

Mastering RAG: a journey of challenges and innovations



The world is in awe of the power of Large Language Models (LLMs) and the myriad of applications that Generative AI (GenAI) has enabled. This boom of GenAI has increased drastically with the introduction and expansion of the Retrieval Augmented Generation (RAG) architecture, mainly because it enables companies to leverage powerful LLMs over their data and tasks with little effort.
According to Databricks’ report, RAG has become a crucial mechanism for businesses to enhance the performance of LLMs. A key component of this process is the use of vector databases, which have seen a remarkable 377% growth in the past year.
In fact, by using bleeding-edge tech stacks like LangChain or LlamaIndex, you can build a simple RAG application in just a few lines of code. However, real applications aren’t always this simple, and out-of-the-box RAG usually underperforms in real business scenarios. But don’t worry, we’ve got you covered!
We'll explore the challenges that real-world RAG applications face and show you how to leverage advanced RAG techniques along with our expertise. This will help you transform an engaging demo into a fully functional and robust production application.
RAG application showcase
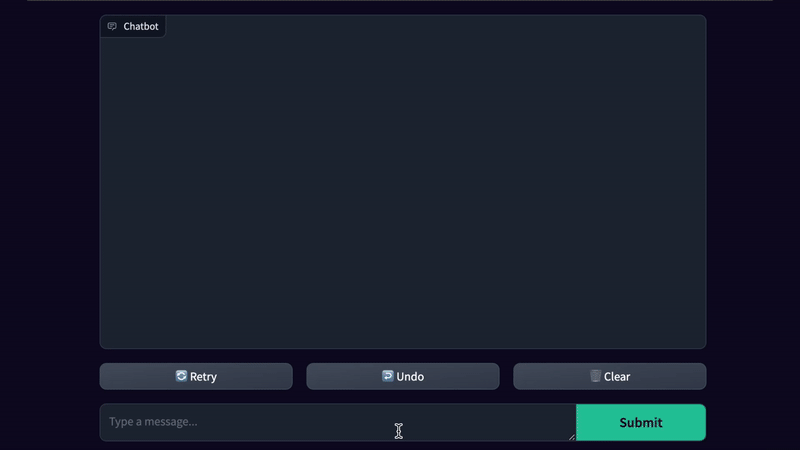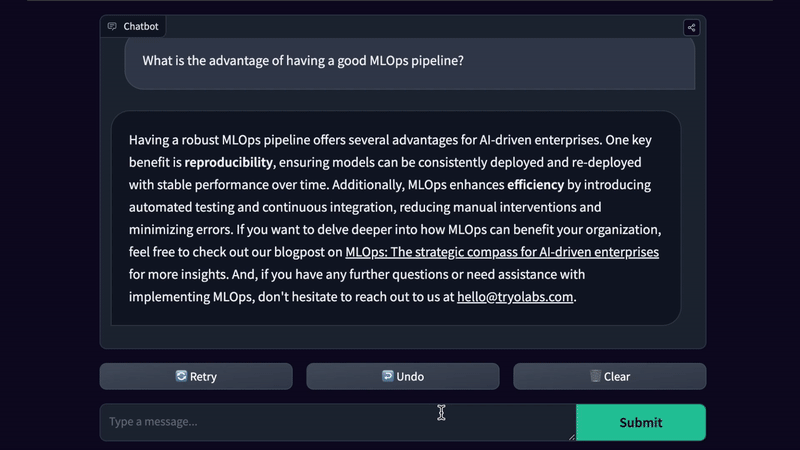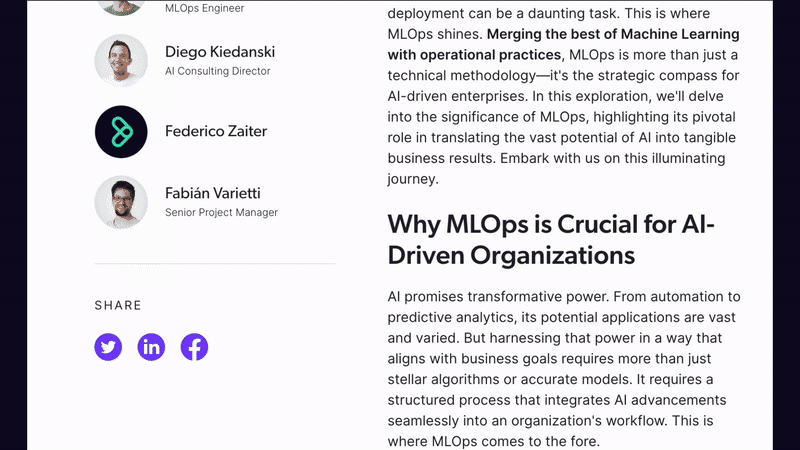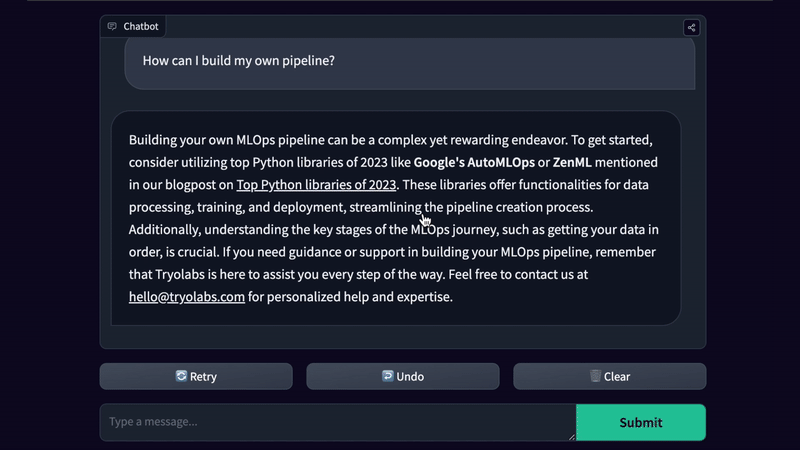
With modern tools and models, building a RAG application can be extremely easy. To illustrate this, we've built a chatbot using LangChain and GPT-3.5 Turbo, enabling you to chat and ask questions about all the contents of our blog posts. Not only does this chatbot use the accumulated knowledge of Tryolabs’ experts, but thanks to RAG, it can refer back to the content used to answer your questions. This entire chatbot required less than 100 lines of code.

