

Top Python libraries of 2020





Welcome to the sixth yearly edition of our Top Python Libraries list!
The rules are simple. We are looking for libraries that satisfy the following conditions:
- They were launched or popularized in 2020.
- They are well maintained and have been since their launch data.
- They are outright cool, and you should check them out.
Disclaimer: this year, our picks are heavily influenced by machine learning / data science libraries, although some can indeed be very useful for non-data science people. Moreover, although we have 10 main picks — and a bonus — we decided to add a new "Honorable mentions" section that does justice to other libraries that we found and couldn't leave out.
The spirit of this post is to give some visibility to these libraries, as well as generate discussion (in the comments or elsewhere) around some other great picks we may have missed — which we are sure there are.
So, without further ado, let's get to it.
1. Typer


You don't always need to write CLI applications, but it better be a hassle-free experience when you do. Following the great success of FastAPI, tiangolo used the same principles to bring us Typer: a new library that enables you to write command line interfaces by leveraging the type hinting feature of Python 3.6+.
The design really makes Typer stand out. Apart from making sure your code is properly documented, you get a CLI interface with validations with minimal effort. And by using type hints, you can get autocompletion in your Python editor (like VSCode), which will boost your productivity.
To power its capabilities, Typer internally stands on top of Click, which is very well-known and battle-tested. This means that it can leverage all its benefits, community and plugins, while starting simple with less boilerplate code and growing more complex as you need.
As always, the documentation really shines and should be exemplary for other projects. Definitely, one not to miss!
2. Rich
Following with CLI's topic, who said terminal applications have to be monochromatic white, or green if you're a real hacker, on black?
Do you want to add color and style to your terminal output? Print complex tables in a heartbeat? Effortlessly display beautiful progress bars? Markdown? Emojis? Rich checks all the boxes. Look at the sample screenshot for a glimpse of what's possible:

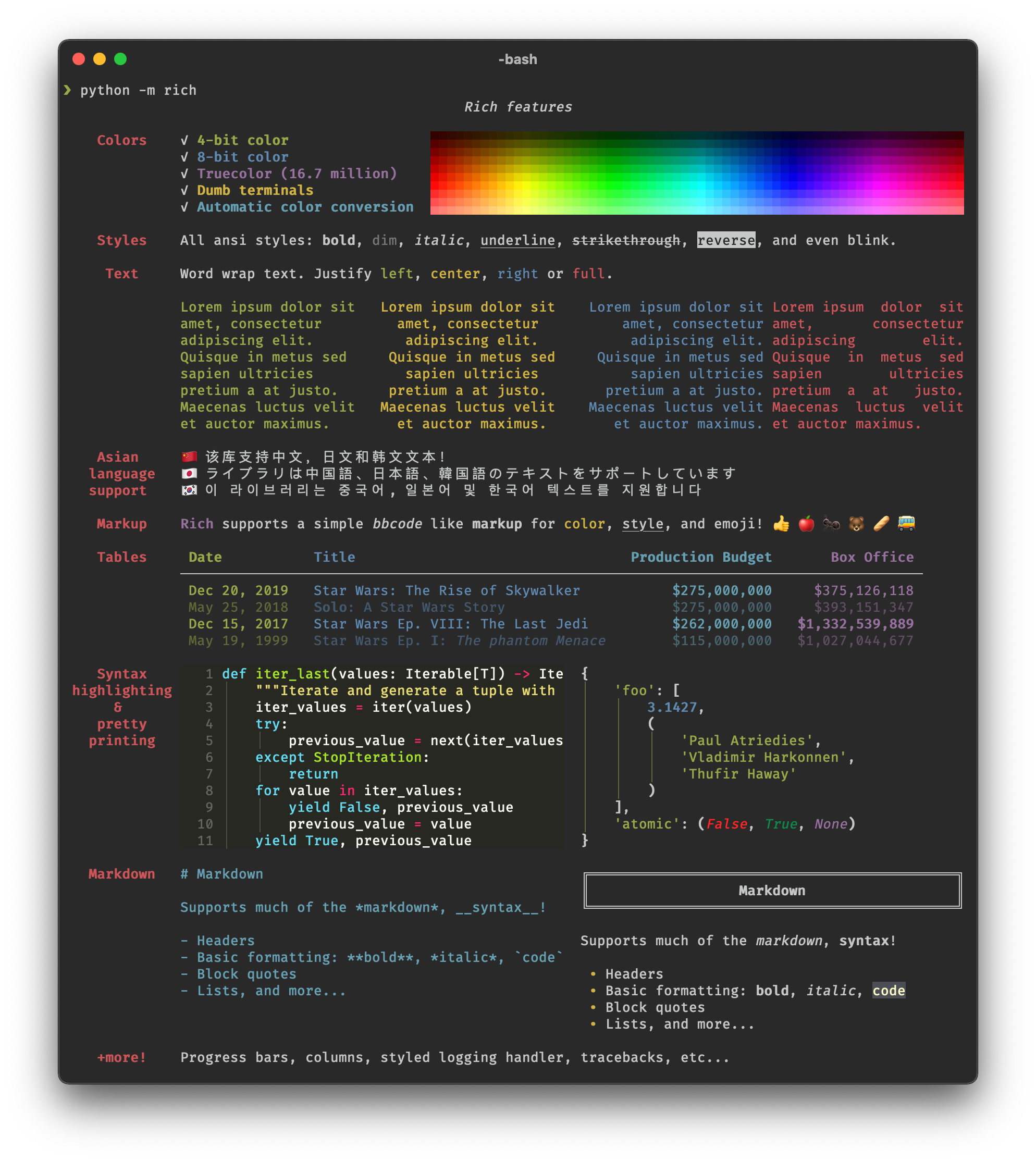
Definitely a library that elevates the experience of using a terminal application to a whole new level.
3. Dear PyGui
