

Top Python libraries of 2023




Welcome to the 9th and not-yet-quite-a-decade edition of our yearly Top Python Libraries list! As we journey through the constantly evolving landscape of Python development, it's time again to spotlight the standout libraries and tools that have caught our attention this year. Since our first edition in 2015, we’ve dedicated ourselves to exploring the depths of the Python ecosystem, and this year is no exception. In fact, it's special — 2023 marks the boom of Generative AI and Large Language Models (LLMs), a trend that has significantly influenced our picks.

Our criteria remain consistent: we're on the lookout for libraries and tools that have been launched or risen to prominence over the past year. To qualify for our top picks, they need to be well-maintained, innovative, and, of course, cool enough to spark your interest. This year, you'll notice an emphasis on libraries that align with the LLM wave, reflecting how these technologies are reshaping the Python (or should we say programming?) landscape.
But fear not, diversity in our selection is still key! Although getting increasingly more difficult every year, we tried to ensure that our full list is not just for AI enthusiasts but also contains gems that can be valuable for a wide range of Python developers, including some niche applications.
Our aim with this post is also to ignite conversations about the remarkable libraries and tools that we might have overlooked.
So, with eager anticipation, let's dive into the world of Python in 2023!
The 10 main picks
1. LiteLLM — call any LLM using OpenAI format, and more


Imagine a world where you're not tethered to a specific model provider, where switching between LLMs is as easy as changing one or zero lines of code, contrary to rewriting your entire stack using tools like LangChain. LiteLLM makes this a reality.
LiteLLM's intuitive and non-intrusive design allows seamless integration with various models, providing a unified format for inputs and outputs, regardless of the underlying LLM. This flexibility is a game-changer for developers who need to adapt quickly to the rapidly changing landscape of large language models.
But LiteLLM isn't just about flexibility; it's about efficiency and control. Features like streaming responses and mapping exceptions to OpenAI’s format demonstrate its robustness. The ability to track and manage costs across different LLMs is particularly noteworthy, ensuring that your AI explorations don't lead to unexpected bills. This level of financial control is vital in a domain where API calls can quickly accumulate costs.
Furthermore, LiteLLM comes with a proxy API server, enhancing its versatility in integrating on codebases without changing a single line of code ✨.
Another differentiating feature is the built-in load balancing and rate limiting features. These capabilities ensure optimal performance and resource utilization, especially when dealing with high volumes of requests across multiple inference calls. Load balancing efficiently distributes incoming API calls, preventing any single model provider from becoming a bottleneck. Meanwhile, the rate limiting function plays a crucial role in maintaining stable and controlled access to the models, safeguarding against excessive usage and potential overloads (forget HTTP 429).
Of course, the devil is in the details: prompting will work differently for different LLM providers, so you will need to do some work if you truly want to utilize different providers. But it’s good to have a layer that you can rely on to make the switch as easy as possible.
Cheers and congrats to the LiteLLM authors. Whether you're a seasoned AI developer or just starting out playing with Generative AI, LiteLLM is a library that belongs in your toolkit!
2. PyApp — deploy self contained Python applications anywhere
Python's surge in popularity over the years is no secret. Its blend of simplicity and effectiveness, coupled with a vast and friendly community, has made it one of the most widely used programming languages globally. Yet, distributing Python applications remains a long-standing challenge. Unlike other languages that allow distribution of standalone compiled binaries, Python has struggled in this area, especially when targeting non-technical users. Traditionally, Python applications are shared via Docker container images, a method not always accessible to all users.
Enter PyApp: a utility library that simplifies the distribution and installation of Python applications. It achieves this by embedding Python within a self-installing package that is compatible across all operating systems. But it doesn't stop there! PyApp also supports self-updating capabilities, and can be customized to accommodate a variety of use cases.
With PyApp, specifying dependencies for pip installation via requirements.txt files is a breeze, and additional artifacts can be seamlessly embedded into the package using .in files. The library handles the installation process, creating a dedicated directory for Python and the app's required dependencies. On subsequent runs, PyApp checks for the existence of this installation directory, optimizing command-line interface responsiveness.
It differentiates from other tools you might know like PyInstaller in the fact that PyApp doesn’t do dependency discovery but rather relies on an explicit declaration of dependencies which seems to solve some issues users have been facing.
In a nutshell, PyApp presents a straightforward yet potent solution for delivering Python applications to your users. It streamlines distribution and installation procedures, eliminating the hurdles typically associated with these processes. As we look forward to 2024, PyApp is undoubtedly a tool worth adding to your Python arsenal, making the distribution of Python apps as easy as pie!
3. Taipy — build UIs for data apps, even in production


In the wise words of fashion designer Giorgio Armani, "Elegance is not about being noticed, it's about being remembered". This philosophy is the guiding star of Taipy, a Python library that empowers data scientists to weave engaging narratives from their data.
In the realm of data science, the art of storytelling can be as crucial as the underlying models. And having the right tool can make all the difference. That is Taipy’s game. Taipy is a low-code Python library that enables data scientists to build interactive Web UIs for their machine learning products, without the need to master web stack tools. It's all about allowing data scientists to focus on what they do best - extracting insights from data.
Taipy's magic lies in its ability to bind variables and expressions to the state of visual components in the UI. This binding happens in-place when declaring the visual components, drastically reducing boilerplate code needed to develop your app. And speaking of visual components, Taipy offers a rich array of options, including plots, sliders, and image grids, to help you build next-gen UIs.
