

Face mask detection in street camera video streams using AI: behind the curtain





In the new world of coronavirus, multidisciplinary efforts have been organized to slow the spread of the pandemic. The AI community has also been a part of these endeavors. In particular, developments for monitoring social distancing or identifying face masks have made-the-headlines.
But all this hype and anxiety to show off results as fast as possible, added up to the usual AI overpromising factor (see AI winter), may be signaling the wrong idea that solving some of these use cases is almost trivial due to the mighty powers of AI.
In an effort to paint a more complete picture, we decided to show the creative process behind a solution for a seemingly simple use case in computer vision:
- Detect people that pass through a security-like camera.
- Identify face mask usage.
- Collect reliable statistics (% people wearing masks).
Without further ado, let's see some results so you can grasp an idea about what we're trying to solve here. These are compilations of many results from different cameras in short fragments, but there's also a complete 20 minutes video example at the end of this blog post.
Note: the numbers above people are "votes" from a mask classifier: they should be green (positive) when the person has a mask, red (negative) if not, and 0 if undecided.
We've open sourced the tracking library! 🎉
As promised, we've got some great news! The tracking code we used for this software has been released as a standalone Python library, that you could use to track points in a scene with any pose estimation, segmentation or object detection model.
Update: New version with better visualizations
Compilation of results with the new version of the system, after some work on the graphic interface and other minor changes
Below we're keeping the videos from the first version. The classifier performance didn't change drastically so they're still relevant.
This post is organized as follows:
- First, we will speak about our inspiration and unique challenge, as compared to other solutions.
- Then, we will show what it takes to reliably detect and count people in a camera feed. Expect some really fun stuff like pose estimation and Kalman filters.
- After, we will deep dive into how to identify whether each person is wearing a mask or not.
- We add up on this by showing how the fact that we are using video and not independent frames can help with a better decision.
- Lastly, we show actual results on a longer video, and brainstorm on next steps and possible improvements.
Along the way, you will have an understanding of the trade-offs faced to end up with a fairly reliable system. If you are a curious mind, keep reading!
Inspiration
Some time ago, we got inspired by a post from Adrian Rosebrock (PyImageSearch), who once again produced a great tutorial on how to build a real time face mask detector using Computer Vision, running on a webcam. Let's just steal his video snippet to show it working:
In a nutshell, his system works by performing two main tasks:
- Object detection with a neural network (SSD), pre-trained for face detection.
- Output: list of bounding boxes around each detected face.
- Classification in two classes (with/without mask), using another neural net (MobileNetV2).
- Output: score from 0 to 1 signifying the probability of a face wearing a mask.
The pre-trained face detection model seems to work great for his case, and it detects faces even when they are partially covered by masks. So, no need to re-train anything for the first model (object detector, SSD).
As there was no pre-trained classifier to distinguish faces with and without masks, Adrian trained this model with a dataset provided by one of his readers (to download it, refer to the post). This reader-of-your-dreams collaborator created this dataset with nearly ~1400 images in a very clever and effective way: he took a dataset with regular faces, and artificially added masks to some of the images. He leveraged other computer vision techniques to automatically place the masks over the faces.
Some of the images in the dataset are shown below:


Even though this is a synthetic dataset and it's built with a single mask type, it seems to generalize pretty good for other kind of masks (note that in the example video, Adrian's mask is quite different). It does a great job for this use case, where the user —or users, since it supports multiple faces— is placed in front of the camera.
A new challenge
Although the problem statement is similar (detecting face mask usage), the reality of images obtained from real-world sources like CCTV or surveillance cameras can be much harsher. We focused on this particular camera during most of the development, but we also tested it with other sources, like the streams shown at the beginning of the post.
Can you imagine the main issues that we'll be facing? To enumerate some:
- Size of the images. Faces are drastically smaller, and much less clear.
- Varying angles. People are rarely looking straight to the camera — they look in every other possible angle.
- Lack of clarity. Often, it's very difficult — or not possible at all — to tell if the person is wearing a mask or not from a single still frame.