Although, as we've seen, terminal applications can be beautiful, sometimes it's not enough and you need a real GUI. For this comes Dear PyGui, the Python port of the popular Dear ImGui C++ project.
Dear PyGui utilizes what's called the immediate mode paradigm, popularized in video games. This basically means the dynamic GUI is drawn frame by frame independently, without the need to persist any data. This makes this tool fundamentally different than other Python GUI frameworks. It's highly performant, and uses your computer's GPU to facilitate the construction of highly dynamic interfaces, as is often needed in engineering, simulations, games or data science applications.

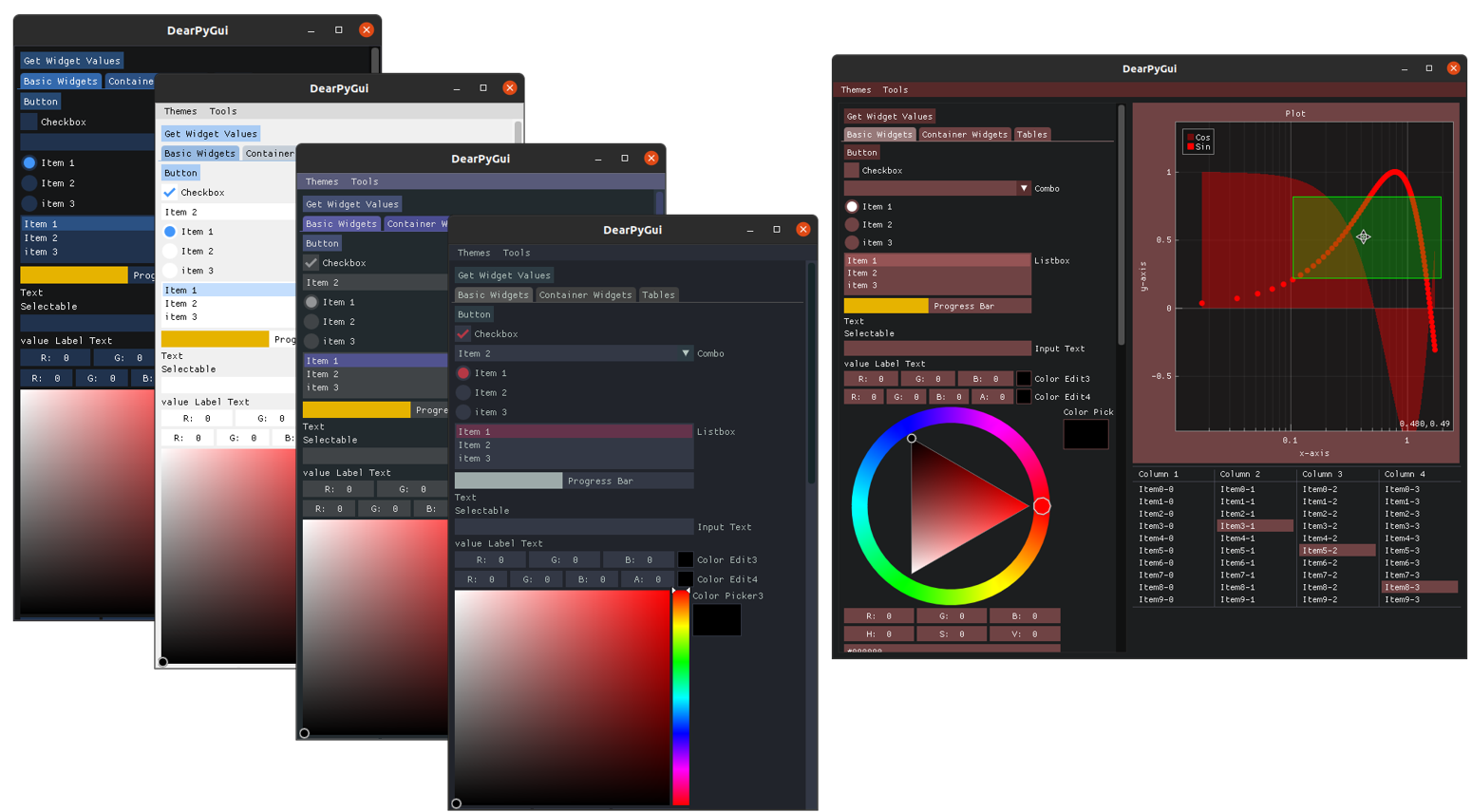
Dear PyGui can be used without a steep learning curve, and runs on Windows 10 (DirectX 11), Linux (OpenGL 3) and MacOS (Metal).
4. PrettyErrors
The joy of simplicity. This is one of the libraries that make you think: how is it that nobody thought about this before?
PrettyErrors does only one thing and does it well. In terminals that support colored output, it transforms the cryptic stack traces into something that is much better suited for parsing with our puny human eyes. No more scanning the entire screen to find the culprit of your exception... You can now find it at a glance!