In a previous blog post, “Fine-tuned LLMs and Distributed Training to elevate your Conversational AI game”, we built a similar chatbot using fine-tuning.
If you try both chatbots, you’ll quickly see how this new RAG-enhanced chatbot is far more engaging, faster and useful!
The steps needed to build this demo are very simple. First, Tryolabs’ blog posts are downloaded from the web and split into small, overlapped chunks of text. These chunks are encoded and stored in a vector database. Later, when a question is sent to the chatbot, the most relevant chunks of text are retrieved from the vector database and used by the LLM to produce an answer with references to the original posts. LangChain provides a wide range of components covering each of these steps and the framework to combine them, which drastically reduces the time needed to turn an idea into an application. This example clearly illustrates the potential of using RAG to build your own GenAI applications. In just a few hours of coding, and without needing to train or fine-tune, we built a chatbot that answers questions about our data and can work as a marketing tool.
However, despite being an attractive demo, if you use it long enough, you will soon realize it’s far from production-ready. The chatbot can respond with inaccurate, contradictive, or undesirable answers, which is a significant problem in a real, user-facing application. For example, the first version of the chatbot used to hallucinate and attribute Tryolabs with the invention of nonexisting tools, which doesn’t look good in a production scenario. We managed to mitigate that failure with prompt engineering, but that’s just one of the problems the vanilla RAG architecture can have.
Next, we will cover different weak spots of this architecture and how to avoid them in more detail.
Try the demo yourself to see what we’re talking about!
Understanding RAG's architecture
The basic RAG architecture (like the one used for the previous demo) is very simple to understand and achieves good baseline results. It consists of three main stages: indexing, retrieval and generate.