Here are some concrete examples of what our solution is expected to handle:


Also, keep in mind that we want to reliably count the fraction of people that are actually wearing masks out of all those that pass by our camera setup.
All of these points have a big impact on the choices made throughout this project, and are the reason why many solutions that have appeared on the internet these past few weeks really won't work in real scenarios like this.
Our approach: follow trajectories
To compensate for the lack of clarity of the images in still frames, we can think of actually using several different frames of the video to make a better mask/no mask decision.
For example, see this example where we follow 4 faces — each corresponding to the same person — throughout a few frames of the video.
Leveraging the fact that some entities across multiple frames are actually the same is not trivial, though. To an outsider, it may sound very simple or even taken for granted, because it's almost unconscious for us humans to follow each person through the video. However, for a machine to do the same, we require an additional technique called tracking.
Using tracking, we can group which faces correspond to the same person across multiple frames. This lets us run a classifier for each individual image, and then combine the results into one single decision: mask/no mask.
This technique will also allow us to count people and collect more valuable statistics, which was our second goal.
We could think of other alternatives to estimate the fraction of people wearing masks, like sampling random frames during the video, classifying all found faces and then averaging the results over many frames. But this approach wouldn't really allow us to count people passing by, and would be a very inefficient use of the data, since we could only use a tiny fraction of the frames. Otherwise, we would likely count the same people many times (did you see the street benches in our sample video?).
The best approach in order to make efficient use of the data and have reliable statistics is to do tracking: follow each moving head to have the best shots for each person, and count the classification results considering the whole video sequence.
Detecting people and faces
Following people across frames: tracking
To have a better idea of how the components will fit, let's briefly describe how tracking works:
- The tracking algorithm lives during the whole video sequence, and is updated step by step, with each new frame that is processed.
- At each step, it receives a list of points, and tries to match each point with previously detected points. For that, it can estimate the new position that each point should have, according to its estimated speed (e.g: using a Kalman Filter, details later).
- When it detects that certain points (e.g: corresponding to a person's eyes) seem to have "survived" for a couple steps, you can use it to say: this is a single person and it's moving from here to there.
Note that the tracker we will use doesn't care about what's actually on the image. It only receives a list of point coordinates at each step, and predicts their future positions. There are no computer vision tasks here; those are only performed in other components.
Robustly finding people in frames
With the brief explanation above, it's clear that this tracking algorithm only works if we can consistently detect positions during the entire sequence. In other words, if some points are not detected for many frames and then they show up in another place, this tracker won't be able to match them as belonging to the same person.
So there's an unavoidable problem with tracking just faces: what if the person looks in another direction and the face is not visible for many frames?
We could attempt to detect heads in any position instead of just faces, to then classify them in mask/no mask/back side. After discussing these ideas with our R&D team, who had been working on some tracking solutions for different video analytics applications — from estimating people flow for the retail industry, to vehicle tracking in traffic — the recommendation was to first try with pose estimation. Apart from being a well studied problem, there are several pre-trained working implementations and datasets.
There are some trade-offs, though. In general, these models tend to be slower than object detectors. But we think there are many reasons that justify using it anyway. Using the person's key points, we can consistently track them across frames, despite changes in orientation and position.
Let's see how pose estimation looks like in our camera.
Astonishing! Did you notice the mannequins in the shop window!?
These results were obtained using AlphaPose, but similar results are obtained with OpenPose (which we ended up using). The latter misses some detections on very small bodies, but those are not important in our case because faces are indistinguishable anyway.
These models also provide a detection score for each detected body keypoint, which we can use to decide if the person's face is visible.
But wait... if we'll be using only the head keypoints, how is this different from an object detector for "human heads", after all? The answer is that pose estimation algorithms use all body parts predictions as a whole, and keypoint predictions are integrated. They leverage much more context information about other body parts present in the image and their spatial distribution (i.e: the nose should be closer from the neck than a leg, for example).