But wait, didn’t we have Streamlit (our pick #7 of 2019) for that? Well, that’s where Taipy shines. Unlike Streamlit, which reruns code for the entire page upon detecting an input change, Taipy employs callbacks to update only the components affected by the change (much like shiny does for R for those coming from our brother language) enhancing responsiveness and accelerating development.
But the innovation doesn't stop there. Taipy also provides tools for visually composing machine learning pipelines, speeding up development while offering an easy way to explain at a high level the steps your model takes. Importantly, data nodes, the inputs to these visual pipelines, can be dynamically changed, enabling interactive exploration and what-if scenarios.
Whether you choose to self-host your Taipy applications or use Taipy Cloud for serverless deployment, you're in for a seamless experience. Taipy helps you unveil the stories hidden in your data and create memorable, interactive machine learning workflows. Check it out today!
Here’s their 2023 PyData Seattle presentation and here’s their launch post on HackerNews; be sure to check the discussion for some interesting information nuggets on the lib.
4. MLX — machine learning on Apple silicon with NumPy-like API
In 2021 Apple introduced it’s M1 architecture, now further refined into the current M3, a revolutionary piece of hardware that brought along performance and efficiency improvements, as well as a unified memory buffer that can be accessed by the CPU, GPU and NPU (Apple’s Neural Engine) without the need to copy information between processing units.
In 2023, the spotlight is on Apple's MLX, a groundbreaking array framework specifically designed for machine learning on Apple silicon. Brought to you by Apple's own machine learning research team, MLX is setting new standards for the development and deployment of machine learning models on Mac hardware.
MLX is designed to retain familiarity: its Python API is a close cousin of NumPy's, and it also offers a fully-featured C++ API that mirrors its Python counterpart. Higher-level packages like mlx.nn and mlx.optimizers follow the footsteps of PyTorch, making the construction of complex models a breeze.
But MLX is more than just a familiar face. It introduces innovative features like composable function transformations, enabling automatic differentiation, automatic vectorization, and computation graph optimization. It also employs lazy computation, materializing arrays only when needed, and dynamic graph construction, making debugging more intuitive and avoiding slow compilations due to changes in function argument shapes.
MLX's multi-device capability allows operations to run on any supported processing unit, be it CPU, GPU or NPU. And here's the game-changer: MLX's unified memory model. Unlike other frameworks, MLX arrays exist in shared memory, enabling operations on any supported device without the need for time-expensive data transfers.
This user-friendly yet efficient framework is designed by machine learning researchers for machine learning researchers. Inspired by the likes of NumPy, PyTorch, Jax, and ArrayFire, MLX aims to make it easy for researchers to extend and improve the framework, fostering rapid exploration of new ideas.
As we move towards 2024, MLX is definitely a toolkit to keep an eye on. Whether you're an Apple aficionado, a machine learning enthusiast, or both, MLX is poised to revolutionize your machine learning journey and utilize the capabilities of Apple silicon to the fullest.
5. Unstructured — the ultimate toolkit for text preprocessing


In the vast landscape of AI, a model is only as good as the data it feeds on. But what happens when your data is a chaotic jumble of raw documents, scattered across various formats? Enter Unstructured, a comprehensive solution for all your text preprocessing needs.
Unstructured is the master key to unlock the potential of your raw data, capable of digesting anything thrown at it — PDFs, HTML files, Word documents, even images. It's like a gourmet chef for your data, slicing and dicing it into palatable pieces for your AI models.
Unstructured offers a smorgasbord of functions, neatly categorized into six types:
- Partitioning Functions that transform raw documents into structured and standardized formats.
- Cleaning Functions that scrub away unwanted text, leaving behind only the relevant nuggets.
- Staging Functions that format your data, readying it for ML tasks like inference or labeling.
- Extraction Functions that mine for valuable information within documents, like emails, IP addresses, or pattern-matched texts.
- Chunking Functions that break down documents into bite-sized sections, perfect for similarity searches and RAG.
- Embedding Functions that convert preprocessed text into vectors, offering easy-to-use interfaces.
But that's not all. Unstructured also comes equipped with Connectors, a set of tools for seamless integration with various storage platforms. From GCS and S3 to Google Drive, One Drive, Notion, and many more. These Connectors work both ways, allowing you to read and write information to and from a plethora of sources.
Unstructured is your go-to Python library for effortless text extraction from documents. It simplifies text cleansing, handling everything from bullet removal to emoji management and language translation. Its extractor functions parse cleansed text, retrieving valuable information. You can use built-in extractors or custom templates for structured text.
The library's staging functions save preprocessed documents in diverse formats, compatible with various tools like Label Studio and Prodigy. It also features a chunker that groups texts by their title building cohesive, related sections and embedding functions for easy text vectorizing using popular LLM models.
With Unstructured in your toolkit, your journey into the world of Large Language Models is set to be a rewarding one. Get ready to unlock the full potential of your data in 2024!
6. ZenML and AutoMLOps — portable, production-ready MLOps pipelines


Alright, we're bending the rules a bit here. Two libraries, one entry. But trust us, it’ll be worth it.
MLOps is a crucial link between machine learning model development and operations. It enables a smooth transition from experimental to production-ready models. Without MLOps, organizations face navigating a minefield of inefficiencies, wasted resources, and unreliable predictions. It ensures model reproducibility, scalability, and monitoring, transforming brilliant ideas from mere theories into valuable solutions. Thus, effective MLOps is the backbone of successful machine learning initiatives.
However, setting up an effective MLOps pipeline can often feel like a Herculean task. The sheer range of services and skills required can make the process daunting and time-consuming. Furthermore, custom developments often become so intertwined with application logic that maintaining application code becomes a challenging endeavor.
