

Thu, Jun 11, 2020

Data anonymization is the alteration process of personally identifiable information (PII) in a dataset, to protect individual identification. This concept has acquired increasing importance over the past few years, and it has become an ongoing topic of research. New information about privacy concerns around the world appears each day, making it hard to keep track of the latest models and techniques, and it's even harder to enter this data privacy-related world without knowing some basic concepts.
This fast growing field is already part of the agenda, but in-depth research is still on-going and not much available. In this post you will find the main highlights of data anonymization and guidance on how to get involved.
To do so, we will review some fundamental ideas to facilitate a better understanding of these concepts, including:
- how it is done: formats, process, and data anonymization techniques
- how it impacts machine learning applications
Anonymizing personal data
This section is strongly based on Domingo-Ferrer, Sánchez and Soria-Comas work.
As there are multiple techniques and approaches that can be used to anonymize different data, we first need to identify the data format and content to be anonymized; does it consist of personal data, images, videos, files, or geospatial information? We also need to know what we need the anonymized information for, as this will determine the tradeoff between data utility and preservation of privacy.
Personal data releases attract most of the attention nowadays because of the information that can be extracted and inferred from them. However, they are also the ones presenting most of the privacy concerns. When a personal data release is made, it usually follows one of these formats:
- Microdata: in the statistical world, the term microdata refers to a record that contains information related to a specific individual. A microdata release is, in fact, a set of microdata records.
- Tabular data: imagine a traditional output of official statistics, where aggregate values are shown for groups of individuals. That is exactly what a tabular data release is. Some examples that follow this format can be found at Worldometer.
- Queryable databases: also known as interactive databases, these are databases to which statistical queries (such as sum, average, etc.) can be submitted.
As mentioned before, microdata releases are the ones that provide the most detailed information and, therefore, are harder to anonymize. We'll consider a microdata set containing personal data records -- also called personally identifiable information -- where each record refers to a different individual. A record consists of a set of attributes where each attribute describes some characteristic of the individual, such as name, age, marital status, and so on.
Attributes have a type, which include numeric, categorical, date, and geocoded, for example, and each type can be anonymized using different approaches. In this section, we'll contemplate the first three types. Geocoded information will be treated in its own section.
Usually, the attributes in a microdata set are classified according to the following non-exclusive categories.
- Identifiers: also known as direct identifiers, these are attributes that provide an unambiguous re-identification of the individual to which the record refers to. If a record contains an identifier, any sensitive information contained in other attributes may immediately be linked to a specific individual. To avoid direct re-identification of an individual, these attributes must be removed or encrypted. Some examples of this category are SSN and passport number.
- Quasi-identifiers: unlike an identifier, a quasi-identifier attribute alone does not lead to record re-identification. However, a combination of quasi-identifier attributes may allow for the unambiguous re-identification of some individuals. These attributes are required to perform any useful analysis of the data and, therefore, they can't be removed from the dataset. Deciding whether an attribute should be considered a quasi-identifier is not a trivial issue. Some examples of this category are marital status, age, and occupation.
- Confidential attributes: attributes that contain sensitive information on individuals are considered confidential. One of the primary goals of microdata protection techniques is to prevent intruders from learning confidential information about a specific individual. Examples include information about salaries and health conditions.
- Non-confidential attributes: non-confidential attributes are those that do not belong to any of the previous categories.
When we talk about an anonymization process, we're implicitly considering two datasets. The first one is the original dataset that holds the initial data, and the second one is the anonymized dataset, which is the result of applying one or more anonymization techniques to the original dataset. This last dataset is the one that we will release.
Below is an extract from the book mentioned at the beginning of this section that shows an original microdata set and an anonymized version of it, including its attribute classification.