Stage 1: Indexing
At this stage, data is collected, split into chunks, and inputted into an embedding model. The resulting embeddings are stored in a Vector Database for fast and efficient search.


An embedding is a numeric representation of your data, which allows you to group your documents by similarity or search for relevant documents to a user's question.
The embedding model is another language model that specializes in building these representations.
Stage 2: Retrieval
Given the user’s input, the Vector Database is searched using advanced techniques for relevant documents that can help solve the user’s query. The retrieval stage should recover documents with high similarity to the query but with enough diversity so that each document provides different and important information.


Stage 3: Generate
Once relevant documents are retrieved, a final prompt is built, asking the LLM to answer the user’s query using the retrieved documents. Then, the LLM takes this prompt and generates a response.

Why go through all this effort to provide more context to the LLM? While LLMs are excellent at understanding and reasoning over various media inputs, they are trained on a vast amount of general data and might lack the specific knowledge required for your unique data. By supplying more information during inference time, you equip the LLM with the necessary context, leveraging its reasoning abilities to solve the task accurately.
This intuitive approach has significantly boosted the performance of LLMs on many specific tasks and datasets, sometimes even being preferred over fine-tuning.
RAG vs fine-tuning
Microsoft recently published a research paper that compares RAG and fine-tuning on various tasks, showing how RAG is better suited for knowledge-intensive tasks.
How can RAG impact your business?
Improve quality
Instead of relying solely on the LLM's learned knowledge, RAG allows you to inject your own curated data into the LLM and generate more accurate and factual responses.
Reduce costs
While fine-tuning techniques have improved remarkably over the years, they still involve building datasets tailored to your specific problem and business, preprocessing the data, and experimenting with different hyperparameters and methods to achieve good results. Additionally, fine-tuning requires computing resources and time, which add to the cost of building your solution. In contrast, RAG presents a more cost-effective alternative. In its basic form, the RAG architecture doesn’t require fine-tuning LLMs, significantly reducing the time and cost of getting a solution up and running. By harnessing the power of LLMs, you can use all your readily available data with less preprocessing and without needing to build large custom datasets, translating to saved time and effort.
Traceability
A strong advantage of RAG is the ability to tie the model’s response to the data used to generate it, which all other training techniques fail to do. This feature is particularly important in mission-critical scenarios and useful for building trust on the system.
Overcoming RAG challenges
Even though RAG offers cost-effectiveness and simplicity, it may present challenges in real-world applications. Shortcomings may arise at any stage of the RAG pipeline:
- Indexing stage: The storage might not be optimized, or the embeddings produced for the documents might be of low quality.
- Retrieval stage: The system might fail to return relevant documents, undermining the effectiveness of the entire process.
- Generation stage: The model might not correctly use the provided context or might ignore it entirely, resulting in hallucinations or irrelevant output.
Thankfully, novel methods and solutions can be implemented to address these weak spots, ensuring a more robust and reliable RAG pipeline.
More data is not necessarily better
One usual misconception while using RAG is that the more context data we give to the LLM during the generation stage, the better it will perform. But this is not necessarily true and may be counterproductive in some cases.
Challenges of using a lot of context data
Noisy or contradictory data: Providing the LLM with context that contains conflicting facts or irrelevant information can generate undesirable responses.
Loss of focus: LLMs can suffer from a problem called “Lost in the Middle” where they pay less attention to the middle portion of a large context and more to the beginning and end. Providing too many unordered pieces of context might cause the LLM to overlook important information.
Irrelevant context: If working with a large, fixed number of documents, you might be providing context that is not related to the user's input, leading to misleading responses.
Scalability issues: As your vector database grows, searching through it can become problematic in terms of search speed and the quality of the retrieved pieces.
Finding the right balance in the amount of context provided to the LLM is essential. It’s a parameter that needs to be tuned to fit your specific needs.
How to tackle these challenges
No need to panic. There are plenty of methods for mitigating these problems, which can classified into pre-retrieval and post-retrieval techniques.
Pre-retrieval methods
Pre-retrieval methods enhance the indexing stage (how you store the data and the quality of the data being stored) and the retrieval methods used. Here are a few of them:
Good quality data: Filter and clean your data before storing it to ensure no noisy or contradictory pieces of context can be retrieved.
Storage optimization: There’s a diverse offering of Vector Databases to use and ways to store data for fast and reliable search. Choosing the right storage method can help your architecture scale better and provide higher quality results.
Enhanced retrieval techniques: there are many ways in to improve the basic retrieval stage. For example, if building a chatbot, you can use an LLM to modify the user’s input by rephrasing the questions or asking from different angles, and then use multiple parallel queries to search for similar pieces of context. This method falls under Query Expansion techniques. You can also use a Query Transformation method (i.e., using an LLM to rewrite the query entirely to optimize it) or a Query Routing method (i.e., having a set of specialized RAG pipelines and a router that selects the best one to solve a specific task).
