

Finding the right representation for your NLP data


When considering what information is important for a certain decision procedure (say, a classification task), there's an interesting gap between what's theoretically ---that is, actually--- important on the one hand and what gives good results in practice as input to machine learning (ML) algorithms, on the other.
Let's look at sentiment analysis tools as an example. Expression of sentiment is a pragmatic phenomenon. To predict it correctly, we need to know both the meaning of the sentences and the context in which those sentences appeared. How do you get the meaning of a sentence? Well, you need to know the meaning of the lexical items and the sentence's syntactic structure. So, the relevant data points are the following.
- The meaning of the lexical items used.
- The syntactic structure of the sentences.
- The context in which those sentences appeared.
It might be surprising, then, to learn that sentiment analysis tools traditionally use Bag of Words (BoW) to represent texts. The only thing that counts is which words appear in the text and how frequently. So, "Dancing Monkeys in a Tuxedo is better than any other movie" has the same representation as "any other movie is better than Dancing Monkeys in a Tuxedo". They will yield the same result, regardless of the size and quality of the training set. But we use BoW representations because they give excellent results in sentiment analysis tools. So why does it work anyway? I'll get to that in a second.
Imagine you're presented with a relatively novel natural language processing (NLP) problem. Something that hasn't been explored extensively in the literature. For example, say your client wants to predict how likely it is for a user to order food to some restaurant called Rest-a-uraunt based on users' textual reviews of restaurants (including Rest-a-uraunt) on some food ordering site.
You know what to do. You'll use ML techniques. You can use a supervised algorithm if you can find the following information.
- Textual reviews of restaurants.
- For each review, whether or not the user later ordered to Rest-a-uraunt.
There's still a few things you have to decide. One is which ML algorithm to use. Another one is how to represent user reviews. In some cases, you can use deep learning techniques to learn the representation automatically so that you don't have to answer this second question. In practice, though, even when using neural networks the first step is finding the right representation for your data. Especially in NLP.
Few NLP problems are tackled with ML techniques using actual text (i.e. a sequence of characters) as the algorithm's input. Most normally, you'll get an intermediate representation of your text that has the information that your algorithm needs and doesn't have too much noise. So, one of the big questions for developers working in NLP is how do you decide what representation to use? In other words, how do you know what data is relevant?
This is the structure of the problem:
- What is the relevant information?
- What is the best way to represent it?
- General considerations.
- Considerations specific to the algorithm used.
You know that what's theoretically important isn't always what's useful as input to your ML algorithm, but there must be other criteria. There's no hard-and-fast rule but I'll give you some pointers.
Tips when choosing a representation for your data
Distance matters
Your algorithm isn't as intelligent as it seems. It gives impressive results because it's fed well-structured data. For example, most classifiers work by grouping elements that are close together in a vector space. Their job amounts to finding the boundaries between classes. They won't work if the elements of the same class are far away from each other and intercepted by members of a different class.
Your main objective when deciding how to represent your data is to make sure that 'distance' in your vector space is a meaningful relation. In other words, that things that are close together behave similarly with respect to what you need to know about the data. BoW has that characteristic. The distance relationship is obviously meaningful. If two BoWs are close together in the vector space, that means they have similar amounts of the same words.
For certain features, it's trivial to make the distance relation meaningful. Say, if your feature is the length of the longest word or the linear distance between two words, then that will be an integer, and 'close' values in that feature will mean you have similar lengths. Simple. On the other hand, embedding syntactic structures in a vector space while making the distance relation meaningful is not quite as easy. Embedding word meanings in vector space is also not trivial, but we've gotten pretty good at it with Word2Vec, GloVe, etc.