These picks are designed to alleviate these issues and put MLOps best practices front and center of your development.
ZenML provides a fast-lane for transitioning from experimental code to a structured, production-ready pipeline with minimal changes. This vendor-agnostic framework excels at decoupling application code from infrastructure tooling, allowing you to specify different service providers for each component of your infrastructure.
With ZenML, your pipeline’s steps are annotated and linked together to form the actual pipeline. Then, you configure a Zen Stack, specifying the necessary tooling and infrastructure. This stack consists of two main components: the orchestrator and the artifact store. The orchestrator, which could be a cloud execution service or a simple Python interpreter, runs your pipeline's code. The artifact store is where your data will reside. And the best part? ZenML supports numerous integrations, offering additional functionality like feature stores, data validation, and experiment trackers.
In the other corner, we have Google's AutoMLOps, which shares ZenML's approach of annotating model development code as components and pipelines. However, AutoMLOps takes it a step further by automatically generating the necessary code to containerize your components, provision them to Google’s cloud, and deploy those containers to the allocated resources. All of this follows an automated, reproducible CI/CD process that helps accelerate your path towards MLOps maturity level 2.
The deployed pipelines can then make use of Google’s extended MLOps suite of functionalities, ranging from data processing and storage, to experimentation, training and offline evaluation to online serving with configurable auto-scaling capabilities and testing as well as monitoring for drift both in your input data and in your models’ predictions. This enables use of advanced capabilities like continuous training and deployment, enhancing your applications’ accuracy and catching errors before they can have a real impact on the end-user or business.
Uniquely tailored to leverage Google Cloud Services and Vertex AI, AutoMLOps is your magic carpet ride through the cloud. While it's true that this tool is unabashedly Google-centric, it's a small concession for the vast benefits you'll reap. If you're open to navigating the Google Cloud, prepare to have a significant portion of your journey streamlined, making your cloud-based endeavors more efficient and enjoyable than ever.
With these two powerhouses in your toolkit, you're well-equipped to navigate the complexities of MLOps, ensuring your machine learning initiatives are not only successful but also efficient and manageable.
Say goodbye to the days of wrestling with infrastructure and application code, and say hello to the era of streamlined, effective MLOps.
7. WhisperX — speech recognition with word-level timestamps & diarization
Have you crossed paths with Whisper, the trailblazing speech recognition model from OpenAI? It's like a multilingual maestro, adept at a concert of tasks such as speech transcription, timestamping, speech-to-text translation and voice detection — all in various languages.
Now, let me introduce you to its turbo-charged cousin, WhisperX. It's like Whisper after a double shot of espresso, boasting more accurate timestamping, multiple speaker detection, and a reduction in hallucinations (not the psychedelic kind, but the kind where it starts pouring words when no-one is speaking) by enhancing the voice activity detection. The best part? It does all this while being faster and less memory-hungry.
WhisperX has a secret weapon called voice activity detection preprocessing. It's like a bouncer that only lets in audio segments that contain voice activity, and it's much cheaper than letting everyone in for a full automatic speech recognition party. This approach also ensures that the audio is sliced into neat chunks, avoiding any awkward cuts mid-speech and boosting the reliability of whole word detection. Plus, the timestamps are tidied up to match these boundaries, making them even more accurate. The final touch? A phoneme classifier model that aligns word boundaries based on a fixed, per-language dictionary. It's like having a grammar stickler on your team.
Curious to see it in action? Check out an English sample of the results on their GitHub repository.
The beauty of WhisperX is that the chunks can be processed in parallel, like a well-oiled assembly line, which enables batched inference. And thanks to a switch to the Faster Whisper backend, the RAM usage for the whisper-large model has been trimmed down to less than 8GB. This means it can now play nice with a wider range of graphics cards while also boasting a whopping 70x speedup on the same model. Like putting your speech recognition on a high-speed treadmill.
For the curious minds who love to dive into the nitty-gritty, the authors have generously shared their pre-print paper.