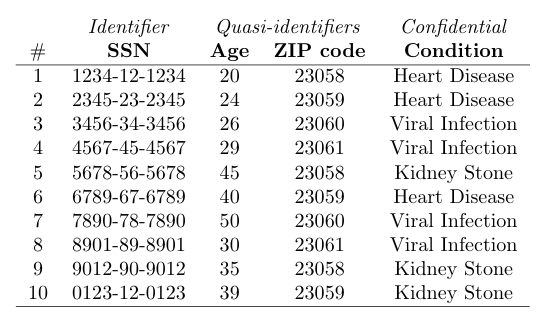

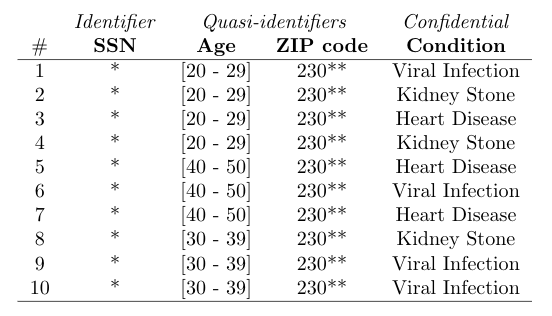
To ensure how successful an anonymization process is, we need to quantify how much exposure the data within the anonymized dataset has to the known disclosure risks. There are two types of these:
- Identity disclosure occurs if an intruder is able to associate a record of the released dataset with the individual it describes.
- Attribute disclosure occurs if an intruder is able to infer the value of a confidential attribute of an individual with enough accuracy.
Besides quantifying how much exposure your data will face once it's anonymized, you'll also need to identify any other external database that could potentially be combined with the information on your release and could lead to privacy leak. The Netflix Prize Dataset is an example of how not considering any other source of information can generate a complete re-identification of users. More information about how to measure disclosure risks can be found at the SDC site.
Privacy protection techniques
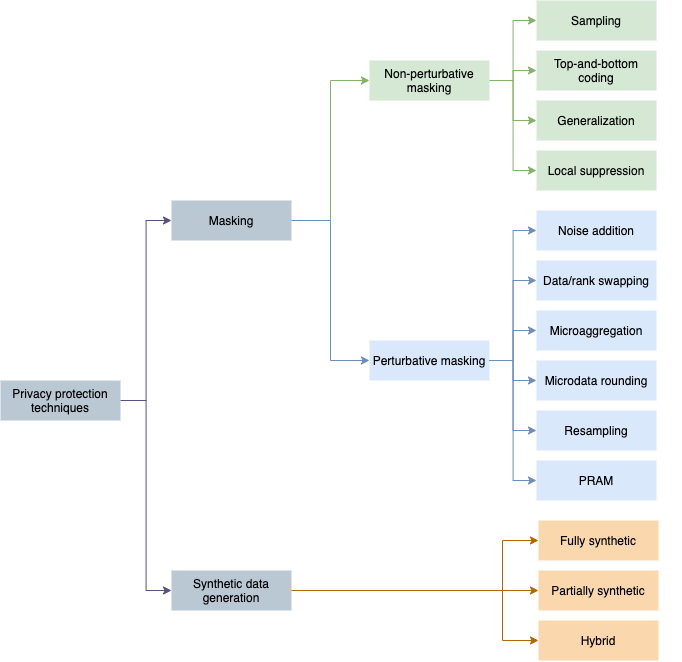
Maintaining data privacy consists of mitigating disclosure risks. To do so, there are different privacy protection techniques and models that can be applied. These techniques are able to generate an anonymized dataset by either masking the original data or generating synthetic data.
Masking approaches generate the anonymized dataset by modifying the records of the original dataset, creating a relationship between the records of the two datasets. Masking methods can be divided into two categories depending on how they are applied to the original data.
- Non-perturbative masking: these methods mitigate the disclosure risks by producing partial suppressions of, or reductions in, detail in the original dataset. Sampling, generalization, top-and-bottom coding, and local suppression are examples of these methods.
- Perturbative masking: unlike non-perturbative methods, perturbative masking changes the statistical distribution of the original dataset's attributes. The perturbation method used should be such that the statistics computed on the perturbed data set do not differ significantly from the statistics obtained from the original dataset. Examples of perturbative masking methods are noise addition, microaggregation, data/rank swapping, and PRAM.
Below you will find a brief description of some of the most used techniques.
Generalization
Generalization techniques achieve anonymization by reducing the detail of the original data. They can be used on numerical, categorical, and date type attributes. Generalization is also known as global recoding in statistical disclosure control literature.
For numerical and date type attributes, generalization means replacing the original value with a discretized version of it. This discretized version is usually a range of values, or a timelapse in date type cases. Meanwhile, for categorical attributes, new categories containing more specific ones are created.
In order to reduce the level of detail, such techniques use a structure referred to as Hierarchy or Taxonomy Tree. One structure is needed for each quasi-identifier and contains all the possible values that the quasi-identifier can take. Some examples are displayed below.