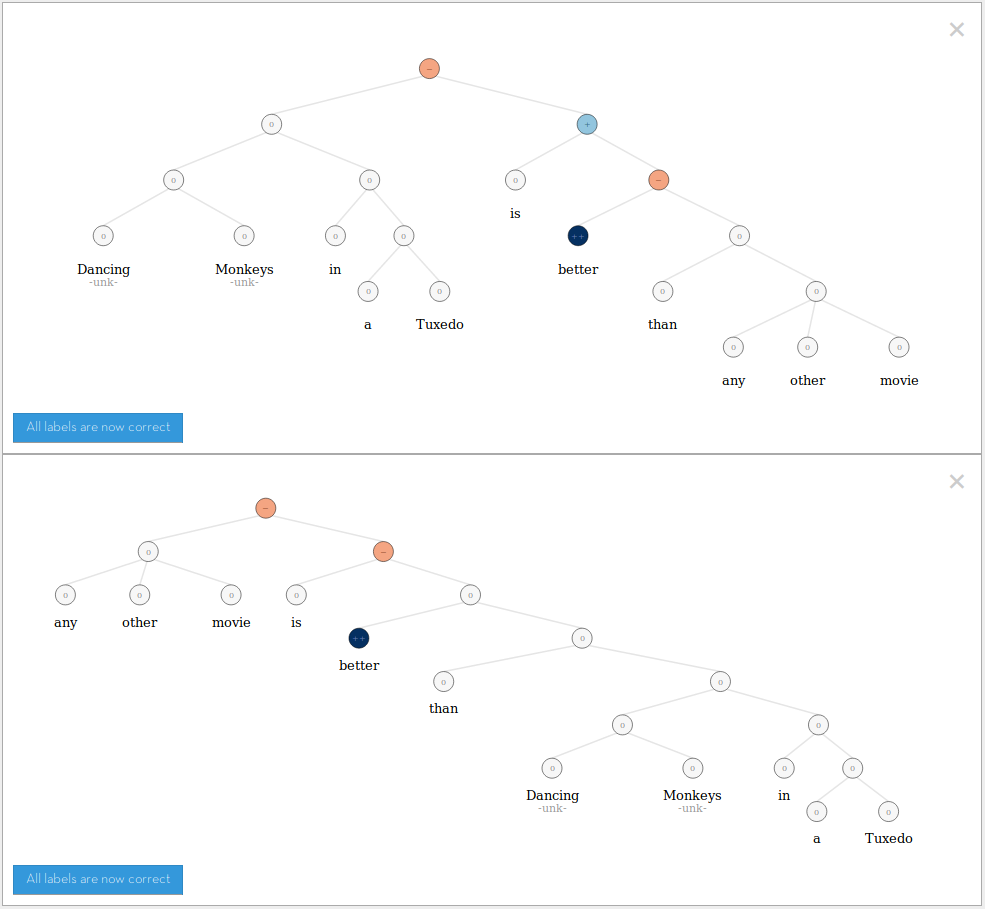
Things got much easier with recurrent neural networks and recursive neural networks. With them, you can shift the focus from representing entire sentences and paragraphs as vectors and instead treat them by dealing with individual words iteratively or recursively. You can use an actual tree of word embeddings as a representation. So, for your Rest-a-uraunt project you can parse all sentences in the review and use a recursive neural network to visit all nodes in the tree bottom-up, calculating probability-of-a-future-order-to-Rest-a-uraunt scores. This is likely not what you want to do, as it will take a very long time to train and perhaps a prohibitively long time to calculate scores after it's been trained. But something similar has been done before at Stanford NLP, and it's nice to know you could do it this way if everything else fails.
Funnily enough, when I tried the two Dancing Monkeys in a Tuxedo sentences with Stanford's recursive sentiment analysis tool, it classified both sentences as negative. When I changed 'Dancing Monkeys in a Tuxedo' to 'this movie', it classified both as positive.