8. AutoGen — LLM conversational collaborative suite

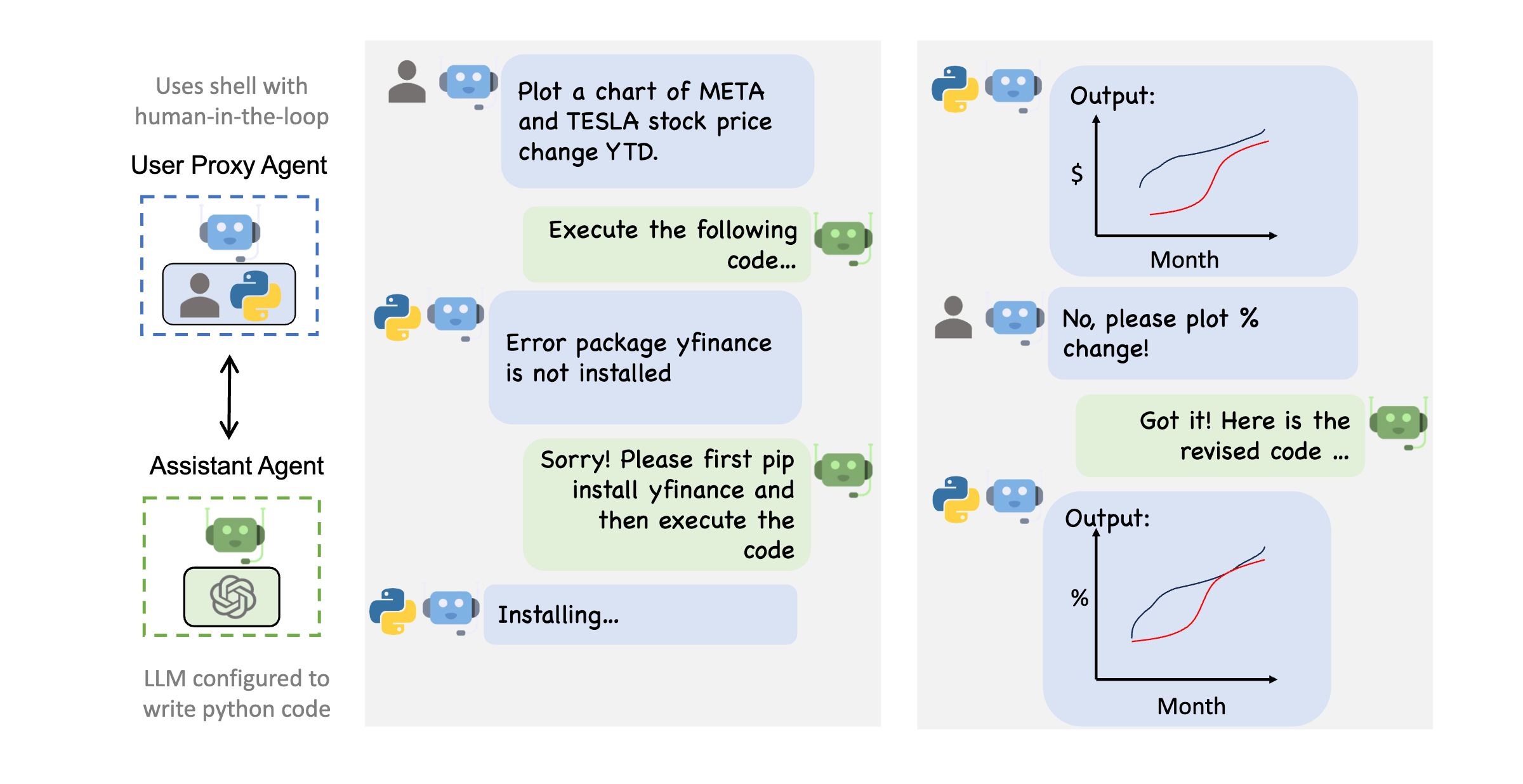
Ever dreamed of a personal team of software engineers ready to bring your app ideas to life? Meet Microsoft’s AutoGen, your magic wand that conjures up conversational agents working in harmony to achieve a shared goal. It's like the Avengers, but for software development.
AutoGen's simplest setup stars two key players: the AssistantAgent and UserProxyAgent. The AssistantAgent is your AI sidekick, designed to execute tasks independently. Meanwhile, the UserProxyAgent is your digital stand-in, allowing you to step in when human intervention is needed but also being able to act on your behalf. It's like having your cake and eating it too!
The AssistantAgent performs tasks, while the UserProxyAgent provides feedback to the AssistantAgent on whether the task is successfully completed. Once the task is set, these agents spring into action, working autonomously until they either require human oversight or they've successfully completed the task.
This framework shines in use cases like code generation. The AssistantAgent crafts the code, while the UserProxyAgent tests it. If bugs appear, the UserProxyAgent provides feedback, and the cycle repeats. It's like owning a personal code factory.
The beauty of AutoGen lies in its scalability. You can introduce additional agents to fulfill various roles, akin to building your software development team. Need a tester agent or a product manager? AutoGen has got you covered. For inspiration, check out ChatDev, a project that built an entire software team using a similar concept.
AutoGen also boasts several Enhanced Inference features that empower your workflow. It unifies the API for several models, enabling you to link multiple LLMs behind a single agent: if one model fails the next in line takes the mantle, ensuring robustness. Furthermore, it provides a prompt results cache for faster, cost-effective inference, chat logging for debugging and prompt templating so that common instructions (such as explain your reasoning step by step) can be reused across multiple tasks.
But that's not all. Do you want to enhance your agents with RAG? Just add Retrieve to their class names and provide a docs path et voila! Your agents can now tap into custom databases providing context-specific information. Want an agent that learns on the go? Try explaining via prompts some stuff to the TeachableAgent and it will store the information you provide in a MemGPT-style embeddings DB, allowing it to recall and reason over this context in future interactions. An extremely powerful usage for this is having your agents reason about what worked in their interactions and produce a summary recipe of the steps that did work, then teach the TeachableAgent that recipe so it knows how to do it next time.
To cap it all off, AutoGen offers robust security measures. The AutoGen team strongly advises running your agents' code inside a Docker container. You know, just in case you stumble upon the agent combo that unlocks AGI. 😉😉. With AutoGen, the sky's indeed the limit.
9. Guardrails — babysit LLMs so they behave as intended

Have you ever had a fantastic prompt, carefully crafted through a meticulous prompt-engineering process only to find your Large Language Model breaking its chains and responding with a non-structured answer? Or an LLM not following your instructions and mentioning your competitor?
The flexibility of LLMs provides an immensely vast range of applications but also makes its integration into a greater pipeline challenging. Enter Guardrails: a library designed to specify structure and type, as well as validating and correcting the outputs of large language models.
Guardrails works by defining a .rail specification, a flavor of XML, that’s intended to be human readable and allows for defining the structure of the requested output, validators to ensure the values meet a given quality criteria, and corrective actions such as re-asking the LLM or filtering out the invalid output if the validations are not met.
Here’s an example that specifies the quality criteria (generated length, URL reachability) in the format fields of the RAIL spec, re-asks for explanation and filters the follow_up_url if not valid.
