

Modeling the consumer purchase decision


Discrete Choice Models for demand forecast
Imagine a person walking into a department store looking for men's pants. What are the chances they end up buying a specific pants model?
This question seems extremely difficult to answer. There is a great variety of products from which to choose. However, each person uses different criteria and can easily switch from brand to brand. A myriad of factors influences a customer’s decision to buy.
A somewhat accurate answer to this question enables companies to offer their clients the proper selection of products that maximize profit or customer satisfaction. Pursuing this goal is often called Assortment Optimization, known as one of the essential strategies for success.
In this blog post, we’ll present Discrete Choice Models. Companies use this strategy combined with the tremendous power of Machine Learning to optimize their assortment of products. They combine the knowledge of human behavioral sciences such as Psychology and Marketing with numerical sciences such as Statistical Analysis and Econometrics, and use the computing power of cutting-edge processors and Machine Learning libraries for model creation. The result? Models are efficiently built to increase companies' profits in the range of 2% up to 25%.
Choice models
Choice models are statistical models explaining the decision process of an agent—for example, the purchase process of a customer. It assumes that a decider agent first screens the alternatives, ranks them by the expected utility, and then makes the purchase decision.
A classic choice model is a well-known statistical tool called multinomial logistic regression.
Multinomial logistic regression is a powerful tool to model choice from a finite set of alternatives. Still, it comes with an underlying model assumption called the independence of irrelevant alternatives, or i.i.a for short. This states that any item added to the set of choices decreases all other items’ likelihood by an equal fraction. So, two pants of the same model and size, but with different colors, are treated as entirely different products.
A tool named nested logistic regression or nested logit for short, is used to resolve these inconsistencies. It is an extension of multinomial logistic regression, where all the alternatives are arranged in a tree-like structure. The nests are groups of similar alternatives, with each alternative belonging to only one nest.

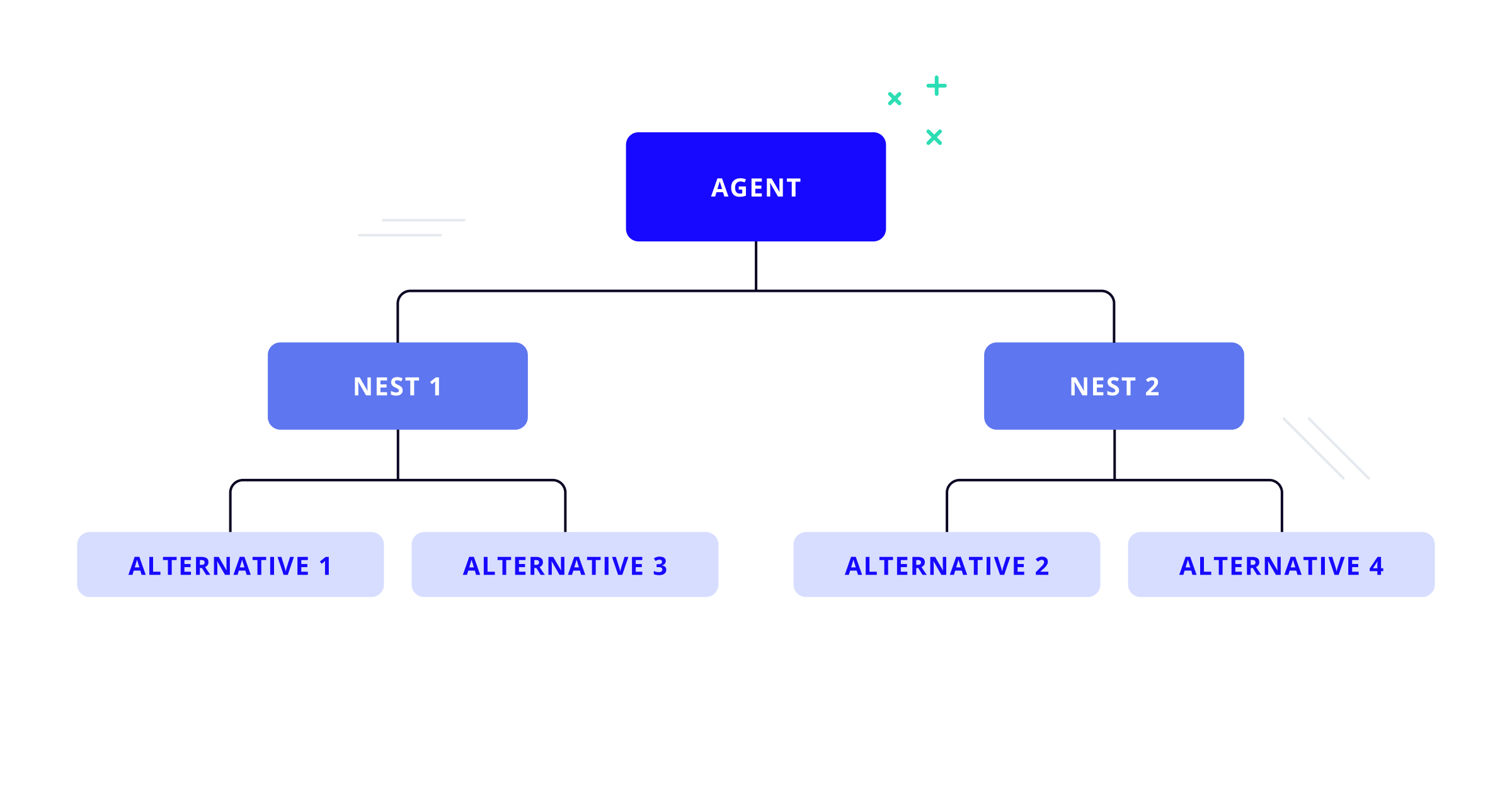
Back to the department store example, the store's products can be arranged in three big nests: men’s clothing, women’s clothing, and children's clothing. These nests can be further categorized by sub-nests: jeans, shirts, blouses, dresses, pajamas, sweaters, and accessories. The store can continue structuring the products in a tree, obtaining an arrangement similar to the following graph.