Linear algorithms have special needs
It's a well known fact that most traditional linear classification algorithms approximate your classes to shapes with straight boundaries in your input vector space (i.e. the boundaries are hyperplanes) . In some cases of binary classification, they will try to find a single straight boundary dividing your two classes. This fact often goes unexplained, so let's give a brief explanation.
Linear ML algorithms learn a vector of weights w of the same length as the input vector x. In each prediction, they calculate the dot product of x and w. The result is the input's score. This score may be given as the final result, or used as input to some other (often simple) rule. In the case of classification algorithms often a rule is used to relate score intervals to classes. Your rule may be 'if the score is bigger than 10, then the user will likely order to Rest-a-uraunt later'.
Let's look at the case where we use a vector with two features as input and as the vector of weights. The score then is
If our rule for classification is 'if the score is bigger than k, then we classify it as A', then our boundary for class A is
Which is the same as
That's the equation of a line! If you start with three features instead of two you'll get a plane, and so on. Every time you use score intervals to classify, you'll get straight boundaries.
So, if you represent your data in such a way that classes can easily be separated by straight lines (or planes, etc.), your linear algorithm will do a better job at separating your classes.
Let me show you an example of how you can get it wrong. Imagine Rest-a-uraunt specializes in pasta. You may decide to use the following approach to predict whether or not a certain user will in the future order to Rest-a-uraunt:
- Extract reviews made by that user to other restaurants.
- Use a sentiment analysis tool to classify reviews into positive and negative ones.
- Use a linear classifier to get a score of each review indicating how likely it is that the user will order to Rest-a-urant based on a BoW of the review and the pre-computed sentiment.
- Aggregate the scores you computed for all of the user's reviews (you could take the average, for example).
You will train the classifier in point 3 with reviews tagged with a sentiment and an indication of whether or not the user later ordered to Rest-a-uraunt.
The idea is that if the user uses pasta-related words a lot in their review and they show a positive sentiment at the same time, they're likely to order to Rest-a-uraunt in the near future. You're thinking your linear algorithm may be able to figure that out. Well, if you don't structure your input correctly, it likely won't.
Remember your linear algorithm learns a weight for each feature in the input. That means that if you represent sentiment with a single feature, a positive sentiment will impact the score either always positively or always negatively. But you want your algorithm to interpret a positive sentiment as a sign that the user is likely to order to Rest-a-uraunt only when combined with a high frequency of certain words ('pasta', 'Italian', etc.) but to interpret it as a sign that it's unlikely they'll order when other words are frequent ('celiac', for example).
What you can do in this case is to restructure your input vector so that instead of having a unique, separate feature for the sentiment of the review, you use feature combinations (also called feature crosses) so that all word frequency features include information about the sentiment.
For example, you can have two features for each word. The first one will be 0 if the sentiment is negative, and have the number of occurrences (or a tf-idf score) of the word if the sentiment is positive. The other one will work the other way around, 0 if the sentiment is positive, the number if it's negative. This way your algorithm will be able to assign a weight to the combination of a word's frequency and a positive or negative sentiment, which is what you wanted. When you need the combination of two or more features to be especially meaningful for your linear algorithm, you'll need to cross your features like this.
Your algorithm is guessing
Part of the reason why ML techniques are so successful is that they aren't only doing the logical, theoretically sound, inferences that you were thinking about when you implemented your algorithm, if they're doing them at all. They're also finding statistical regularities that don't make sense theoretically but work in practice.
Remember the example where you used a BoW and a pre-computed sentiment analysis for your Rest-a-uraunt project? Okay. You implemented the algorithm following my advice about how to structure your features and it's giving good results when tested with your cross-validation set. Congrats! Now, if you check how it works (i.e. what words combined with which sentiment have a high weight, etc.) you might be surprised.
You were thinking pasta-related words combined with a positive sentiment was indicative of a possible future order to Rest-a-uraunt. You were probably right. What you may not have foreseen is that your algorithm is also using all kinds of general-purpose words to make inferences. Words that don't seem to have any relationship with pasta, sentiments, or whatever.
What's going on? Well, your algorithm is using 'hidden' statistical correlations that don't really make much sense in the grand scheme of things but happen to work. This is good! ML algorithms solve impressive problems because they do this. It's one of the ways they can (often) beat rule-based systems. They see the correlations your engineer can't see.
That means sometimes information that seems irrelevant ends up helping your algorithm. Sometimes is key here. Adding everything you can find won't work. That said, it's a good idea to fiddle around with your features a bit, to see what works. Some things you can't plan in advance. Remain flexible!
Too much guessing is dangerous, though. It can lead to overfitting. It can also trick you into thinking your algorithm works better than it does. For example, you might test your algorithm with a small data set and find out it works reasonably well. Yet, if your algorithm is mostly just guessing, it won't scale. Guessing has a very low ceiling.
So, if you're too surprised when you check your algorithm's learned weights, you should take it as an indication that it might not be doing a good job.
Final remarks
In conclusion, when using ML techniques in NLP, you should always pay attention to what information you need to feed your algorithm and how you can represent that information to get the best results. To sum up the issue, let's repeat what I called 'the structure of the problem' above.
- What is the relevant information?
- What is the best way to represent it?
- General considerations.
- Considerations specific to the algorithm used.
Data representation problems will sometimes lead you to the right ML algorithm. Recurrent and recursive neural networks allow you to represent your data in ways you can't with other algorithms. Linear algorithms have special needs that you may not be able to satisfy easily. You can't get the best results if you pick your algorithm without thinking about the way you want to represent your data.
Links
Here are some links if you want to learn more about this topic. The keyword here is 'feature engineering':
General:
- Discover feature engineering
- Basic feature engineering with time series data in Python
- Learning data science: feature engineering
- Feature engineering for deep learning
- Non-mathematical feature engineering techniques
NLP-specific:

Wondering how AI
can help you?

Terms and Conditions | © 2026. All rights reserved.