Guards such as these can be initialized from a RailSpec as well as from PyDantic type definitions, or even strings for less complex use cases. The structure can then be used to define the fields that the LLM must produce as well as their types, including nested objects defined within your logic. Several validators are provided out of the box ranging from simple string min/max length or regex validations to syntactic bug-free Python or SQL code, profanity-free text and many [more] (https://docs.guardrailsai.com/api_reference/validators/).
With Guardrails in your stack, your LLM applications are bound to be more reliable and robust, making it easier to integrate them into your flows.
10. Temporian — the “Pandas” built for preprocessing temporal data

Time is of the essence. Time is money. Time is running out… You’ve heard it before right? Temporal data is ubiquitous in most human activity, that's why many popular libraries allow representing and manipulating time-series data: a series of values with equal time intervals between them.
However, the classical time series approach falls short for representing many kinds of real-world temporal data that is not equally spaced, such as user clicks on a website or sales happening in several of a retailer’s stores.
The go-to approach in this scenario has always been to use a general data preprocessing tool, such as pandas, and cram data into a tabular format by resampling and aggregating it — losing both flexibility and granularity in the whole feature engineering process.

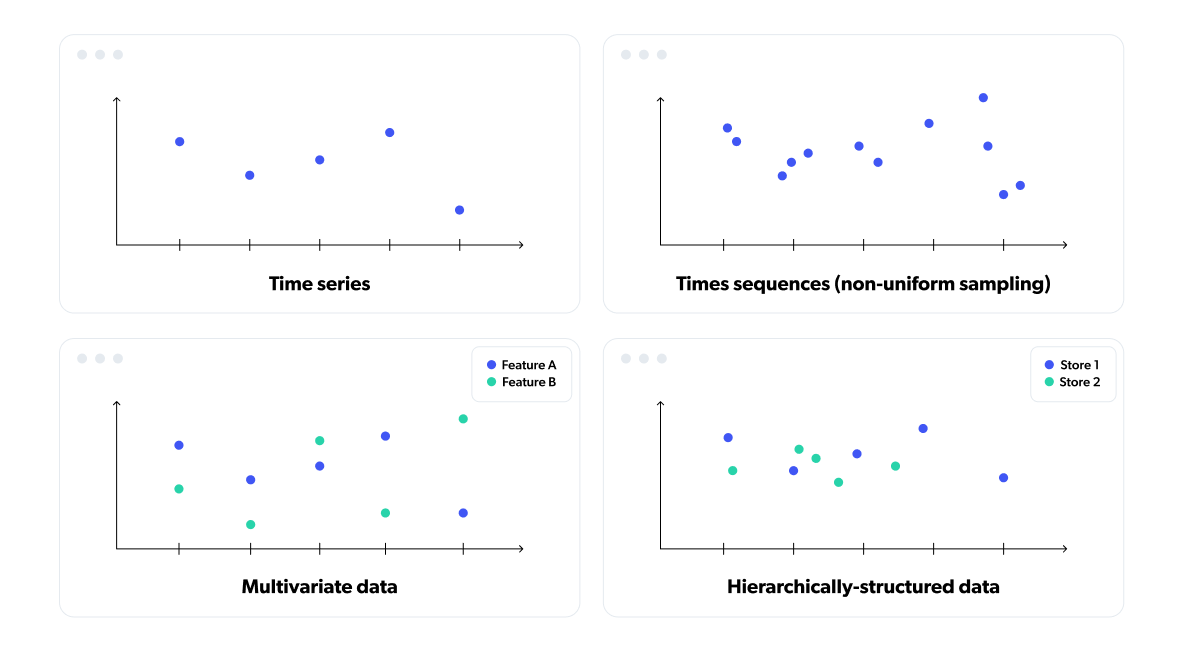
This is why Tryolabs has partnered with Google to develop a state-of-the-art library for temporal data manipulation. Temporian allows for safe, simple and efficient preprocessing and feature engineering of temporal data through a Python API backed by a C++ implementation for blazing-fast speeds. Temporian supports multivariate time-series, multivariate time-sequences, event logs, and cross-source event streams.
At the core of Temporian is the EventSet, which contains timestamped records called Events that hold feature values. EventSets can contain multivariate time series with uniform or non-uniform timestamps, as well as independent series belonging to different entities. Handy operators like lag, resample, and window functions help fill in gaps and align timestamps for arithmetic operations.
To get a sense of the API, here’s a simple Temporian snippet that computes the daily revenue for each store in a sales dataset, sampled at 10pm every workday:
Temporian proposes a new paradigm through which to work with temporal data. And being tailor-made for it, plus its core computations running as highly-optimized C++ code, enables it to make commonplace temporal operations safer, easier to write, and much, much faster to execute — with benchmarks showing speedups of upwards of 100x against equivalent pandas code.
If you are curious, check out the Tutorials in the documentation, which will walk you through real examples using the library. And of course, all feedback is more than welcome :)
Runners-up
The following libraries almost made it to our top picks and we feel they deserve special recognition:
- DataGradients — say hello to your personal assistant for computer vision dataset analysis. DataGradients, a brainchild of Deci AI, is an open-source Python library that comes packed with solutions for common tasks in vision dataset management. Whether it's identifying corrupt images, wrong labels, biases, extracting summaries for a deeper understanding of available data, or providing guidance for hyperparameter selection, DataGradients has got you covered.
