

Fine-tuned LLMs and Distributed Training to elevate your Conversational AI game





Large Language Models (LLMs) are powerful tools in the field of artificial intelligence that can understand and respond to natural language. Recently, LLMs like GPT-3, OPT, or T5 have stolen the spotlight on AI. These huge deep learning models, which consist of billions of parameters, perform astonishingly well for an extensive set of natural language processing tasks, including text generation, summarization, translation, and many more. A great example of the flexibility and power of LLMs is the recently released ChatGPT, which can produce astounding human-like text responses for a wide range of prompts.
While these large models are great for general tasks, they may need to be fine-tuned to achieve optimal performance on specific downstream tasks or when dealing with new, unseen data. Fine-tuning is when a model's parameters are adjusted to fit a particular dataset better. This can help companies use the model for tasks specific to their business.
As a treat to our amazing readers, we fine-tuned an LLM to build a chatbot that can answer natural questions about the rich content published on our blog. This article will walk you through the fine-tuning process, from building our own dataset to optimizing inference time for the fine-tuned model!
Say Hi!
Before diving into the details of our fine-tuning pipeline, we invite you to try out our chatbot for yourself! We’ve set up a 🤗 Hugging Face Space where you can ask the chatbot any questions you have about this blog post. Simply follow this link to access the space and start chatting! In addition, we’ve uploaded the fine-tuned model and its ONNX export to 🤗 Hugging Face so that you can explore them at will.


The model powering the chatbot was trained on the task of Conversational Question Answering, which means it can answer questions regarding a specific context (in this case, the content of this blog) or previous questions or answers from the current conversation thread. Try chatting with the bot in a conversational style, just as you would with one of Tryolabs’ tech experts!
Caveats
- Remember that this is just a small demo, so the answers may not be as accurate as expected; in the Improvements section, we’ll discuss how we can enhance the model’s responses! Also, the content of this blog was not included in the training set, which means that the chatbot will give you answers about new, unseen data!
- Response time may take between 10 to 20 seconds due to the use of 🤗 Hugging Face’s free-tier space, which only has access to two CPU cores. This response time is slow for a chatbot being used in production, but it's fast for a CPU deployment and for such large inputs (since the model needs to process the entire blog to generate an answer). We'll discuss optimizing inference time in the Optimizing with ONNX section.
The Boom of Foundation Models
Have you ever wondered how computers can understand and respond to human language? The answer lies in a new concept called ‘Foundation Models’. Popularized under this name by the Stanford University, these are machine learning models trained on immense amounts of data (over tens of terabytes, and growing) that can be adapted to a wide range of downstream tasks in fields such as image, text, and audio, among others.
LLMs, a type of Foundation Model, are particularly well-established in Natural Language Processing (NLP). These models are cutting-edge artificial intelligence, capable of producing human-like language with remarkable accuracy. They can be used to generate text for various tasks such as translation, summarization, paraphrasing, question answering, and even assisted coding.
These models come in different flavors and are often open-source. They can vary in size, the tasks they were pre-trained on, efficiency, and other characteristics. For example, the smallest LLMs have only a few million parameters, while the largest ones, such as the recently released Switch Transformers, have over a trillion.
Some of the most widely adopted LLMs are:
- BERT, developed by Google
- BLOOM, developed by BigScience Workshop
- GPT-J, the open-source version of GPT-3 developed by OpenAI
- OPT, developed by Meta
- T5, developed by Google
A comprehensive list of open-source language models can be found on 🤗 Hugging Face’s list of supported models. Thanks to 🤗 Hugging Face and the ML community for providing this huge open-source repository!
One recent example of the impressive capabilities of Foundation Models is ChatGPT, arguably one of the most incredible advances in AI history. This model, developed by OpenAI, is a fine-tuned version of GPT-3.5 (one of the latest versions of the GPT-3 model family). ChatGPT can be used through a simple chat interface to perform various tasks, including summarization, text generation, code generation, and question-answering on virtually any topic. What sets ChatGPT apart is its ability to produce highly detailed, complete, and human-like responses, admit mistakes and adjust replies based on the user's needs.