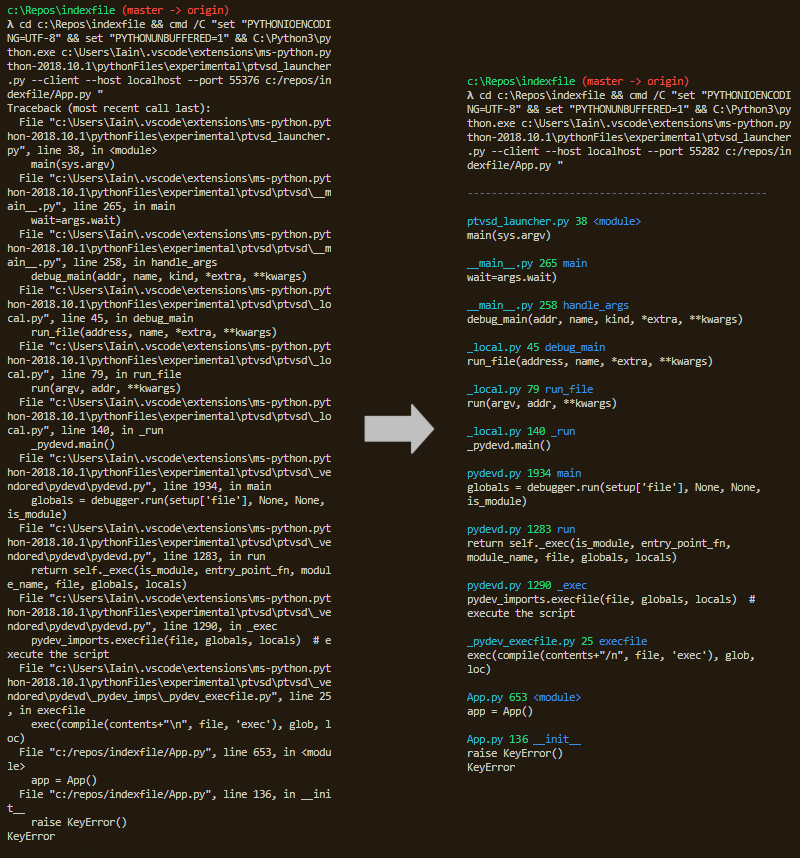
5. Diagrams
We programmers like to solve problems and code. But sometimes, we need to explain intricate architectural designs to other colleagues as part of the very much needed project documentation. Traditionally, we have resorted to GUI tools where we can work on diagrams and visualizations to put in presentations and documents. But it's not the only way.
Diagrams lets you draw the cloud system architecture without any design tools, directly in Python code. It has icons that will come in handy for several cloud providers, including AWS, Azure, GCP. It makes it dreadfully easy to create arrows and groups. Really, it's only a few lines of code!

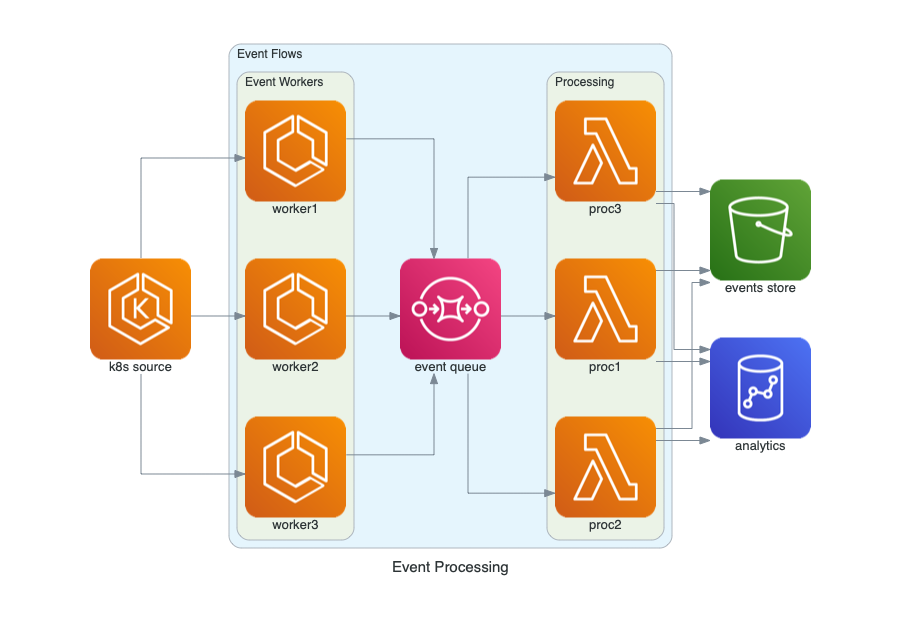
The best thing of code-based diagrams? You get the ability to track changes with version control via your standard git! Developers will be happy.
6. Hydra and OmegaConf
When doing research and experimentation on machine learning projects, there's always a myriad of settings to try out. In non-trivial applications, configuration management can become rather complicated, pretty fast. Wouldn't it be nice to have a structured way of dealing with this complexity?