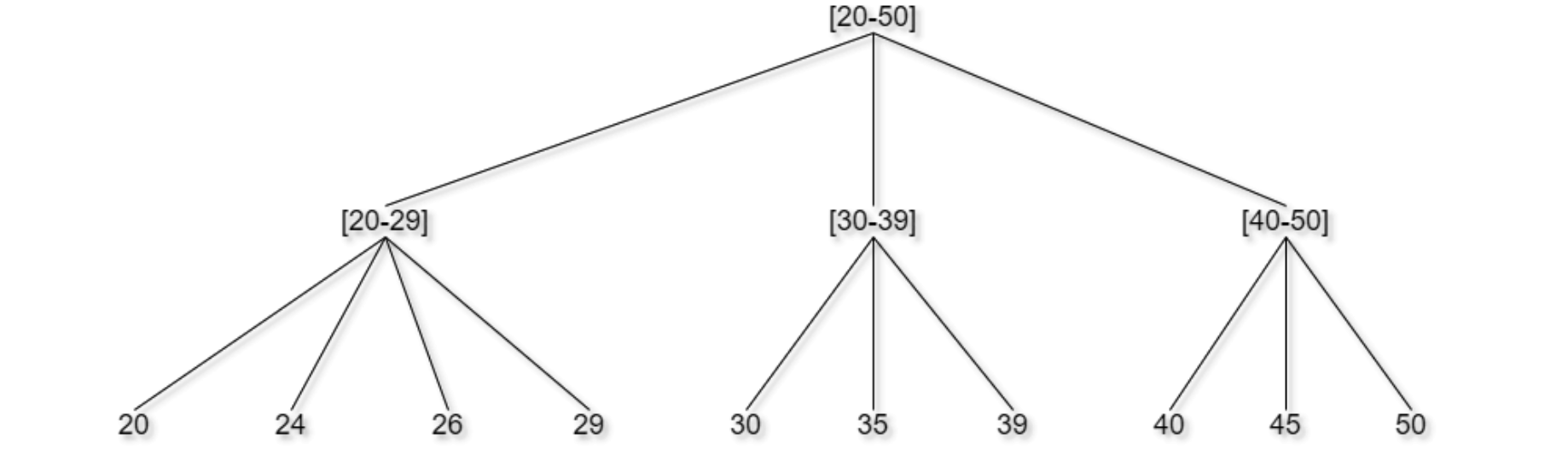

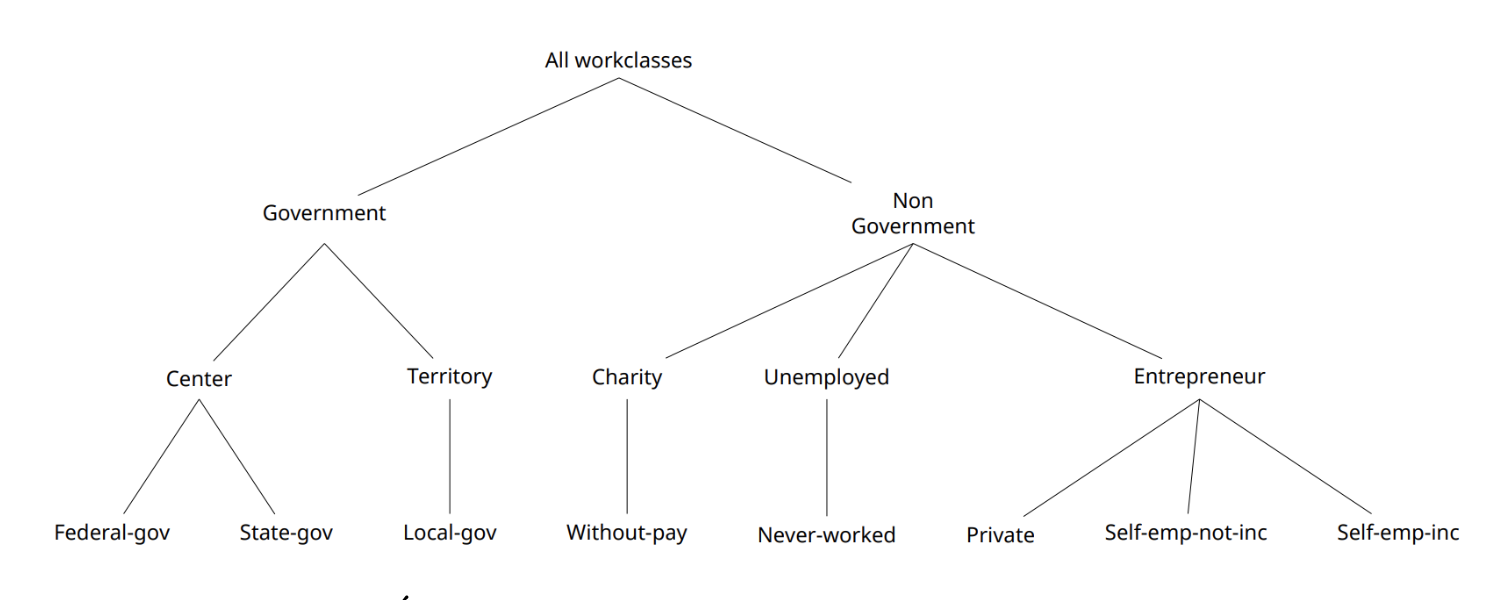
Top-and-bottom coding
This is a special case of generalization. It can be used on attributes that can be ranked, like numerical or categorical ordinal.
The idea behind this technique is to define a threshold for each quasi-identifier and express all the values as greater than or equal to or less than the threshold. For example, if the threshold for attribute Age is 35, all the values of this quasi-identifier in the anonymized dataset will be ≥ 35 or < 35.
Local suppression
This technique relies on the practice of suppressing certain values of some attributes in order to expand the set of records containing a combination of key values. The values that are suppressed are those with few appearances in the original dataset due to the fact that they represent a high disclosure risk for those records that contain them.
Microaggregation
This is a technique for numerical attributes only. The rationale behind microaggregation is that confidentiality rules allow for publication of microdata sets if records are within groups of k or more individuals, where no individual dominates the group, and k is a threshold value. Those sets are created by replacing individual values with values computed on small aggregates. This means that for each attribute, the average value for each group is computed and replaces each of the original values.
Synthetic data
A totally different option for anonymizing a dataset is to generate an independent dataset that's not derived from the original one. This is called synthetic data generation, and it’s based on creating a new set of records that preserve some statistics from the original set. There are three types of synthetic data sets:
- Fully synthetic: every attribute value for every record is synthesized. The records contained in the anonymized dataset are not the original ones, but a new sample from the underlying population.
- Partially synthetic: the only data that's generated are the attributes which present high disclosure risk.
- Hybrid: the original dataset is blended with a fully synthetic one.

Privacy models
Now that we know which approaches can be used to anonymize certain types of attributes, we need to choose the most appropriate privacy model for our situation and determine which aforementioned technique we'll utilize to implement it.
The first thing that should come to mind when choosing a privacy model is our purpose, which is to mitigate disclosure risks. That's why we'll need to choose at least one model that counters identity disclosure and one that combats attribute disclosure. Some privacy models are described below.
k-anonymity
k-anonymity is a popular privacy model used to mitigate identity disclosure risk. It is sometimes seen as meeting the minimum requirement for limiting disclosure risk, and is later complemented by protection against attribute disclosure.
The general idea is to generate groups within the dataset, where each group contains at least k records and the records of a group share the same value for every quasi-identifier. In other words, within a group, records are indistinguishable from one another. This condition causes the probability of re-identifying an individual in the anonymized dataset to be 1/k at most. Each group is considered an equivalence class, and a dataset is said to possess the k-anonymity property if each equivalence class has at least k records.
This model can be implemented using various approaches, including generalization and microaggregation.
The greatest challenge is to determine the value of the k parameter, as no heuristics are known to automatically set this value given a specific context.
k-Map
k-Map is a very close friend of k-anonymity. The main difference lies in that the k-Map model is capable of considering another dataset, in addition to the original one, in order to achieve the privacy requirement.
Beyond the challenge of choosing the proper value for the k parameter, k-Map faces another major problem: how to find or construct the extended dataset.
One limitation of this model is that it assumes that an intruder only handles the information provided by the anonymized dataset without access to any external sources purveying additional data that can be used for re-identification purposes.
ℓ-Diversity
This model is an extension of k-anonymity and it was designed to handle some of its weaknesses.
The ℓ-diversity model is based on the principle that protecting identities to the level of k-individuals is not the same as protecting the corresponding confidential values. That's why it attempts to mitigate the attribute disclosure risk by ensuring that each confidential attribute presents at least ℓ “well-represented” values within each equivalence class (the model's definition is vague in the sense that it does not specify the meaning of “well-represented” values).
Besides the lazy definition, another challenge to overcome is the suitable selection of the parameter ℓ.
t-Closeness
Like ℓ-Diversity, t-Closeness protects against attribute disclosure risk. It requires that the distance between the distribution of a confidential attribute in each equivalence class, and the distribution of the attribute in the whole dataset, is no more than a threshold value of t.
The challenges with this model are the definition of the notion of distance to be used and the selection of the parameter t.
Differential privacy
Differential privacy is a model that has become quite popular because of the strong privacy guarantees it provides. It's commonly used in queryable databases, but it can sometimes be applied to a microdata set.
The principle underlying differential privacy is that the presence or absence of any single individual record in the database or data set should be unnoticeable when looking at the responses returned by the queries.
The assumption is that anonymization algorithms sit between the user submitting queries and the database answering them. These algorithms rely on incorporating random noise into the mix so that everything a user receives becomes noisy and imprecise.Thus, it is much more difficult to perform a privacy breach.
Sometimes, differential privacy is not considered a privacy model in and of itself but an actual outcome of the anonymization process.
Other privacy models
Other known privacy models are Population uniqueness, δ-Disclosure privacy, β-Likeness, δ-Presence, and Profitability. It is worth mentioning that most privacy models present variants for specific applications in specific contexts or to certain characteristics of the original dataset.
For more information about privacy models and techniques, you can refer to SDC or ARX docs.
Tools
Data anonymization can be achieved using some anonymization tools or by custom programming implementations.
One of the most heavily used open-source tools is ARX, which allows the user to apply different privacy models to a given dataset.