As the name suggests, Foundation Models can serve as the foundation for many applications, but they require fine-tuning and adjustments to get the most out of them. So keep reading to learn how to get them to their full potential!
Fine-tuning an LLM
1. Building a Dataset
There is a wide range of public datasets that you can use to fine-tune your model, but if you desire to improve the results for your specific task, you will probably need to build your own dataset. This might be a crucial task to achieve good results, albeit time-consuming.
Our goal was to build a chatbot that could answer questions about Tryolabs’ blog posts, so we created our own custom dataset, TryoCoQA, to fine-tune a Foundation Model that can interact with Tryolabs’ readers, just like yourself!
Like the CoQA dataset for conversational question answering, TryoCoQA consists of questions and answers about a specific context in a conversational manner, with some questions and answers referencing previous points in the conversation. We aimed for natural language questions with a variety of writing styles and vocabulary, and answers that can be short spans of text extracted from the context or free-form text, hoping for the model to produce more human-like responses with high-quality content.
The dataset and guidelines for building it are available in the following GitHub repository.
2. Choosing a Foundation Model
Selecting the right open-source LLM to fine-tune can be a tough choice. There’s a handful of them, and while they may perform quite well for a broad range of general tasks, it can be challenging to predict how well they will perform on our specific task before fine-tuning. Think of it like buying a new pair of dancing shoes - they may look great and feel comfortable, but you won't know how well they'll perform until you hit the dance floor.
In addition to wanting the model to perform well on our specific task, we also wanted to consider other factors, such as resource efficiency and the size of the dataset required for fine-tuning. We were looking for a model that could run on minimal resources and be fine-tuned with a small dataset.
Given our goal of building a QA chatbot for our blog posts and the constraints we have outlined, we zeroed in on T5 and its variants as a promising choice. T5 stands for “Text-To-Text Transfer Transformer.” Its philosophy is that it models every NLP task as a text-to-text problem. For example, in the task of Document Classification, T5 outputs a simple text containing the name of the predicted class for the document rather than outputting logits for all possible classes. In addition to this creative approach to NLP problems, we also liked that T5’s architecture is similar to the original transformer encoder-decoder architecture proposed in the ‘Attention Is All You Need’ paper.
One variant of T5 that stood out was FlanT5. It’s been fine-tuned on a wide range of downstream tasks and over 450 datasets, and it even performs well on zero-shot tasks, meaning it can obtain good results for a new task or dataset without training on it. Just what we needed! With a minimal dataset, one could fine-tune FlanT5 for a few epochs and obtain excellent results.
Of course, ML is not always that simple: our use case required processing whole blog posts, which can be very long. T5 and FlanT5 both use the popular self-attention mechanism, which has a quadratic increase in memory consumption with input size! In other words, to process a whole blog post — or worse, a batch of them — we would need an astronomical amount of memory.
Fortunately, another variant of T5, called LongT5, saved the day! LongT5, proposed by Google, is especially designed to process large inputs. It uses a different attention mechanism called TGlobal (Transient Global) Attention Mechanism, which requires far less memory and allows LongT5 to excel at numerous tasks that other transformer architectures can’t handle due to memory shortage, such as scientific paper summarization or QA about Wikipedia articles.
So LongT5 seemed like the right choice for efficient training and inference on our dataset, but it did pose a small problem. In contrast with FlanT5, LongT5’s available checkpoints weren’t fine-tuned on many tasks, so it didn’t perform very well on zero-shot scenarios. To address this, we fine-tuned LongT5 on a few publicly available datasets before training on our own data!

In summary
As you can see, selecting which model to train for your particular problem can be challenging as it generally involves many factors. So always try to consider the following:
- How well the model fits your specific task. You can dig deeper into the datasets and functions it was pre-trained on and do some zero-shot or few-shot rounds of evaluation on your own tasks and data.