Hydra is a tool that allows you to build configurations in a composable manner, and override certain parts from the command line or config files.
To illustrate some of the common tasks that can be simplified with the library, let's say there's a base architecture of a model we're experimenting on, and multiple variations of it. With Hydra, a base configuration can be defined, and then multiple jobs be run with variations of them:
python train_model.py variation=option_a,option_b
Hydra's cousin, OmegaConf, provides a consistent API for the base of the hierarchical configuration system, supporting different sources like YAML, config files, objects and CLI arguments.
A must for doing configuration management in the 21st century!
7. PyTorch Lightning
Every tool that increases the productivity of a data science team is worth gold. There is no reason to make people that work in data science projects re-invent the wheel every time, think over and over again how to better organize the code in their project, use some "PyTorch boilerplate" that is not very well maintained, or trade potential control for using a higher level abstraction.
Lightning helps boost productivity by decoupling the science from the engineering. It is sort of like Keras for TensorFlow, in the sense that it makes your code a lot more concise. However, it does not take your control away. It's still PyTorch, and you have access to all the usual APIs.
This library helps teams leverage software engineering's good practices around organization and clear responsibilities of components, to build high quality code that can easily scale to train on multiple GPUs, TPUs and CPUs.

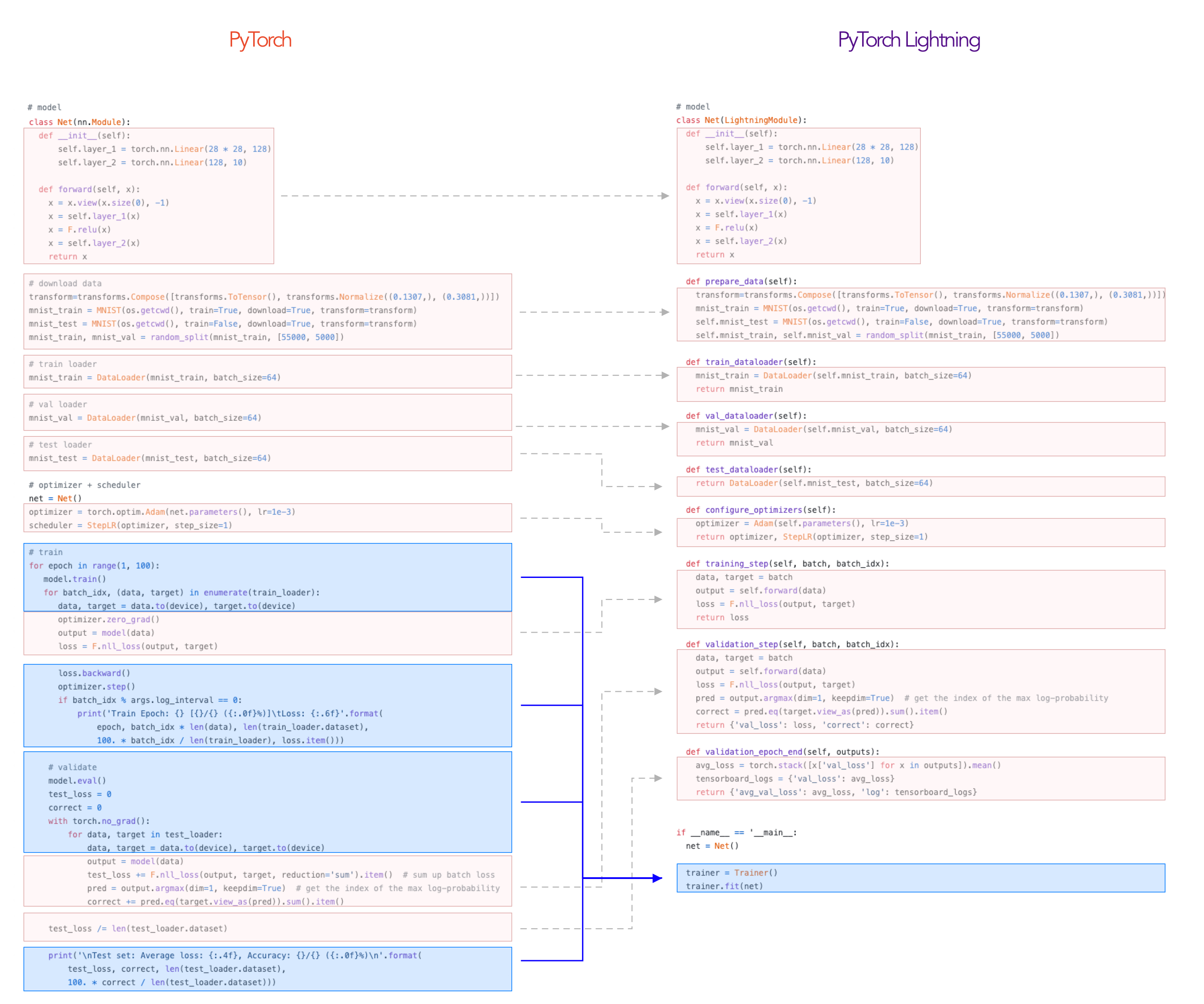
A library that will help those junior members of the data science team produce better results, but also, more experienced members will love it because of the increase in overall productivity, without giving up control.