Detecting heads from poses: choosing an heuristic
At this point, using pose estimation we get keypoints for many body parts, including the head. There are many ways to obtain a bounding box for the head using these point coordinates.
We tried some simple heuristics to do it. Basically, we need to convert the pose information into a box, which can be defined with two parameters:
- Box size:
- Using head keypoints: based on the distance between eyes, ears and nose.
- Using chest keypoints: based on hip-to-neck distance, seems more stable for people looking in different directions.
- Box position:
- Using head keypoints: the reference is a point in the center of the head detected points.
- Using chest keypoints: just use the neck position as reference.
Using head keypoints seems more intuitive and simple, but let's see how these two different approaches look in practice before making a decision.
A couple things to take note from this simple example:
- Yellow boxes disappear more often than green boxes; it happens when there's a single keypoint in the head: there's no reference distance between two points to estimate the head size.
- Hip-to-neck distance is more stable in this case (green boxes), but it requires the person to be entirely visible, even if we only want to draw a box over their head.
- There are some weird glitchy pose detections at some frames, in the tree. These can be filtered out using a threshold for the detection scores.
In this case, where we don't have a stable detection for all head keypoints, we decided to use chest keypoints instead, and it seems like the best approach for street cameras in general.
Detecting face masks
Still a classification problem
At this point, after all the pose estimation analysis, you might think that our approach diverged completely from the blog post that inspired it. But so far we only changed the object detection module: instead of using an SSD neural network to detect heads, we're using pose estimation and extracting heads from there.
After obtaining the bounding boxes for the heads, the approach is pretty much the same: we need to do mask/no mask classification on the head images.
Building a mask/no mask dataset
Even though we still have the same high level components, the nature of the images is completely different and the artificially generated dataset would not work. As we said before, faces are almost never frontal to the camera, images are much lower size and quality, faces are very blurry and masks too, and they can come in many possible textures and colors.
Leveraging the face detector
We had video streams and a script that detects faces on them. It was straightforward to extract these faces automatically and save them as individual images. Then we just needed to manually put them in two folders: with_mask, without_mask. Oh, there was a third folder: unknown, it was huge but had a short life.
Let's see some example faces from our dataset.
Spoiler alert: struggle with beards
If you're thinking about implementing a face mask classifier, you're warned: have special care with beards. In the first versions of our dataset, we didn't have enough examples of bearded people and our model was completely puzzled classifying them always as "mask" with high accuracy.


We had to specifically add examples of these tricky cases to the dataset. Then, we improved the script to leverage tracking and only save a couple faces per person. We built our dataset incrementally as we improved the face detection heuristic, so we reached almost 2000 faces in the final version without a very significant effort.
First attempt: reuse existing classifier
As a first approach we re-trained the same classifier from PyImageSearch's blog post, but providing it the new dataset images, as shown above.
This classifier is implemented in Keras, and it's based on a MobileNetV2, a neural net architecture developed by Google. It is very optimized in size and computational cost, suitable for on-device (i.e: constrained environments) object detection tasks, like a mobile phone or precisely a real time webcam stream. In his blog post, Adrian adds a custom Fully-Connected (FC) head layer to obtain a binary classification output.
We did a few iterations modifying the custom head, because at first the model was heavily overfitting to our small dataset (at that time we had about 200 images in each class).
Reducing the size of the FC layer helped with reducing overfitting and the validation accuracy improved a bit, but it was still not working well. The classifier's performance on our dataset is shown in the plot below.