- functime — a comprehensive library for time-series forecasting and feature extraction on large panel datasets. Offering unique preprocessing options and cross-validation splitters. It stands out for its incredible speed and efficiency, capable of processing 100,000 time-series in seconds, thanks to its smart use of Polars for parallel feature engineering. But functime is more than just speed; it's a powerful ally equipped with proven machine learning algorithms and supports exogenous features across all forecasters. It's also automated, managing lags and hyperparameter tuning with FLAML. With over 100 time-series feature extractors available in its custom
tsnamespace, functime offers an efficient, user-friendly platform that is transforming the way we approach time-series data. - LoRaX — an inference server that scales to 1000s of fine-tuned LLMs, by Predibase. LoRaX (”LoRA eXchange”) is designed to serve a multitude of fine-tuned models on a single GPU, significantly cutting down the costs associated with serving while maintaining impressive throughput and latency. Key features include Dynamic Adapter Loading, allowing just-in-time loading of any fine-tuned LoRA adapter without affecting concurrent requests; Heterogeneous Continuous Batching, which combines different adapter requests to maintain stable latency and throughput; and Adapter Exchange Scheduling, which efficiently manages adapter prefetching and offloading between GPU and CPU. It supports a range of Large Language Models like Llama and Mistral as base models, and is compatible with LoRA adapters trained using PEFT and Ludwig libraries.
- outlines — guided text generation with LLMs, especially focusing on constrained text generation. Allows for model guidance such as, multiple choice, type constraints and dynamic stopping by using a very efficient regex-guided generation, leading to faster inference when compared to other guidance approaches. Generate valid JSON 100% of the time! Check out their HN Launch Blog post for more insights.
- Pearl — a gift from Meta's Applied Reinforcement Learning (RL) team. It's a production-ready AI Agent Library that prioritizes cumulative long-term rewards over immediate feedback. These agents can adapt to environments with limited observability, sparse feedback, and high stochasticity, making them a fitting choice for a wide range of real-world problems. Pearl's modular implementation of state-of-the-art RL algorithms is a testament to its versatility and forward-thinking approach.
- PEFT — brought to you by Hugging Face, PEFT or Parameter-Efficient Fine-Tuning methods, is your ticket to fine-tuning pre-trained language models for a wide array of downstream applications without having to change all the model's parameters, saving on computational resources while also retaining the good properties of more generalistic models and improving performance on your specific task.
- vLLM — A high-throughput and memory-efficient inference and serving engine for LLMs. It improves LLM serving performance by 3.5x over previous SOTA, without changing model architecture. Since output size isn’t known beforehand LLMs typically reserve very large and wasteful long blocks of contiguous memory as large as the model output size. The secret (actually not secret, it’s open sourced) sauce is an algorithm called PagedAttention where they physically split the key-value caches that LLMs use into fixed length, short and dynamically allocated blocks. The dynamic assignment prevents memory waste, allowing more prompts to fit into VRAM and hence enabling faster throughput. At the time of writing, vLLM has been adopted as the serving solution by many of the big players, becoming a de-facto standard serving solution.
The Hidden Gems: Unveiling the Long Tail of 2023 Python Libraries
While our top picks have certainly captured the limelight, there's a whole constellation of Python libraries that didn't make it to the main stage but are equally deserving of your attention. With more than 120 innovative Python libraries analyzed, each with its own unique capabilities and cutting-edge features, if we were to do justice to each one of them, we'd be here until the next Winter Olympics!
To help you navigate this treasure trove, we've neatly categorized these libraries and distilled their key features into succinct, one-liner summaries.
Causal inference
- CausalTune — a library for automated tuning and selection for causal estimators.
- CausalPy — A Python package for causal inference in quasi-experimental settings.
- PyWhy-LLM — experimental library integrating LLM capabilities to support causal analyses.
CLI LLM Tools
- Chatblade — ChatGPT on the command line, providing utility methods to extract JSON or Markdown from ChatGPT responses.
- Elia — A terminal ChatGPT client built with Textual.
- Gorilla CLI — powers your command-line interactions with a user-centric tool. Simply state your objective, and Gorilla CLI will generate potential commands for execution.
- LLM — A CLI utility and Python library for interacting with Large Language Models, both via remote APIs and models that can be installed and run on your own machine. By the author of Datasette.
Code Tools
- Chainlit — “the Streamlit for ChatGPT”, create ChatGPT-like UIs on top of any Python code in minutes!
- pydistcheck — Linter that finds portability issues in Python package distributions (wheels and sdists).
- pyxet — lightweight interface for the XetHub platform, a blob-store with a filesystem like interface and git capabilities.
Computer vision
- deepdoctection — orchestrates document extraction and document layout analysis tasks using deep learning models.
- FaceFusion — Next generation face swapper and enhancer.
- MetaSeg — packaged version of the Segment Anything Model (SAM).
- VTracer — open source software to convert raster images (like jpg & png) into vector graphics (svg)
Data and Features
- Adala — Adala - Autonomous DAta (Labeling) Agent framework.
- Autolabel — Label, clean and enrich text datasets with LLMs.
- balance — simple workflow and methods for dealing with biased data samples when looking to infer from them to some target population of interest. See launch blog post. By META.
- Bytewax — Python framework that simplifies event and stream processing. Because Bytewax couples the stream and event processing capabilities of Flink, Spark, and Kafka Streams with the friendly and familiar interface of Python, you can re-use the Python libraries you already know and love.
- Featureform — feature store. Turn your existing data infrastructure into a feature store.
- Galactic cleaning and curation tools for massive unstructured text datasets. Ben (48/100) on X
- Great Expectations — helps data teams build a shared understanding of their data through quality testing, documentation, and profiling.