8. Hummingbird


Not all machine learning is deep learning. Very often, your models consist of more traditional algorithms implemented in scikit-learn (such as Random Forest), or you use gradient boosting methods like popular LightGBM and XGBoost.
However, a lot of advancements are happening in the deep learning field. Frameworks like PyTorch are advancing at a breathtaking pace, and hardware devices are being optimized to run tensor computations faster and with lower power consumption. Wouldn't it be nice if we could leverage all this work, to run our traditional methods faster and more efficiently?
Here is where Hummingbird comes in. This new library by Microsoft can compile your trained traditional ML models into tensor computations. This is great, because it frees you of the need to re-engineer your models.
As of now, Hummingbird supports conversion to PyTorch, TorchScript, ONNX, and TVM, and a variety of ML models and vectorizers. The inference API is also very similar to the Sklearn paradigm, which lets you reuse your existing code but changing your implementation to what's generated by Hummingbird. This is a tool to keep an eye on, as it gains support for mode models and formats!
9. HiPlot
Nearly every data scientist has worked with high dimensional data at some point during their career. Unfortunately, human brains are not adequately wired for dealing with this kind of data intuitively, so we must resort to other techniques.
Early this year, Facebook released HiPlot, a library that helps discover correlations and patterns in high-dimensional data using parallel plots and other graphical ways to represent information. The concept is explained in their launch blog post, but it's basically a nice and convenient way of visualizing and filtering high dimensional data.