- The size of your inputs and outputs. Some models may not scale well for large inputs and outputs due to high memory consumption or a substantial number of operations.
- The size of your dataset. If you have a small dataset, choose a more powerful model capable of zero-shot or few-shot learning. Nevertheless, the more data you have, the better results you will achieve.
- How much computing power is available for training and inference. This can be a significant factor in determining which models you can use, as larger models may not fit in your memory, or training may become painfully slow. You can use libraries like 🤗 Accelerate for distributed training to make the most out of your hardware.
All this can seem overwhelming, but don’t worry; here at Tryolabs, we can help you choose the right model for your needs! Contact us and get started on building your own fine-tuning pipeline.
3. Fine-tuning strategy
Once we selected the perfect Foundation Model, the next step was to prepare our data to be able to train on it.
One of the challenges we faced was that our dataset was relatively small, which could make it harder for the model to learn how to converse and answer questions about our blog posts.
But we had a plan! To give our model a head start, we first fine-tuned it on much larger and more general datasets. This way, the model was able to learn how to retrieve answers to general questions before focusing on the specific content of our blog posts.
We selected two available datasets, SQuAD2.0 and CoQA, and trained on them following two different schemes:
- Fine-tuning the model sequentially on each dataset, which means fine-tuning first on the SQuAD2.0 dataset, then on CoQA, and finally, on our dataset.
- Combining the datasets SQuAD2.0 and CoQA into one single dataset and fine-tuning on it, and when the training is over, fine-tuning sequentially on our dataset.
Combining the datasets resulted in slightly better performance, but both alternatives produced similar results.
In addition to deciding how to combine the datasets, we also needed to adapt our examples to T5's text-to-text input and output format. This involved restructuring and rewriting the context and questions in our inputs.
To refresh the reader’s memory, in the use-case of Conversational Question Answering, the goal of the model is to generate the answer to a question given a context and the previous questions and answers from the conversation. With this in mind, we formatted the inputs following this structure:
Here, the input is a text string containing the context (i.e., the content of one of Tryolabs blog posts) followed by the last two question-and-answer pairs in the conversation and the current target question, with the target output being the answer to the target question. We chose to add just the last two question-and-answer pairs to limit the amount of conversation history the model needs to pay attention to while still being able to generate coherent responses. Note that this is a hyper-parameter you can adjust when fine-tuning your own model.
With our data prepared and fine-tuning strategy determined, the final step was setting up our infrastructure environment and training the model.
4. 🤗 Accelerate
Fine-tuning a big Foundation Model can be computationally expensive, especially if you want to do it quickly. However, we can still train models with limited resources. There are various techniques to accommodate large models in small environments.
In our case, we used 2 x NVIDIA GeForce RTX 3090 GPUs, which had a total of 48GB VRAM. Although this setup seems to have excellent computing power and memory capacity, it was not enough to train the model independently. To accomplish the task, we had to use different techniques supported by 🤗 Hugging Face’s distributed training and inference library, 🤗 Accelerate.
The techniques that worked for us were:
- Using gradient accumulation, which lets you train on bigger batch sizes as the gradients get accumulated over several batches, and the optimization step is calculated after a certain number of them.
- Using gradient checkpointing to reduce memory consumption by forgetting the activations during the forward pass and recomputing them on the backward pass of each training round.
- Picking the right batch size to balance training speed and memory consumption.
- Choosing optimizers that consume less memory, such as Adafactor (the optimizer used in the original T5 and LongT5 papers).
- Tweaking parameters in the data loader, such as pinning the memory to the CPU and setting the right number of workers.
- Distributing the training across both GPUs to leverage the computing power available.
You can find more information on these techniques and how to use them in HuggingFace’s documentation, particularly in the “Efficient Training on a Single GPU” and “Efficient Training on Multiple GPUs” sections, as well as in 🤗 Accelerate’s documentation.
5. Evaluation
Apart from training the model, we wanted to evaluate what it was doing and how well it was performing.