Data Visualization
- PyGWalker — turn your pandas DataFrame into a Tableau-style User Interface for visual analysis.
- Vizro — a toolkit for creating modular data visualization applications. By McKinsey.
Embeddings and Vector DBs
- Epsilla — a high performance Vector Database Management System, focused on scalability, high performance, and cost-effectiveness of vector search.
- LanceDB — open-source database for vector-search built with persistent storage, which greatly simplifies retrieval, filtering and management of embeddings.
- SeaGOAT — local search tool that leverages vector embeddings to enable to search your codebase semantically.
- Text Embeddings Inference — A blazing fast inference solution for text embeddings models.
Federated learning
- Flower — A Friendly Federated Learning Framework.
- MetisFL — federated learning framework that allows developers to easily federate their machine learning workflows and train their models across distributed data silos without ever collecting the data in a centralized location.
Generative AI
- AudioCraft — library for audio processing and generation with deep learning. By Meta.
- Image Eval — A toolkit for evaluating your favorite image generation models. LinkedIn Launch Post.
- imaginAIry — Pythonic generation of stable diffusion images.
- Modular Diffusion — Python library for designing and training your own Diffusion Models with PyTorch.
- SapientML — Generative AutoML for Tabular Data.
LLM Accuracy Enhancements
- AutoChain — AutoChain: Build lightweight, extensible, and testable LLM Agents
- Auto-GPT — An experimental open-source attempt to make GPT-4 fully autonomous.
- Autotrain-Advanced — faster and easier training and deployments of state-of-the-art machine learning models.
- DSPy — framework for solving advanced tasks with language models (LMs) and retrieval models (RMs). DSPy unifies techniques for prompting and fine-tuning LMs — and approaches for reasoning and tool/retrieval augmentation. By Stanford NLP.
- GPTCache — GPTCache is a library for creating semantic cache to store responses from LLM queries.
- Neural-Cherche — fine-tune neural search models such as Splade, ColBERT, and SparseEmbed on a specific dataset, and run efficient inference on a fine-tuned retriever or ranker.
- MemGPT — Teaching LLMs memory management for unbounded context 📚🦙.
- nanoGPT — The simplest, fastest repository for training/finetuning medium-sized GPTs.
- Promptify — common prompts that work well to leverage LLMs for a variety of scenarios.
- SymbolicAI — Compositional Differentiable Programming Library.
- zep — a long-term memory store for LLM / Chatbot applications. Easily add relevant documents, chat history memory & rich user data to your LLM app's prompts.
LLM App Building
- autollm — Ship RAG based LLM web apps in seconds.
- Chidoriv — reactive runtime for building AI agents. It provides a framework for building AI agents that are reactive, observable, and robust. It supports building agents with Node.js, Python, and Rust.
- FastChat — open platform for training, serving, and evaluating large language model based chatbots.
- GPTRouter — smoothly manage multiple LLMs and image models, speed up responses, and ensure non-stop reliability. Similar to LiteLLM, our top pick!
- guidance — a guidance language for controlling large language models.
- haystack — end-to-end NLP framework that enables you to build NLP applications powered by LLMs, Transformer models, vector search and more.
- Instructor — interact with OpenAI’s function call API from Python code, with Python structs / objects.
- Jsonformer — A Bulletproof Way to Generate Structured JSON from Language Models
- Langroid — easily build LLM-powered applications. Set up Agents, equip them with optional components (LLM, vector-store and methods), assign them tasks, and have them collaboratively solve a problem by exchanging messages.
- LLM App — build innovative AI applications by providing real-time human-like responses to user queries based on the most up-to-date knowledge available in your data sources.
- maccarone — AI-managed code blocks in Python, lets you delegate sections of your Python program to AI ownership.
- magentic — prompt LLMs as simple Python functions using decorators.
- Semantic Kernel — integrate cutting-edge LLM technology quickly and easily into your apps. Microsoft’s “version” of LangChain.
LLM Code Tools
- aider — command line tool that lets you pair program with GPT-3.5/GPT-4, to edit code stored in your local git repository.
- ChatGDB — Harness the power of ChatGPT inside the GDB debugger!
- Dataherald — natural language-to-SQL engine built for enterprise-level question answering over structured data. HN launch post.
- FauxPilot — open-source GitHub Copilot server.
- GPT Engineer — Specify what you want it to build, the AI asks for clarification, and then builds it.
- gpt-repository-loader — command-line tool that converts the contents of a Git repository into a text format that can be interpreted by LLMs.
- ipython-gpt — extension that allows you to use ChatGPT directly from your Jupyter Notebook or IPython Shell.
- Jupyter AI — generative AI extension for JupyterLab.
- PlotAI — use ChatGPT to create plots in Python and Matplotlib directly in your Python script or notebook.
- sketch — AI code-writing assistant for pandas users that understands the context of your data, greatly improving the relevance of suggestions.
LLM Development
- distilabel — AI Feedback framework for scalable LLM alignment.
- language-model-arithmetic — controlled text generation via language model arithmetic.
- Lit-GPT — Hackable implementation of state-of-the-art open-source LLMs based on nanoGPT. Supports flash attention, 4-bit and 8-bit quantization, LoRA and LLaMA-Adapter fine-tuning, pre-training.
- Lit-LLaMA — Implementation of the LLaMA language model based on nanoGPT. Supports flash attention, Int8 and GPTQ 4bit quantization, LoRA and LLaMA-Adapter fine-tuning, pre-training.
- LMQL — a query language for programming (large) language models.
LLM Experimentation
- ChainForge — open-source visual programming environment for battle-testing prompts to LLMs.