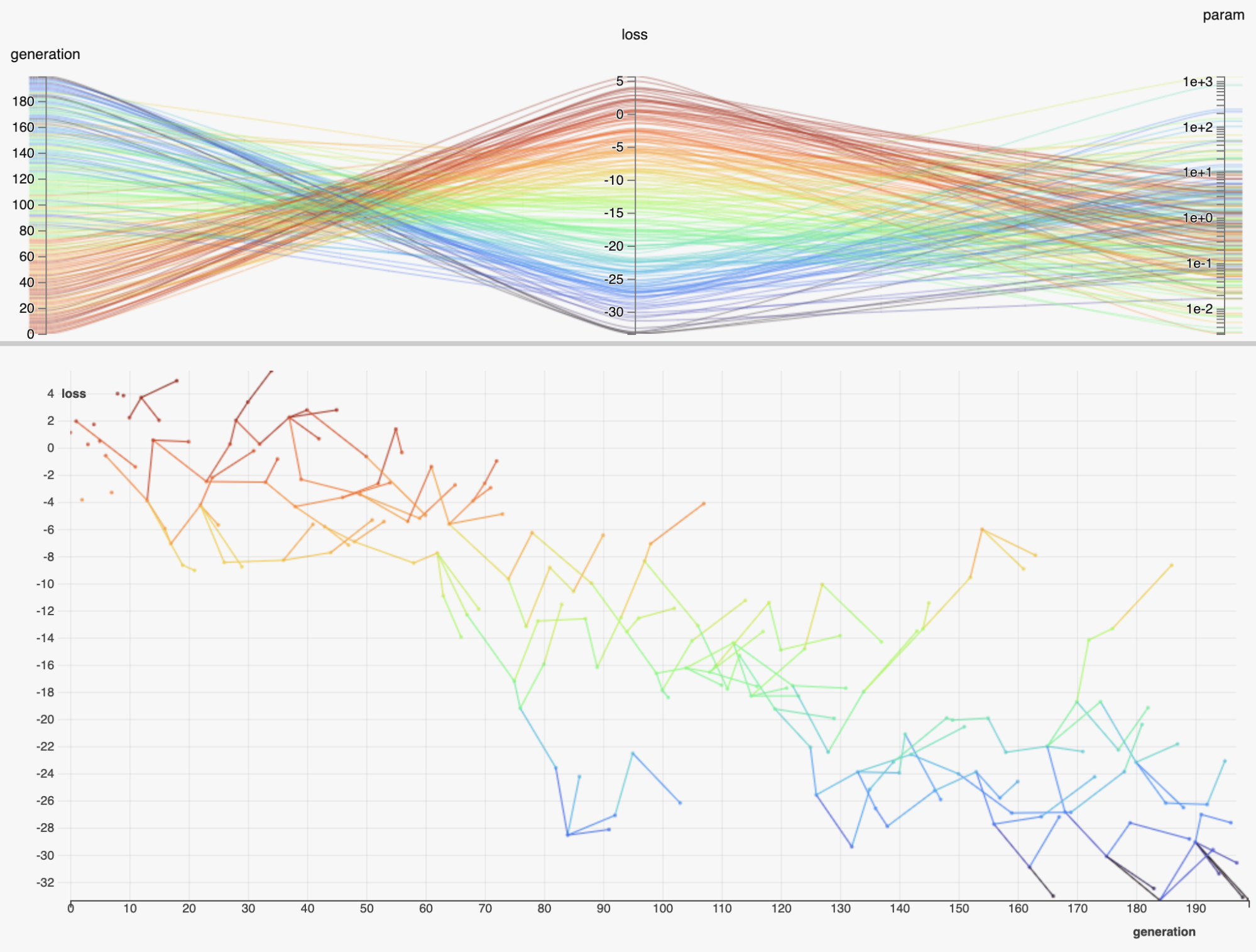
HiPlot is interactive, extensible, and you can use it from your standard Jupyter Notebooks or via it's own server.
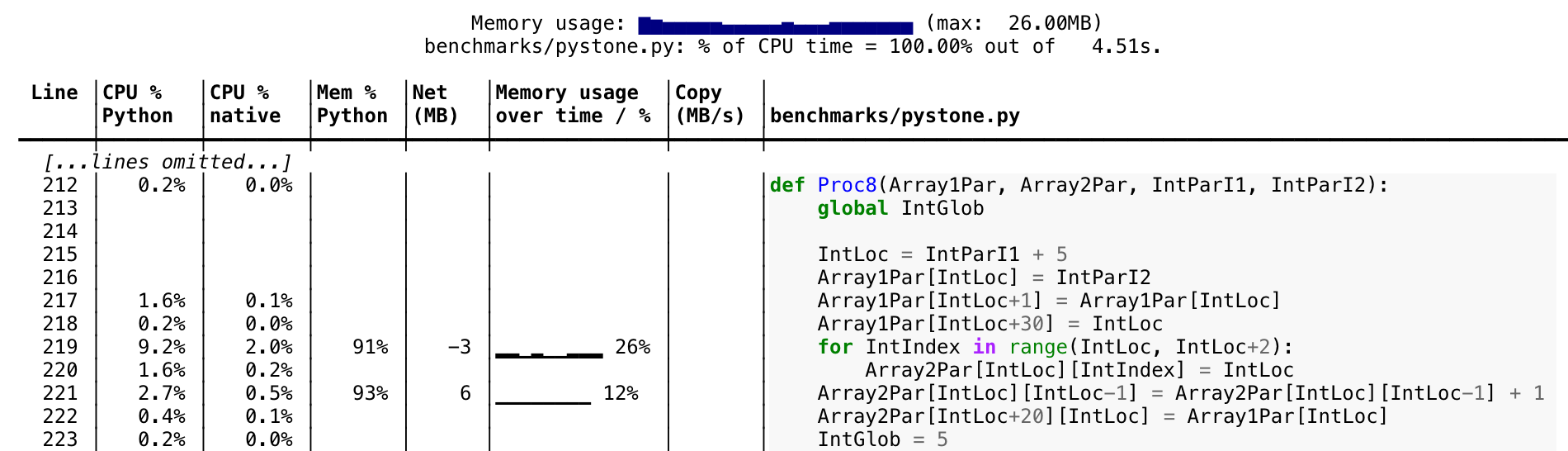
10. Scalene
As the ecosystem of Python libraries grows increasingly more complex, we find ourselves writing more and more code that depends on C extensions and multi-threaded code. This becomes a problem when it comes to measuring performance because the profilers built into CPython don't handle multi-threaded and native code properly.
That's when Scalene comes to the rescue. Scalene is a CPU and memory profiler for Python scripts capable of correctly handling multi-threaded code and distinguishing between time spent running Python vs. native code. There's no need to modify your code, you just need to run your script from the command line with scalene and it will generate a text or HTML report for you, showing CPU and memory usage for each line of your code.

Bonus: Norfair
We couldn't finish this list without including our own homegrown baby for video analytics applications.
Norfair is a customizable lightweight Python library for real-time object tracking. In other words, it assigns a unique id to every detected object in different frames, letting you identify them as they move through time. Using Norfair, you can add tracking capabilities to any detector with just a few lines of code. "Any detector"? Yes. No matter what the object representation looks like: a bounding box (4 coordinates), a single point centroid, the output of a human pose estimation system with a variable number of key points above a certain probability threshold, or anything else.

The function used to calculate the distance between tracked objects and detections is defined by the user, making it fully customizable if you need it.