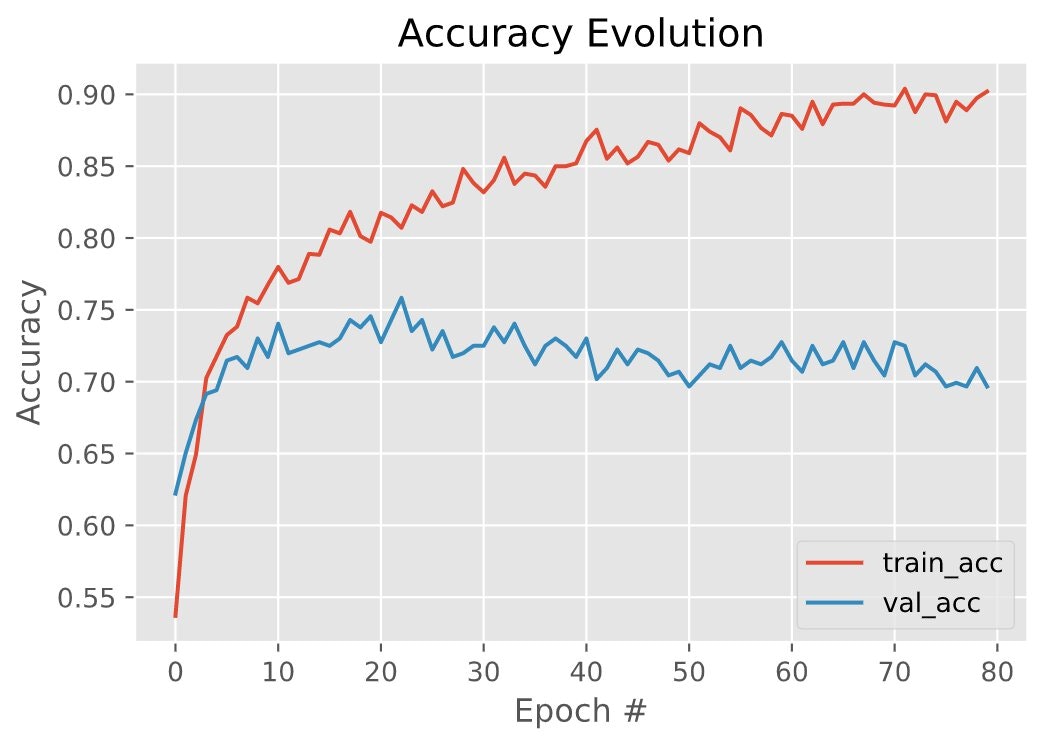
As you can see, even though the training accuracy kept increasing, the validation accuracy did not improve and actually went down: the model was still overfitting. Moreover, we got a validation accuracy below 75%, which is far from great for a binary classifier (where the accuracy floor is 50% if classes are balanced and we choose randomly).
We also tried some data augmentation, like random rotations, color adjustments and translations, but we had to keep it very limited because otherwise the model would not learn anything at all.
Finding the right classifier
Evaluating these results, the priority for the next iteration was clear: try other classifiers to improve accuracy.
What classifiers should we try next? Well, our task here is to classify low resolution images. What dataset has similar characteristics? Answer: CIFAR. Ok, we went straight to the current state of the art (SOTA) models for image classification on CIFAR. This list changes all the time and depends on the exact dataset (e.g: it's different for CIFAR-10 and CIFAR-100), but there's a technique that is consistently good for classification, also developed by Google: Big Transfer (BiT).
In particular, we could use the BiT-M model for which there are released weights, pre-trained in the dataset ImageNet-21k which contains 14 million images from ~21k different classes.
How it works: Transfer what?
Actually, the whole idea of these BiT models is to leverage Transfer Learning: starting with a well-known neural network (ResNet), they pre-train it in a really large image dataset and then they describe the recipe to effectively use these weights and fine tune the models for other specific tasks.
To understand this idea, note that the first convolutional layers which extract general features from images (e.g: detect contrast and color changes, lines and other shapes, etc.) remain almost unchanged despite the specific task (e.g: object detection, classification, etc.), and the parameters of the last layers are the ones that need to change to produce the desired output. The contribution of this work is to develop effective ways to transfer the learned parameters, providing a simple way to fine-tune the pre-trained model and reuse it in other specific tasks.
So, we're training this classifier with our comparatively small dataset, but the millions of parameters of the neural network were mostly learned using a huge dataset and then efficiently adjusted to our classification task. That's how learning gets transferred. Let's see if it works in practice in our dataset.