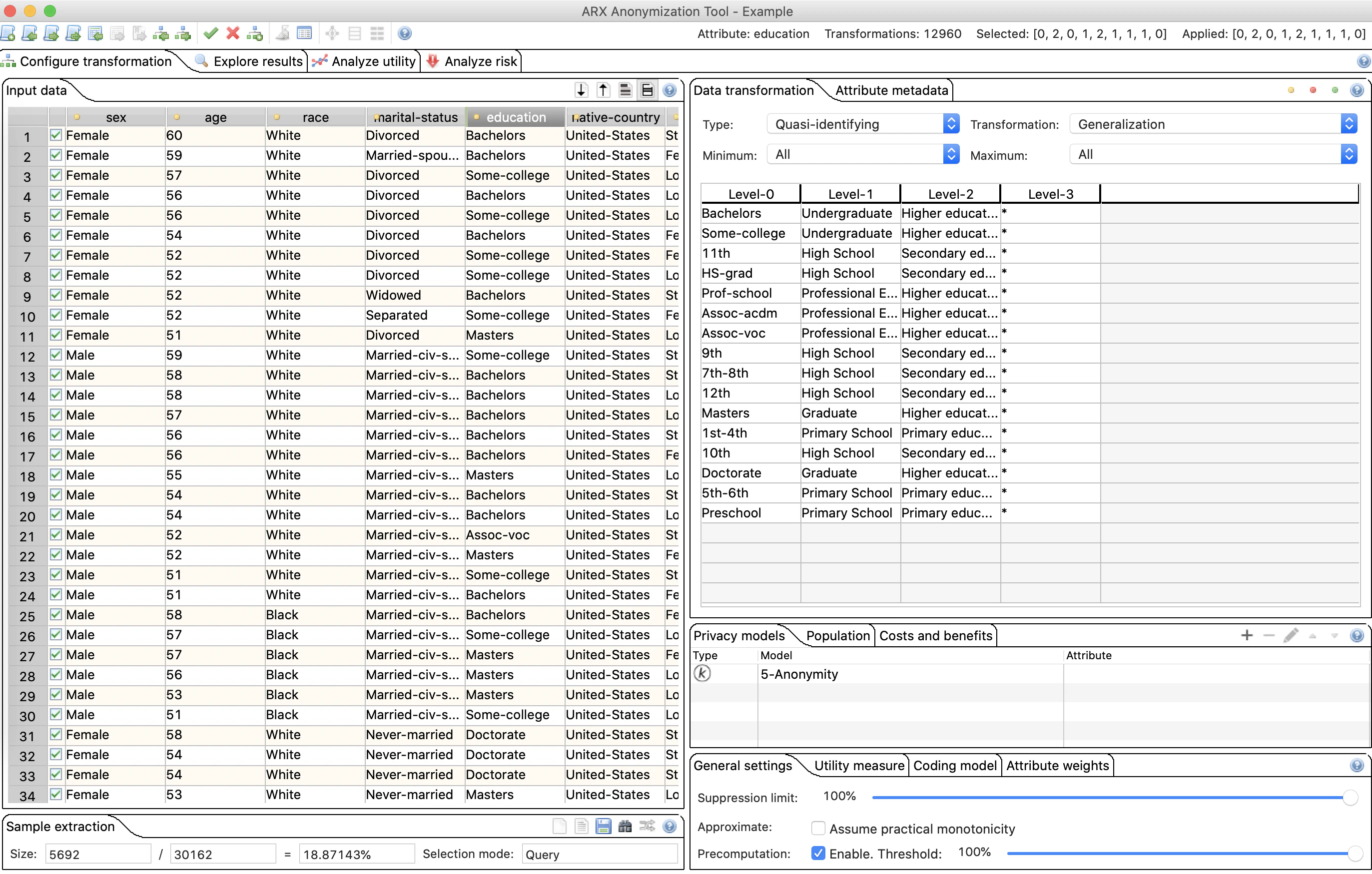
Besides possessing multiple alternatives and customization opportunities, ARX offers an evaluation of the resulting anonymized dataset by providing the user with a data utility and risk analysis, among other things.