It's also fast and it can run real-time. However, the real beauty is that it is very modular, and you can take your existing detection codebase and add tracking capabilities to it, with only a few lines of code. We are welcoming any comments and suggestions, and work on improving the capabilities of Norfair every day!
Honorable mentions
- quart — an async web framework with Flask-compatible API. Some of the existing Flask extensions will even work!
- alibi-detect — monitor outliers and distribution drift in your production models, for tabular data, text, images and time series.
- einops — popularized in 2020, einops lets you write tensor operations for readable and reliable code, supporting numpy, PyTorch, TensorFlow, and others. Recommended by Karpathy, do you need anything else?
- stanza — accurate natural language processing tools on 60+ languages, from Stanford. Multiple available pre-trained models for different tasks.
- datasets — from HuggingFace, lightweight and extensible library to easily share and access datasets and evaluation metrics for Natural Language Processing (NLP) and more
- pytorch-forecasting — eases timeseries forecasting with neural networks for real-world cases and research alike.
- sktime — provides dedicated time series algorithms and scikit-learn compatible tools for building, tuning, and evaluating composite models. Also check their companion sktime-dl package for deep learning based models.
- netron — a visualizer for neural network, deep learning and machine learning models. Supports more formats than I even knew existed.
- pycaret — wraps several common ML libraries and makes you vastly more productive, saving you hundreds of lines of code.
- tensor-sensor — helps you get the dimensions of your tensor math right, by improving error messages and providing visualizations.

Wondering how AI
can help you?

Terms and Conditions | © 2026. All rights reserved.