- Langflow — UI for LangChain, designed with react-flow to provide an effortless way to experiment and prototype flows.
- PromptTools — a set of open-source, self-hostable tools for experimenting with, testing, and evaluating LLMs, vector databases, and prompts. HN launch post.
LLM Metrics
- DeepEval — a simple-to-use, open-source evaluation framework for LLM applications.
- Fiddler Auditor — a tool to evaluate the robustness of language models.
- ragas — Evaluation framework for your Retrieval Augmented Generation (RAG) pipelines.
- tvalmetrics — Metrics to evaluate the quality of responses of your Retrieval Augmented Generation (RAG) applications.
LLM Serving
- Aviary — an LLM serving solution that makes it easy to deploy and manage a variety of open source LLMs. By the authors of Ray.
- GPT4All — an ecosystem to run powerful and customized large language models that work locally on consumer grade CPUs and any GPU (ex pygpt4all/pyllamacpp) with python bindings.
- LLM Engine — engine for fine-tuning and serving large language models. By Scale AI.
- LLM Gateway — gateway for secure & reliable communications with OpenAI and other LLM providers.
- punica — Serving multiple LoRA finetuned LLM as one.
- Ollama — Get up and running with Llama 2 and other large language models locally.
- OnPrem.LLM — tool for running on-premises large language models with non-public data.
- OpenLLM — An open platform for operating large language models (LLMs) in production. Fine-tune, serve, deploy, and monitor any LLMs with ease. By BentoML.
- OpenLLMetry — Open-source observability for your LLM application, based on OpenTelemetry.
- privateGPT — Interact privately with your documents using the power of GPT, 100% privately, no data leaks.
LLM Tools
- IncarnaMind — Connect and chat with your multiple documents (pdf and txt) through GPT and Claude LLMs in a minute.
- Puncia — leveraging AI and other tools, it will tell you everything about a web domain or subdomain, like finding hidden subdomains.
- scrapeghost — experimental library for scraping websites using OpenAI's GPT API.
MLOps, LLMOps, DevOps
- phoenix — ML Observability in a Notebook - Uncover Insights, Surface Problems, Monitor, and Fine Tune your Generative LLM, CV and Tabular Models.
Multimodal AI Tools
- LLaVAv — Visual Instruction Tuning - Large Language-and-Vision Assistant built towards multimodal GPT-4 level capabilities.
- Multimodal-Maestro — effective prompting for Large Multimodal Models like GPT-4 Vision, LLaVA or CogVLM.
- Nougat — the academic document PDF parser that understands LaTeX math and tables.
- UForm — Pocket-Sized Multi-Modal AI For Semantic Search & Recommendation Systems.
Python ML
- difflogic — A Library for Differentiable Logic Gate Networks by Felix Petersen.
- TensorDict — a dictionary-like class that inherits properties from tensors, such as indexing, shape operations, casting to device etc. The main purpose of TensorDict is to make code-bases more readable and modular by abstracting away tailored operations.
Performance and scalability
- AITemplate — Python framework which renders neural network into high performance CUDA/HIP C++ code. Specialized for FP16 TensorCore (NVIDIA GPU) and MatrixCore (AMD GPU) inference.
- AutoGPTQ — easy-to-use LLMs quantization package with user-friendly APIs, based on GPTQ algorithm.
- composer — PyTorch library that enables you to train neural networks faster, at lower cost, and to higher accuracy. Implements more than two dozen speedup methods that can be applied to your training loop in just a few lines of code.
- fastLLaMa — Python wrapper to run Inference of LLaMA models using C++.
- hidet — open-source deep learning compiler, written in Python. It supports end-to-end compilation of DNN models from PyTorch and ONNX to efficient cuda kernels.
- LPython — compiler that aggressively optimizes type-annotated Python code. It has several backends, including LLVM, C, C++, and WASM. LPython’s primary tenet is speed. Launch blog post.
- Petals — Run 100B+ language models at home, BitTorrent-style. Fine-tuning and inference up to 10x faster than offloading.
- TokenMonster — Determine the tokens that optimally represents a dataset at any specific vocabulary size
Python Programming
- Django Ninja CRUD — declarative CRUD Endpoints & Tests with Django Ninja.
- DotDict — A simple Python library to make chained attributes possible.
- grai-core — Data lineage made simple. Grai makes it easy to understand and test how your data relates across databases, warehouses, APIs and dashboards. HN launch blog post.
- pypipe — Python pipe command line tool.
- ReactPy — library for building user interfaces in Python without Javascript, made from components which look and behave similarly to those found in ReactJS.
- Reflex — open source framework to build web apps in pure Python. Launch announcement.
- scrat — caching of expensive function results, like
lru_cachebut with persistency to disk. - svcs — a dependency container for Python SVCS
- view.py — lightning-fast, modern web framework. Currently in a very high alpha stage of development. HN launch post.
Optimization / Math
- Lineax — a JAX library for linear solves and linear least squares. Launch Tweet.
- pyribs — a bare-bones Python library for quality diversity optimization.
Reinforcement Learning
- cheese — adaptive human in the loop evaluation of language and embedding models.
- imitation — Clean PyTorch implementations of imitation and reward learning algorithms.
- RL4LMs — modular RL library to fine-tune language models to human preferences. By AI2.
- trlX — distributed training of language models with Reinforcement Learning via Human Feedback (RLHF).
Time Series
- aeon — A unified framework for machine learning with time series.
Video Processing
- VapourSynth — video processing framework with simplicity in mind. Python docs.

Wondering how AI
can help you?

Terms and Conditions | © 2026. All rights reserved.