Firstly, to correctly evaluate the training, we had to take a portion of the data to use as a validation split. Thankfully SQuAD2.0 and CoQA datasets already have a validation split. In the case of our dataset, we split our data into 85% training and 15% validation.
To assess its performance, we used the F1 Score by validating how many tokens appeared in common in both predictions and ground truth samples. We also used Exact match to see if the model was actually writing the same answer.
Since we had two different training steps, we also had two additional evaluation steps. The first training, on SQuAD2.0 and CoQa, resulted in a 74.29 F1 Score on the validation split after 3 epochs. The second training, on TryoCoQa, produced a 54.77 F1 Score after 166 epochs.

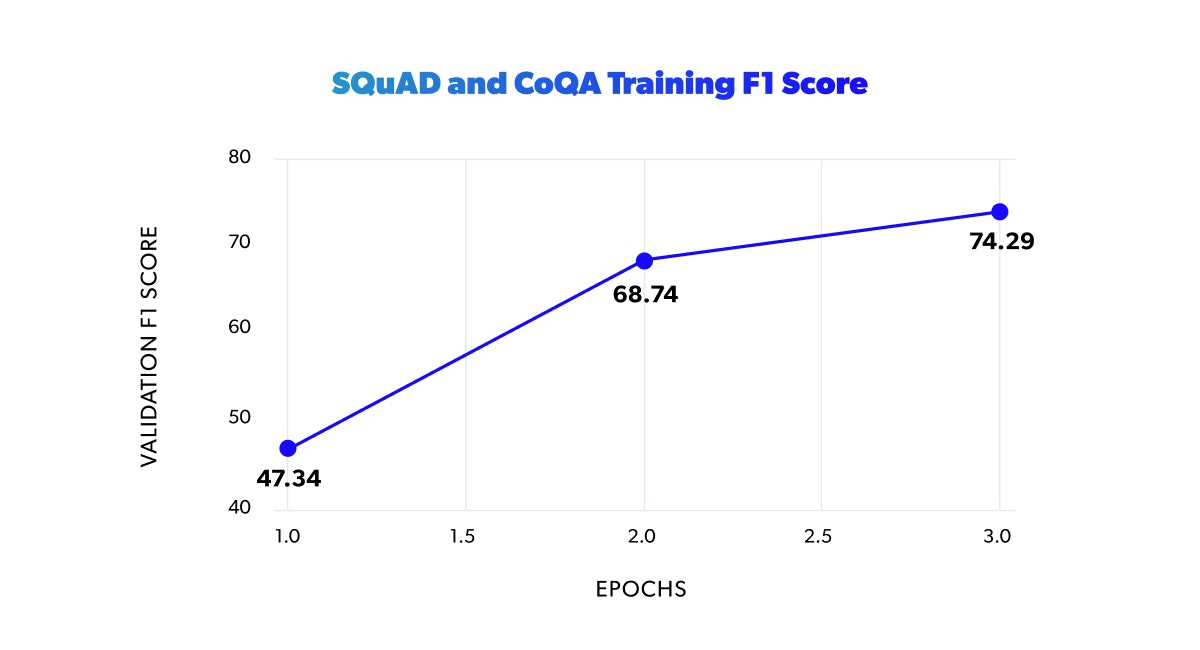
More than analyzing the quantitative metrics is required to evaluate these results and conversational models in general. It is essential to consider the qualitative aspect of the model's answers, like their grammatical correctness and coherence within the conversation context. Sometimes it is preferable to have better answers (qualitatively speaking) than a better F1. So we looked at some answers from the validation set to ensure that the model was correctly generating what we were looking for. Our analysis revealed that higher F1 scores were generally associated with greater-quality answers. As a result, we selected the checkpoint with the highest F1 score to use in constructing our demonstration chatbot.
If you want to play around with our fine-tuned model, you can find it on 🤗 Hugging Face with the ID tryolabs/long-t5-tglobal-base-blogpost-cqa!