Post-retrieval methods
Post-retrieval methods optimize the usage of retrieved documents to enhance the generation stage. Here are some advanced techniques that can help:
Rank your context: One way to mitigate the “Lost in the Middle” problem is to rank the retrieved documents and place the most important ones at the beginning or end of the prompt so that the LLM pays more attention to them. Various ranking methods can be used to order the pieces of retrieved context in terms of quality, similarity to the user input, or diversity. For more details on this topic, check out this insightful post explaining two effective ranking methods for optimizing diversity and importance.
Filter your context: To avoid feeding noisy or contradictory pieces of context to the generation LLM, you can use a judge LLM to filter out irrelevant pieces of context before the generation stage.
Modify your context: Extended contexts are not always beneficial and may contain irrelevant data. To address this, you can perform further cleaning specifically tailored to the task and query. For example, you can use another LLM to summarize or extract relevant information from the retrieved documents.
Undesired responses and security
Even with all the previous techniques, you may still get undesired responses. The Generation stage uses relevant context but still depends on an LLM to understand the context and generate a response based on it, and this LLM may still suffer from hallucinations or be biased towards certain responses.
In our demo, sometimes the LLM hallucinates and provides non-factual information. For example, try asking “What LLM libraries did Tryolabs invent?”. The response will incorrectly attribute Tryolabs' development efforts to random libraries, which is false and could lead to potential problems if this was a production application.
To solve this, you can leverage certain strategies and tools to control the LLM’s responses. Check our blog post Taming LLMs: strategies and tools for controlling responses to learn how to tailor the responses generated to your desired standards by doing prompt tuning or implementing guardrails in your application.
Tackling complex tasks
The vanilla RAG architecture works well for simple chatbots or retrieval tasks, but it may be flawed for more advanced use cases that require multiple steps of reasoning or all available information to build a response.
Our AI Consulting Director, Diego Kiedanski, explains how a RAG system can generate the incorrect response to a simple question that requires all the available information to be answered.
For example, imagine you work for a company that manufactures household appliances and want to build a knowledge base with all the user manuals, instructions, and warranties of your products, and a chatbot that can help technicians troubleshoot problems or failures with the products. A question like “The door broke on the EZ-123 fridge, how can I replace it?” might be too complex for a simple RAG architecture to solve correctly, since a complete guide to changing the door might require many different steps and data sources.
In such cases, you can leverage a pre-retrieval Query Expansion technique to build sub-queries. Use another specialized LLM to break down the query into multiple, more granular questions, like “What tools do I need to replace the door on the EZ-123 fridge?”, “How can I remove the door on the EZ-123 fridge?” and “How can I assemble the door on the EZ-123 fridge?”. Then, retrieve the answers to these questions, each with its relevant context, and use another LLM to combine the answers into a more complete, step-by-step guide.
For such complex tasks, you can also use modern iterative or recursive RAG architectures. In these setups, after generating the response, another LLM judges the response to assess its quality and completeness. If the judge finds the response insufficient, more information is retrieved, and the generated response is enhanced until the LLM judge approves it.
The future: combining RAG and fine-tuning
Initially, RAG was popularized as an attractive alternative to fine-tuning. However, there’s an enormous potential in combining them both; by fine-tuning the LLMs used throughout the RAG architecture, you can enhance your results and avoid weak spots like the ones we’ve discussed.
Embedding model or Retriever fine-tuning
Most embedding models are pre-trained on general data obtained from the web. If the knowledge you’re trying to integrate is too specific or there’s too little of it, fine-tuning the embedding model can help to obtain better representations for your data, improving the Indexing and Retrieval stages of your RAG pipeline. Recent methods use an LLM to guide the fine-tuning process by indicating if the returned context was useful or not. This approach, known as LM-Supervised Retriever (LSR), uses LLMs to fine-tune the retriever.
Generator fine-tuning
Similar to other use cases, you can fine-tune the generator LLM to produce more personalized responses. Techniques such as Reinforcement Learning from Human Feedback (RLHF), guide the model’s responses towards user preferences. Also, fine-tuning the generator in a RAG architecture can help the LLM learn how to better use the provided context.
Collaborative fine-tuning
Taking it a step further, both the retriever and the generator can be fine-tuned collaboratively. The generator learns to use the retrieved context more effectively, while the retriever learns to return more relevant results preferred by the generator. This advanced setup is useful for knowledge-intensive and complex tasks with limited information available.
Tools and resources
Staying updated with the latest tools and resources is crucial for building effective RAG solutions. Here's a list of essential tools to know:
LangChain