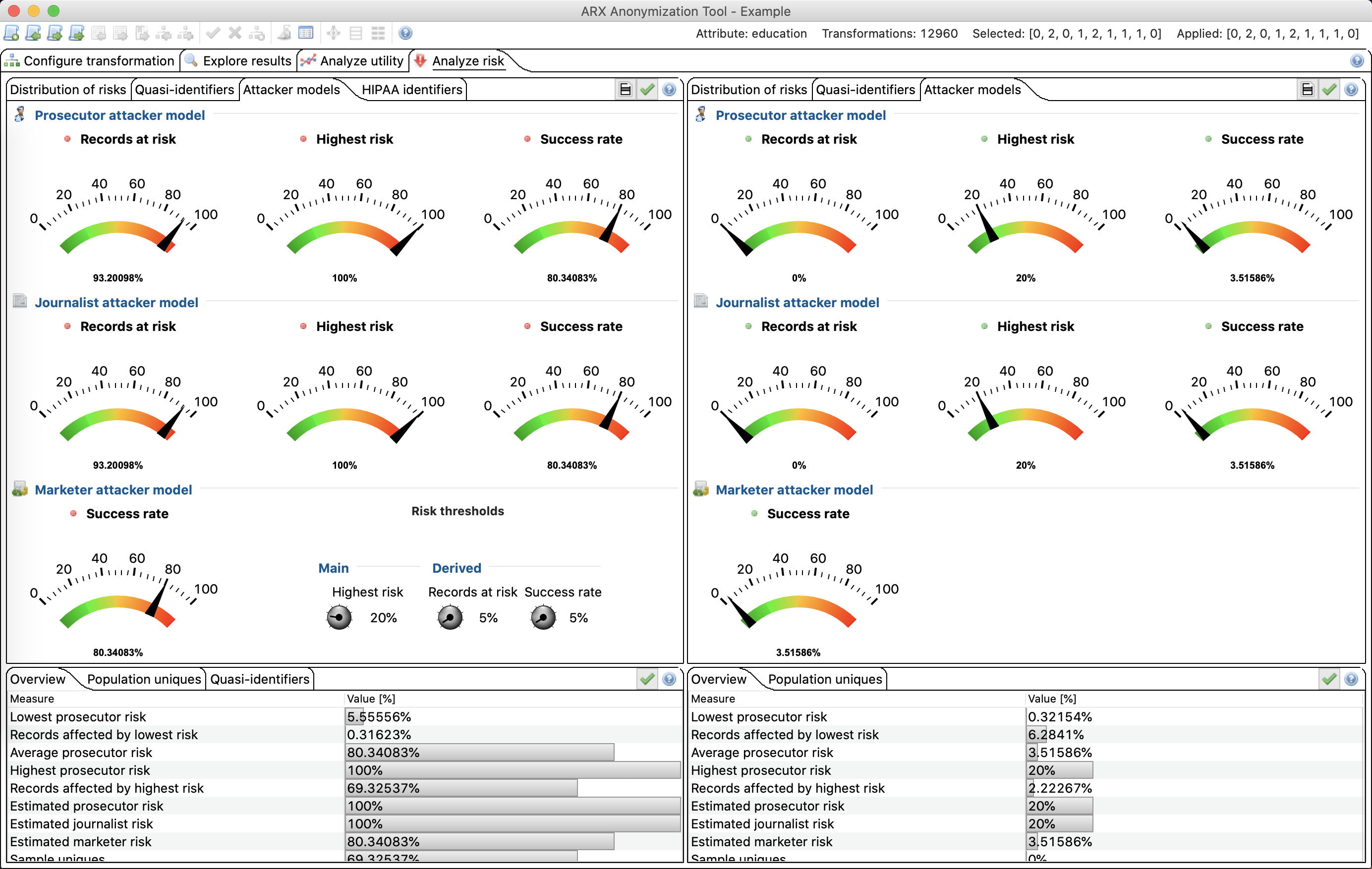
Another great tool is Amnesia. This tool has a very intuitive UI and implements the k-anonymity privacy model along with some variations of it.

If you're not a big fan of UIs, you may try some programmatic tools such as Anonimatron (used to anonymize database information), or if you're connected to the R-project world, the sdcApp. If this interests you further, you can try Google's differential privacy tool that was released to the community some months ago.
Anonymizing geocoded information
Anonymizing geographic data is far from being a simple task. Indeed, it’s a major challenge and an open research problem.
The issue with this data type is that it provides a piece of extremely precise information about an individual, making disclosure risks more difficult to address. Most of the existing techniques used to anonymize this type of information tend to work relatively well in areas with high population density, but present some weaknesses when applied to less dense areas. It's typically believed that there are two ways to deal with this information: generalization and geomasking.
Generalization
The Generalization technique explained earlier replaces information such as geographic coordinates with more abstract concepts. For example, instead of a specific point, we could refer to a street, neighborhood, zip code, zone, or even an entire state. The abstraction level to use depends on the data's nature and its density. Figure 2 depicts an example of the application of this technique.
The major challenge with the approach deals with establishing the relationship of an address or coordinates to the corresponding neighborhood, zip codes, and on. This process can involve the use of geocoding or reverse geocoding.
Geomasking
A completely different option is to use the approach known as geomasking, which proposes applying some affine transformations to coordinates in order to perturb/move the points within a delimited area so as to create some distortion or noise around the original point. Transformations can include rotations, translations, area definitions, random point selections, and more.
Paul Zandberg provides an excellent review of some available transformations in his 2014 paper. Also, if you wanna take a closer look, Maskmy.xyz is an open-source tool that implements a particular masking technique. An example is shown in figures 6 and 7.