Faster inference with 🤗 Optimum and ONNX
After fine-tuning our model, we wanted to make it available to our awesome readers, so we deployed it on 🤗 Hugging Face Spaces, which offers a free tier with two CPU cores for running inference on the model. However, this setup can lead to slow inference times, and processing significant inputs like ours doesn’t make it any better. And a chatbot that takes a few minutes to answer a question doesn't strike anyone as being particularly chatty, does it? So, to improve the speed of our chatbot, we turned to 🤗 Optimum and the ONNX Runtime!
In our previous blog post, A guide to optimizing Transformer-based models for faster inference, we used 🤗 Optimum and ONNX to achieve an 8x speed-up on inference for a Transformer model. Be sure to check it out!
Using 🤗 Optimum’s recently released exporters feature, we were able to convert our PyTorch model to the ONNX format. This feature is handy for encoder-decoder models like the LongT5 model we trained, as it exports the three main components separately: the encoder, the decoder with the Language Modeling head, and the same decoder with pre-computed hidden states as additional inputs. According to 🤗 Optimum’s documentation, combining these three components can speed up sequential decoding, which results in faster text generation.
Our fine-tuned model, exported to ONNX into these three components, is also available on 🤗 Hugging Face with the ID tryolabs/long-t5-tglobal-base-blogpost-cqa-onnx!
Once our model was exported to ONNX, we used 🤗 Optimum’s integration with the ONNX Runtime to optimize our model and run inference on it by using the ORTModelForSeq2SeqLM class. This class can optimize and downcast the model using ONNX’s tools and then use ONNX Runtime to run inference with this new, faster model! You can even take it one step further and quantize the model for even shorter inference time on CPU and lower memory consumption.
With these improvements, we achieved a 2x speed-up on inference time! Although the model still takes between 10 to 20 seconds to answer, this is a reasonable speed for a CPU-only deployment and processing such large inputs.

It’s worth noting that members of the ONNX community are actively working on tools for exporting and optimizing the latest ML architectures. The features mentioned in this section are fresh from the oven, thanks to the invaluable support of the ONNX team. Their work is crucial for unifying deep learning frameworks and optimizing models for faster and more cost-effective training and inference.
Improvements
We’re just scratching the surface of what’s possible. There are numerous potential improvements to keep working on to enhance the user's overall experience and the chatbot's performance. Here are some ideas to keep working on:
- Fine-tune on more public datasets for different downstream tasks. By doing so, we hope that the model learns to respond in a more human-like manner. For example, we could fine-tune on context-free QA datasets or on free-form answers so that the model not only retrieves the answers from the context but also generates original answers. We could also fine-tune on summarizing or paraphrasing tasks so that the user can also ask the chatbot to rewrite certain parts of the blog or summarize entire sections!
- Increase the size of our dataset. We built a small dataset for this demo, so it's not surprising that the model doesn't generalize well to new unseen blogs. We could potentially train a more accurate model by providing it with more training data.
- Optimize training using ONNX Runtime. We could achieve better results in the same amount of time if we could train for more epochs or fit a larger version of LongT5 in the same amount of memory. To do this, we could leverage the optimization power of ONNX Runtime for training PyTorch models, which would allow us to accelerate training speeds and optimize memory usage. Thanks to the recently released 🤗 Optimum integration with ONNX Runtime for training, this can be done in just a few lines of code!
Takeaways
With the ever-increasing popularity of LLMs, it can seem almost impossible to train these models without having access to millions of dollars in resources and tons of data. However, with the right skills and knowledge about Foundation Models, Deep Learning, and the Transformer architecture, we showed you that fine-tuning these huge models is possible, even with few resources and a small dataset!
Fine-tuning is the key to unlocking the full potential of Foundation Models for your business. It allows you to take a pre-trained model and adapt it to your specific needs without breaking the bank.
And the best part? We're here to help you every step of the way. If you're ready to see how fine-tuning can benefit your business, don't hesitate to reach out, and let's get started on your fine-tuning journey today!

Wondering how AI
can help you?

Terms and Conditions | © 2026. All rights reserved.