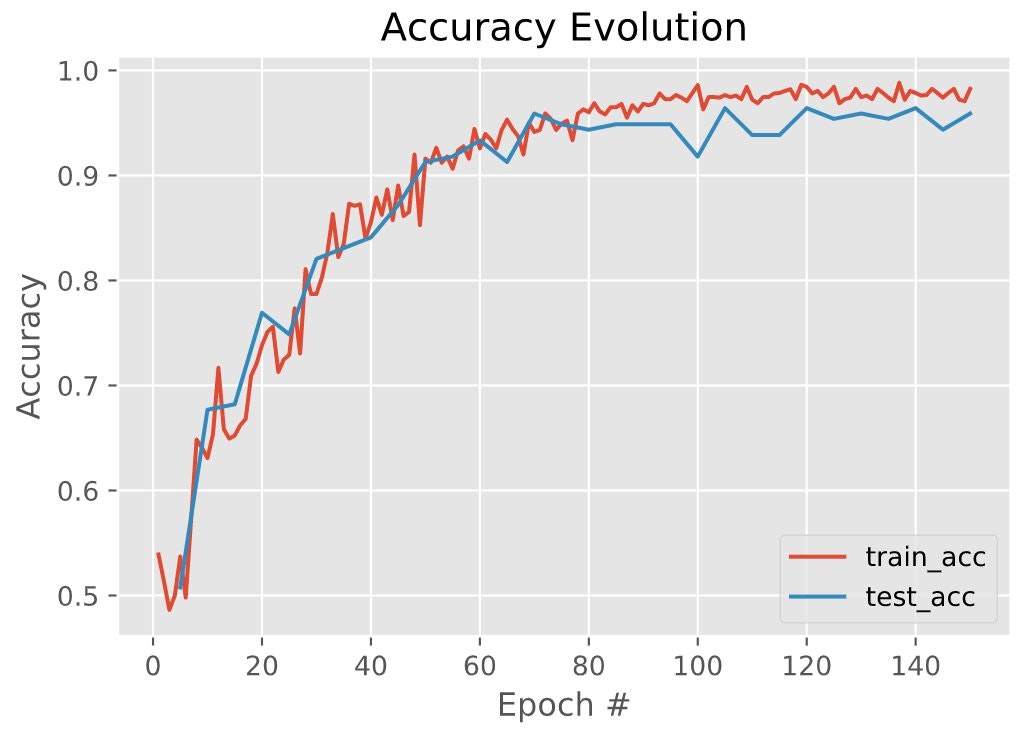
The final test accuracy for this model is ~96% which is really good! The overfitting of the previous model went away.
Wondering why the training accuracy is not reaching 100% with this not-so-big dataset? Well, we're using random data augmentation quite aggressively in the training and the test set, because our ultimate goal is to classify moving faces in videos, which may be worse in general than the images we've chosen for the dataset. Our final goal isn't exactly reaching the best performance on our dataset, but in actual raw faces from videos.
So, in order to make it more robust to blurry and less clear images, we're applying this augmentation that consists of random rotations, translations, and color jittering. This is how it looks:


The training process goes over the entire dataset many times, and each image is preprocessed slightly different each time. It's like training with a much bigger dataset. That explains why the classifier never fits the training set perfectly: samples are not exactly the same in each epoch.
But the good part is that it generalizes much better to other unseen images. That explains the boost in the test accuracy.
End-to-end over videos
Now, we have built the two most important components we need:
- Face detector based on pose estimation.
- Classifier to identify whether or not crops of faces have masks.
Do we really need tracking?
At a first glance, it's not an obvious requirement, but using tracking is actually a game changer. Let's recap why:
- The classifier can be run several times on the same face, and we can take the highest scores to make a decision about each person; i.e: watch the entire video sequence like we would do as humans, instead of individual isolated frames.
- We can have statistics based on the actual number of people that pass by, independently of the time that they appear on the screen. As opposed to taking periodic screenshots and then taking some average.
