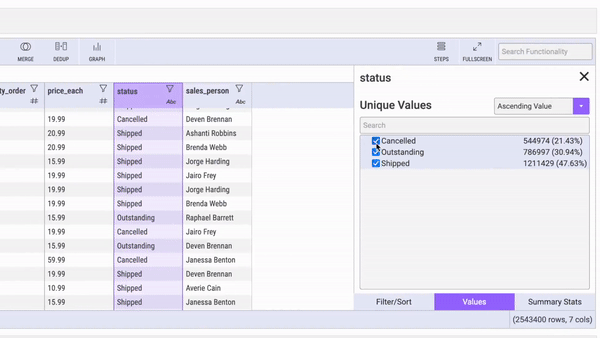 How Mito works.
How Mito works.Mito also supports the use of Excel-style formulas and provides summary statistics for columns of data. It’s designed to be the first tool in the data science toolkit, meaning it’s built to be a user-friendly tool for data exploration and analysis.
Tools like Mito lower the barrier of entry to the data science world, allowing people familiar with software such as Excel or Google Sheets (nearly everyone?) to start contributing code fast, and therefore deserves a spot in our top 10 picks this year.
Extra picks aka the long tail — don’t miss these
Non-AI
- Neutron — native Python apps along with CSS and HTML for frontend design.
- CustomTkinter — modern and customizable Python UI-library based on Tkinter.
- Pyxel — retro game engine for Python.
Tools & enablers
- Feathr — an enterprise-grade, high-performance feature store for your AI models. By LinkedIn.
- Hugie — CLI interface for working with Hugging Face’s Inference Endpoints API.
- InvokeAI — a Stable Diffusion toolkit, fork of the original but with several more features like an interactive Web UI.
- Kangas — exploring, analyzing, and visualizing large-scale multimedia data.
- Lance — alternative to Parquet. 100x faster for random access, automatic versioning, optimized for ML data. Apache Arrow and DuckDB compatible.
- Marqo — an open-source tensor search engine that seamlessly integrates with your applications, websites, and workflow.
- Mercury — convert Jupyter Notebooks to web apps and share with non-technical users.
- MLEM — a tool to package, serve, and deploy any ML model on any platform. By Iterative AI (creators of DVC).
- Stable Diffusion web UI - browser interface based on Gradio library for Stable Diffusion, with a lot of features.
LLMs and the CLI
All of these are handy Python tools to basically ask GPT-3 (or its variants) to output commands for the shell, based on human-language prompts:
Torch-X
- TorchMultimodal — PyTorch domain library for training SoTA multi-task multimodal models at scale. Modular and composable building blocks plus examples. See launch blog post. By Meta.
- TorchRec — for recommendation systems, providing common sparsity and parallelism primitives, enabling researchers to build state-of-the-art personalization models and deploy them in production. See launch blog post. By Meta.
- TorchScale — allow researchers and developers to scale up Transformers efficiently and effectively.
- TorchView — visualize PyTorch models as graphs using Graphviz.
Computer Vision
- pybboxes — convert between different formats of bounding boxes for computer vision applications.
- super-gradients — easily train or fine-tune SOTA computer vision models with one open source training library. By Deci.ai.
- video-transformers — fine-tuning models for video classification.
NLP
- Lingua — accurate language detection for +75 languages both in long and short texts.
- PyChatGPT — Python client for the unofficial ChatGPT API, which doesn’t require a headless browser. This isn’t official and is bypassing the ever-evolving protections of the OpenAI site, so you can call ChatGPT programmatically. Use it while it works; it might break soon!
- SetFit — an efficient and prompt-free framework for few-shot fine-tuning of Sentence Transformers.
Distributed / large model training / scale
- ColossalAI — efficient distributed learning.
- DeepSpeed — a deep learning optimization library that makes distributed training and inference easy, efficient, and effective. By Microsoft.
- voltaML — open-source lightweight library to accelerate your machine learning and deep learning models. Optimize, compile and deploy your models to your target CPU and GPU devices, with just one line of code.
Interpretability
- FastTreeSHAP — fast implementation of the TreeSHAP algorithm in the SHAP package, for interpreting tree-based models. Blog post.
- surgeon-pytorch — inspect and extract intermediate layers of PyTorch models.
Others
- anomalib — anomaly detection library with SOTA algorithms and features such as experiment management, hyper-parameter optimization, and edge inference.
- bayesian-statistics-toolbox — a library of functions for running sophisticated Bayesian analyses in a simple, straight forward manner.
- open-metric-learning — a PyTorch-based framework to train and validate the models producing high-quality embeddings.
- poniard — find out the best scikit-learn model by fitting them all and comparing them (not AutoML!).
Misses from 2021 (sorry!)
- Argilla — data-centric NLP, build datasets in less time.
- AutoViz — visualize any dataset, any size with a single line of code.
- Contextualized Topic Models (CTM) — use pre-trained representations of language (like BERT) to support topic modeling.
- FairScale — large-scale distributed training on PyTorch.
- FiftyOne — open-source tool for building high-quality datasets and computer vision models. Get hands-on with your data, visualize labels, evaluate models, explore, find annotation mistakes, and more.
- Ivy — attempt to unify all ML frameworks. Currently supports JAX, TensorFlow, PyTorch, and Numpy. Soon, automatic code conversions and multi-framework support.
- Jury — evaluate performance of NLP models (see blog post).
- Ploomber — fast way to build data pipelines and deploy anywhere.
- Shapash — make machine learning interpretable and understandable by everyone. Live demo.
- Small-Text — state-of-the-art active learning for text classification.
- WeaSEL — based on the End-to-End Weak Supervision paper (NeurIPS 2021), allows you to train your favorite neural network for weakly-supervised classification.
- WeightWatcher — predict performance of neural networks without access to training or test data, solely based on theory and statistical properties of the intermediate layers. Original version from earlier than 2021, but it’s getting a lot of development and traction this year!

Wondering how AI
can help you?

Terms and Conditions | © 2026. All rights reserved.