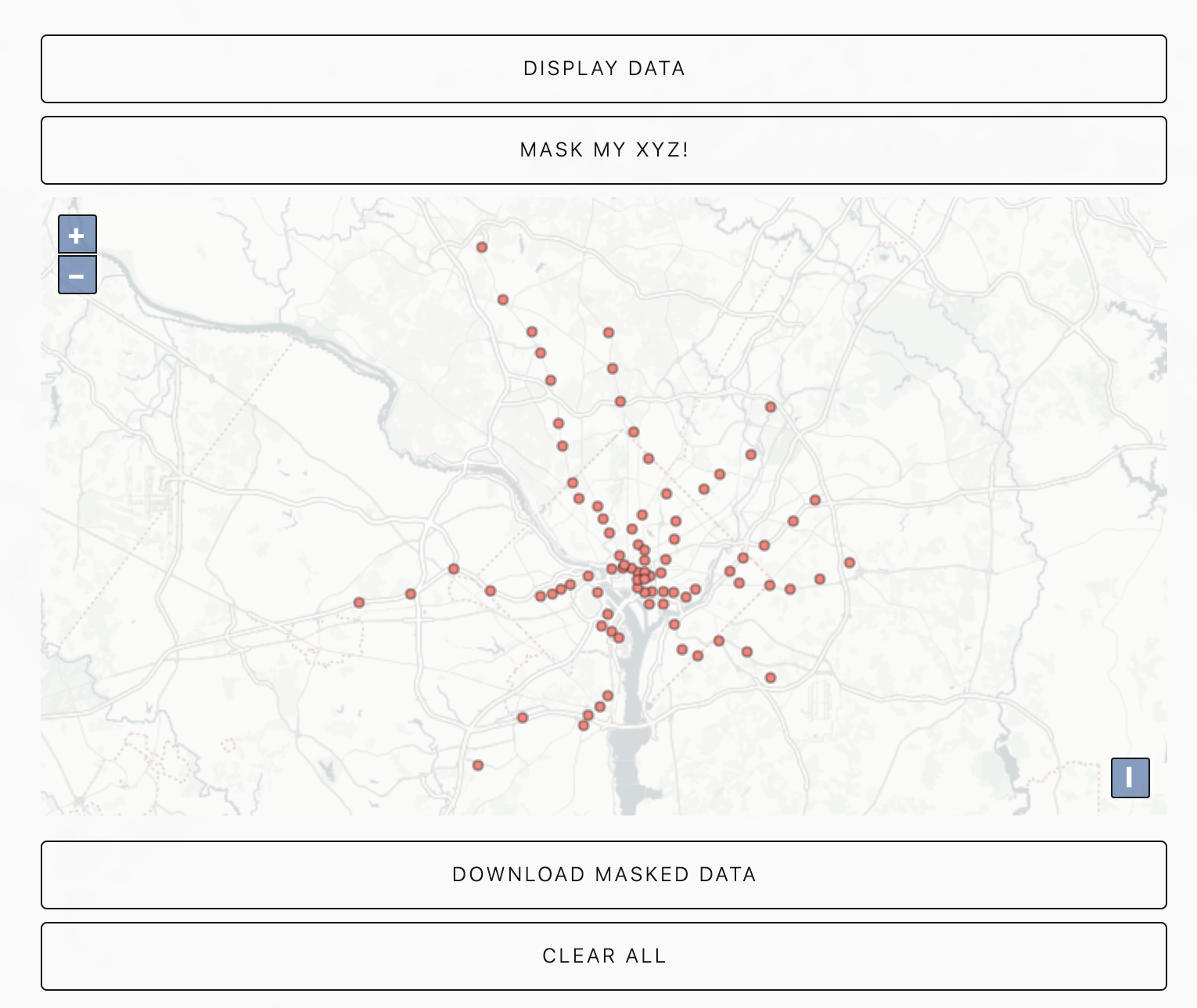

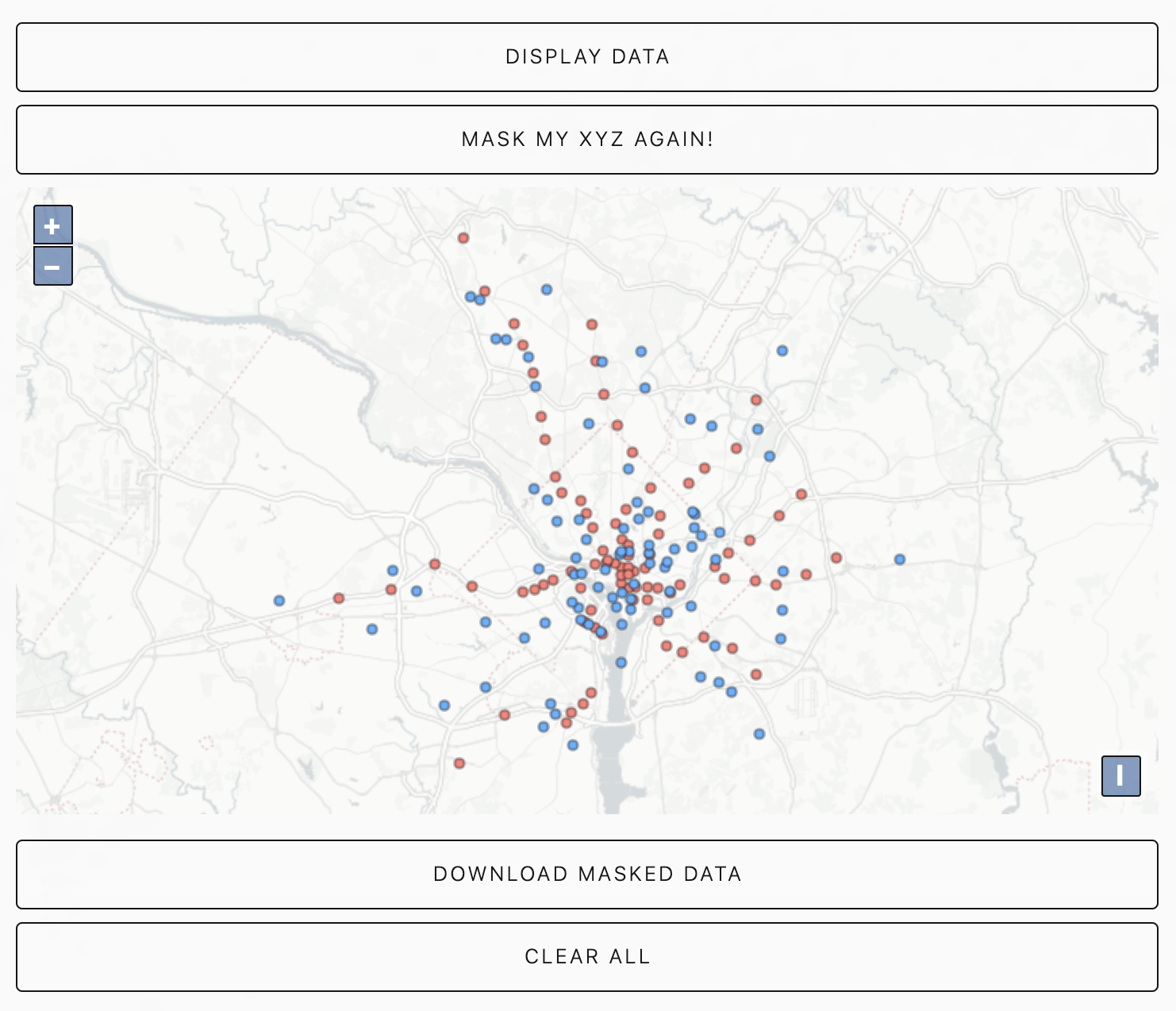
Data anonymization and Machine Learning
So far, we have introduced the big picture of anonymization, as well as some privacy preservation models. Now, we are ready to ask ourselves: how does data anonymization affect Machine Learning models? How does accuracy change with the use of anonymized training or test data?
"If we don't manage to figure out how to build Machine Learning systems that have good security properties and that protect the privacy of information, that would really limit the usefulness of Machine Learning for many applications that we care about"
Martín Abadi, Google's researcher, stated this at the Khipu's conference in 2019 while delivering an excellent overview of Privacy and Security in Machine Learning. This insightful talk revealed essential concepts that we will summarize here while emphasizing some of the problem's context as well as a few state-of-the-art approaches he mentioned in that overview.
In a supervised machine learning model, there are basically four targets of a privacy attack:
- The training data: it can be corrupted in malicious ways that lead the model to misbehave and to produce incorrect predictions. It's called a poisoning attack.
- The learned parameters: parameters can contain information about the training data, and they may allow some attackers to extract/infer information about the training set.
- The test data: manipulations, known as Adversarial examples, can be performed in order to confuse Machine Learning models.
- The model's test output: it can be useful for an attacker who is trying to reverse engineer the model.
As we're focusing our attention on preserving the privacy in personal data releases we'll make emphasis on poisoning attacks and adversarial examples.
Poisoning attacks
When we build a machine learning model, we need to keep in mind that we don't want our models to reveal information about the training set. That's why the first step when working with machine learning models is to apply some standard protection methods described above, such as anonymization, aggregation, and sanitization. Later, we know that models are supposed to generalize well on unseen examples, so we expect the models to not focus on the details of the training data. With this in mind, we may expect our model to provide some privacy guarantees by design (some techniques encourage models to not pay too much attention to training data, for example, deferring model optimization until the training loss is zero).
The fact is that generalization is an average case scenario, and we would like to cover more extreme cases. We want to ensure that someone who has our model won't be able to extract some of the training data or, an even more ambitious aim: that someone who has our model and an example won't be able to realize if the example was used to train the model. Here is where differential privacy comes into play. In general terms, differential privacy is a strong mathematical definition of privacy. It's based on adding noise to data in a way that there's no chance to know whether a specific individual was included in the dataset that generated the anonymized dataset.
Differential privacy for machine learning can be achieved using various approaches, such as the following:
- After training a model, try to somehow bind the model parameters' sensitivity to the examples and then, proportional to each sensitivity, add noise to those parameters. The challenge is how to quantify sensitivity.
- An alternative is to control sensitivity during training.
- Use PATE, which is a semi-supervised knowledge transfer method.
Some results of data utility and model accuracy after applying differential privacy are provided in the anonymous paper, Making the Shoe Fit: Architectures, Initializations, and Tuning for Learning with Privacy. The research shows that a machine learning model's accuracy drops slightly when training with privacy, but not too much (at least for the datasets used in the research).