- Faster processing, since we can avoid computing the pose estimations in every frame, by interpolating intermediate positions.
- Higher robustness to bad detections that could appear at some frames.
- Smoother face boxes 🙂
The last two points can be appreciated in the following video, but actually the first two are the most relevant features for our use case, since we want to have trustworthy statistics.
As you can appreciate, green boxes are smoother and we're also showing the tracking number of each person. Did you spot any bad detections? Look for a small canine creature 🐶, in the left video (red boxes).
Remember how the tracking algorithm works: it keeps track of each point coordinates provided with each new frame step, and tries to match them throughout the sequence.
We're specifically using a Kalman filter with a first order dynamic model (only using estimated speed, not acceleration) to estimate the next position where each point should be, and then matching these predictions with the actual points found. This way we can tell when a pose corresponds to the same person that another pose detected in the previous frames.
We won't get into further details about how tracking works, but leave us a message or stay tuned, because we will be releasing more content on that specific topic, if it's interesting for our audience of course. 😉
Using information from multiple frames
Distinguish faces from heads
One more thing to notice from the last video above, is that we're detecting heads rather than faces. That's good for tracking, but we only want to classify faces when they are visible.
A very simple rule we use is to classify only when there are at least three facial keypoints (to pick between both ears, both eyes and nose) above some threshold. That's how we avoid running the classifier for heads without visible face.
In the following video, we're using this strategy. Above each head we show the latest output probabilities of the classifier:
- Near 100 means a mask was detected.
- Tends to 0 if no mask is detected.
- Around 50 if undecided
Note that the classifier doesn't update the scores when faces aren't visible. The initial default score value is 50.
Picking the best results
As you can see in the previous video, the raw scores from the classifier can vary a lot from frame to frame. We need some strategy to combine all the outputs and make one single decision for every tracked person, but efficiently using all the available data.
For example, if the same person's face was classified as mask in 5 frames, and no mask in 15 frames, what should we do? And it's actually more complex, because each classification has a score: maybe we have 5 frames classified as mask with a score above 90, and 15 frames no mask but with a doubtful score of 40. Should we use all labels equally or try to weight them somehow using the score?
We tested several methods (e.g. a moving average filter for the score, and many derivatives of that, equivalent to weighting labels using the score), and the best results we got were simply using a thresholding + voting approach:
- Thresholding: only consider classifier outputs with score under 20 (no mask) or above 80 (mask). Discard the others.
- For each person, count the number of "votes" for mask (positive, green) minus no mask (negative, red) as they walk their path.
- After at least 3 votes, decide if it's a mask person based on the votes balance.
- Limit votes to 100 for faster reaction if the person puts on or removes the mask during the sequence.
Avoid side faces
Despite being useful, the classifier scores aren't entirely reliable. Watch the resting guy 2: he doesn't even turn his head completely and even so the classifier starts working.
To filter out these edge cases, we ended up asking for both eyes to be visible, which has the disadvantage that side faces are plainly discarded, even if in some cases the mask is distinguishable. We actually left this as a configurable option, but it seems to work better enabled. Remember that we still have the whole sequence for each person, so we can be picky here.
Detection area
Now you'll notice that some of these faces are actually hard to distinguish in some parts of the image. If you follow the lady tracked as 6 in the video above, the classifier gets worse as she walks under the camera; but what's actually happening is that it's not easy to spot her mask from that angle!
That problem can be easily solved by configuring margins to enclose a detection area, and leave out bits of the image where faces are quite distorted and the classification will be error prone.
Putting it all together: final refinements
Considering all the comments from the previous section, we ended up adding the following restrictions and features to improve the reliability of the solution:
- Margins: configurable margins for each side of the camera, to avoid performing classification outside of them. They are displayed as darker zones in the videos.
- Frontal faces: a configurable parameter (enabled by default) to classify only faces where both eyes can be identified.