LangChain is a modern and flexible framework for building applications powered by LLMs. Its chain abstraction lets you easily build a custom RAG architecture modularly, switching or adding components based on your application needs. Our demo for this blog post was built using LangChain on just ~100 lines of code!
LlamaIndex


LlamaIndex is a data framework that focuses on indexing data into vector databases and retrieval capabilities, while providing integrations for feeding data into existing LLMs. It includes multiple components for evaluating LLM-based solutions and RAG systems, crucial for developers and managers to demonstrate the quality and worth of their solutions.
Haystack


Haystack is an open-source framework for building custom applications powered by LLMs and retrieval pipelines. It offers numerous out-of-the-box integrations with LLM and cloud providers. This blog post, showcases how Airbus, used Haystack to build a production RAG system.
Chainlit

Chainlit is an open-source Python package for easily building an interface for Conversational AI. It integrates with all three previous frameworks, and is recommended by Microsoft for building AI-powered chatbot applications efficiently and quickly.
Deep Lake


Activeloop’s Deep Lake is one of the leading databases for training Machine Learning models and building GenAI applications. It can store data from different media types (images, video, text, PDFs and more) and perform blazing fast searches!
Activeloop offers a valuable free course on using LLMs, LangChain, and Deep Lake to build production-ready applications. This course is perfect for anyone looking to enhance their skills and stay ahead in the field.
The path forward for GenAI applications
LLMs and the RAG architecture have cemented themselves as the foundation for GenAI applications. With modern tools like LangChain or LlamaIndex, you can quickly create an impressive demo. However, building a production-ready application or solving more complex tasks requires applying multiple advanced techniques or specialized RAG architectures.
Although there are numerous methods to enhance the RAG architecture, a clear trend is emerging towards combining RAG and fine-tuning. This approach leverages the strengths of both to improve the quality of the retrieved content and the generated responses. We are excited to see what innovative combinations of RAG and fine-tuning will be discovered!
Building a production-ready GenAI application and achieving the desired results requires expertise and sophisticated methods. At Tryolabs, we can help you transform a stunning demo into an impactful production application.

Wondering how AI
can help you?

Terms and Conditions | © 2026. All rights reserved.