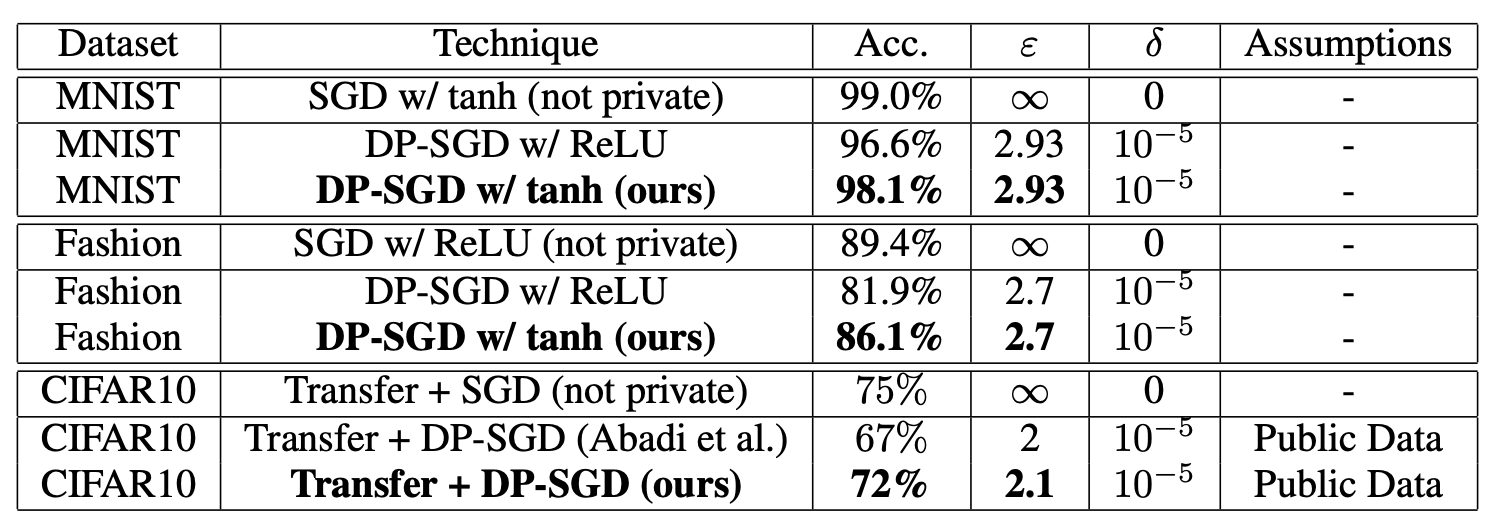
Adversarial examples
Back in 2014, a research group discovered that several machine learning models were vulnerable to adversarial examples, this means that models misclassify examples that are only slightly different from correctly classified ones drawn from the data distribution. Some of the researchers kept working to understand how adversarial examples influence the output of machine learning models, and they discovered that applying some specific perturbation to an image could change the prediction of a test instance completely, as demonstrated by the paper's example.