- Thresholding + voting: only counting classification predictions with a score below 20% as negative (red, no mask) or above 80% as +1 (green, mask detected), and then adding up these votes during the person's trajectory. Limit votes to 100 to allow faster reaction if the person puts on or removes the mask.
Let's see how all these things look like when implemented in the same sequence as above.
Not bad! Ok, we're clearly missing a couple predictions now, like the side looking girl 1 or the resting guy 2. But the ones we are classifying, are now all correctly labeled. Of course there are trade-offs, and we could also do other things like augmenting the dataset with side faces and such, but for a first meaningful version of this system, it seems good enough.
We're only looking at this short fragment to illustrate the idea, but we actually tested it with other several different videos, and these restrictions improved the results for this camera.
Let's see another interesting example!
This is a real stress test for our system. There are many people moving around, and the video stream went black in the middle, but the tracker still works great!
Running on a long video
In order to have a reliable estimate of the amount of people wearing masks, we need to process at least a couple minutes of video at certain times of the day.
Including long videos is not the idea of this blog post, but below we're showing a 20 min video snippet accelerated at 8x so that you can check how it works and the final numbers we got.
As you can see, in our capital city approximately half of the people are wearing masks in this particular place. Doesn't seem like something to worry about for now: we don't have a high number of cases and it's an open street; but you can make your own judgments.
Closing remarks, next steps and possible improvements
Current implementation: final thoughts
The system works great, but it required some effort to overcome all these challenges!
Using pose estimation was definitely an interesting approach for this use case. As mentioned, it made sense by the fact that we have really small faces, hard to detect and even harder to track. We need tracking to classify people in the right moment, as they walk through the sequence of frames looking in different directions.
What's the requisite for a video stream to be correctly processed? Faces need to be visible at some point (we filter images below 16x16 pixels). And in this case we're using the body to estimate the head bounding box, but that's very easy to change for other cameras and use facial keypoints instead if they're visible, still using pose estimation.
If you have some particular video stream where you want to test this software, let us know! It's always great to have comments and feedback from readers.
What's next?
Work on this kind of real world video analytics is far from over. There are several lines of work to tackle next, which can both improve the current solution in terms of accuracy, and also make it faster:
- Trying other models for pose estimation. In this implementation, we used OpenPose because of the simplicity (and the fact that we had used it before). But this is an open area of research, and there are some new developments that apparently work lighting fast, even in CPU. We should experiment with several implementations to see how they fare.
- Improve the classifier. We have seen other people actually use 3 categories for classification: with mask/without mask/misplaced mask. We think this approach would make sense since our classifier has some trouble with these cases: the mask is detected but also the nose and mouth are visible, for example. We didn't add such cases to the dataset because we weren't sure it was a good idea to put them in some of our 2 folders, so this new approach would solve the issue neatly. We can also source more images from more video streams and build a better dataset.
- Ditch pose and try out robust head detection. Another interesting approach is to use some single shot object detection technique to identify any kind of head, in any possible angle, with labels like "front face, with mask", "front face, without mask", and "face not visible". We need to track heads instead of just faces, to have a continuous movement even if the person looks in the opposite direction than the camera. This overall approach might not be as robust than the current one, but would probably be simpler and faster, and it might be a good idea for devices with limited resources. For example, it would probably be easier to run on an embedded device such as Google Coral or Jetson Nano.
- Try out person re-identification. Re-identification techniques can make the system more robust to interruptions and occlusions, by extracting image features from each tracked person, to allow matching people even if the screen freezes and they re-appear elsewhere. Remember that the current approach requires people to move continuously. However, this technique adds a significant layer of complexity and computational burden.
As you can see, there is no silver-bullet here, and the techniques will vary according to the requirements of the solution and the constraints, like the environment in which it should run. Robust video analytics is far from solved, but incremental steps can be taken to improve any part of the solution.
We hope to continue working on this, and hope you had some fun while reading our post! Please stay tuned and don't hesitate to post your comments, questions or suggestions!
Featured in...

Wondering how AI
can help you?

Terms and Conditions | © 2026. All rights reserved.