By using adversarial examples, an attacker may be able to fool a user detection model, putting at risk the privacy of the users of the system.
Other adversarial examples, apart from noise, are rotation and photographer.

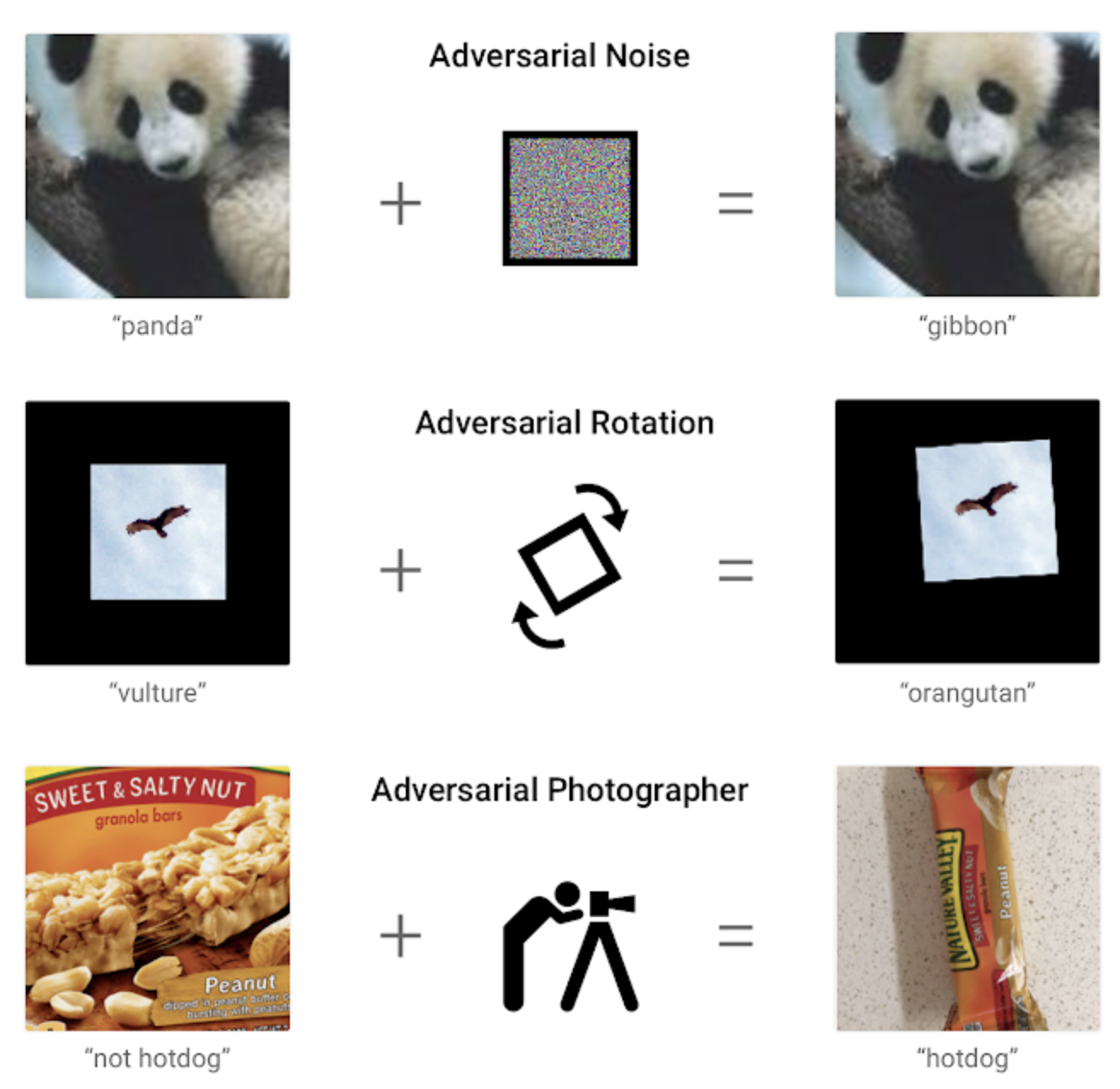
The perturbation of adversarial examples refers to small perturbations (the perturbed image and the normal one look almost alike). This allowed for the development of a lot of methods that protect against the Adversarial examples type of attack by creating more robust models. One such method is to extend the normal training procedure with examples of perturbations of normal examples.
The limitation of this approach is that it only deals with very small perturbations.
What’s in store for the future?
Throughout this post, we had covered the most essential aspects of the anonymization problem. We started this post by describing the most common formats used for personally identifiable information releases and provided an overview of the anonymization process. Then, we walked you through some privacy protection techniques, and last but not least, we summarized Abadi's talk about how data anonymization affects Machine Learning models.
The research in this field is far from complete. Of course, there are some issues that remain, but there is a promising future in addressing privacy concerns around machine learning models, making them more robust and adding more security enhancements along the way. This would enable the use of machine learning in contexts where these are necessary conditions to be met.
Semi-supervised techniques seem to be a possible path for further research, so stay tuned!
If you came up this far, you might be interested in getting some more insights. Talk with our engineering team about any related projects or ideas.
Related work
- Sweeney, L.. (2002). k-Anonymity: A Model for Protecting Privacy. IEEE Security and Privacy.
- Xu, Yang & Ma, Tinghuai & Tang, Meili & Tian, Wei. (2014). A Survey of Privacy Preserving Data Publishing using Generalization and Suppression. Applied Mathematics & Information Sciences.
- Fung, Benjamin & Wang, ke & Yu, Philip. (2005). Top-Down Specialization for Information and Privacy Preservation. IEEE Computer Society.
- Wang, Ke & Yu, Philip & Chakraborty, S.. (2004). Bottom-up generalization: A data mining solution to privacy protection.
- Zhu, Tianqing & Li, Gang & Zhou, Wanlei & Yu, Philip. (2017). Differentially Private Data Publishing and Analysis: A Survey. IEEE Transactions on Knowledge and Data Engineering.
- Mivule, Kato. (2013). Utilizing Noise Addition for Data Privacy, an Overview.
Wondering how AI can help you?

© 2025. All rights reserved.