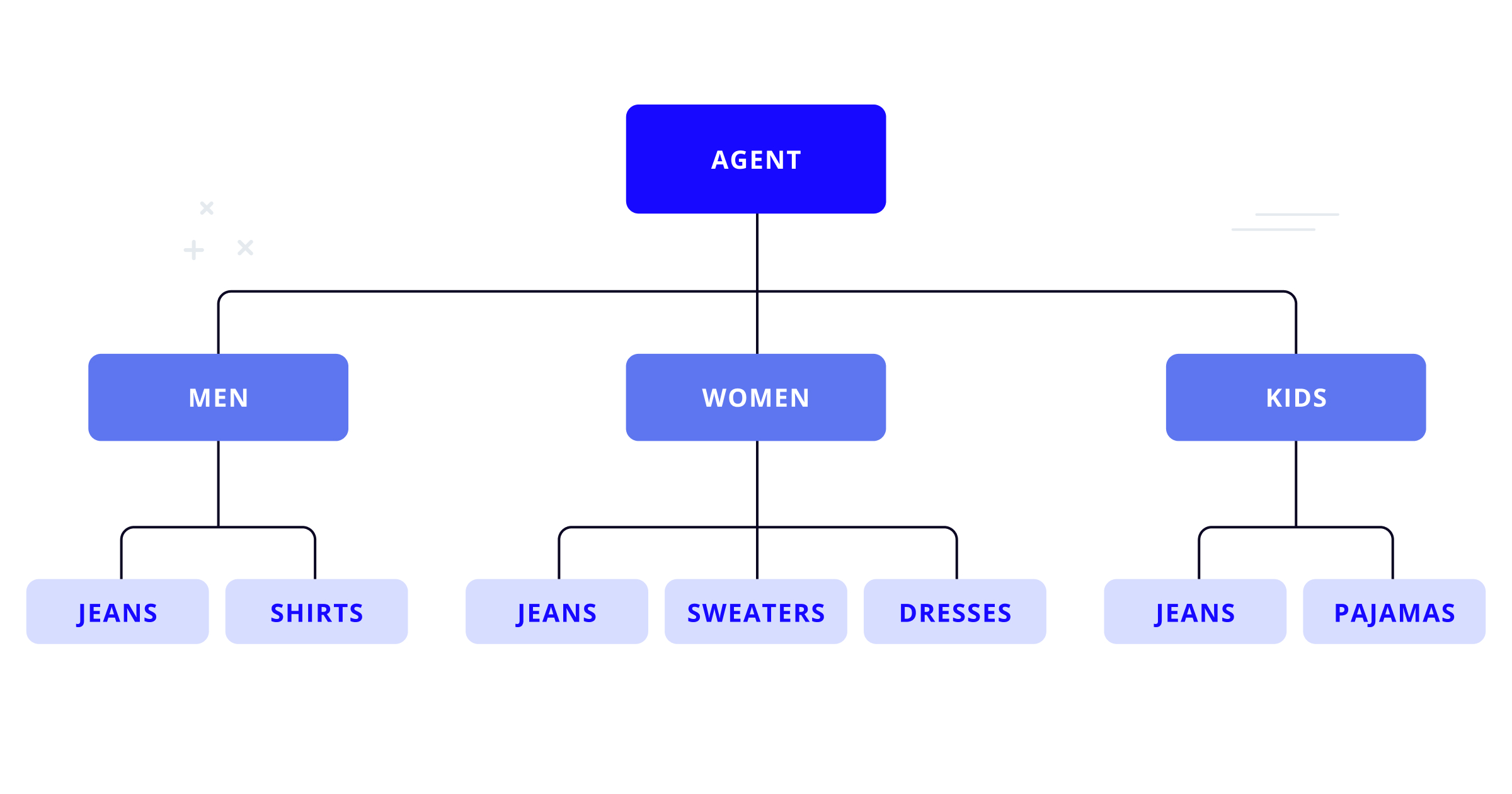
Nested logit models are used to compute the probability for a customer to choose product X in a tree-shaped arrangement.
You will find in the literature other choice models such as mixed nested logit, cross-nested logit, and different variants. All these models make up the discrete choice models.
Imagine a world where product labels show the price and the propensity to be purchased. In a nutshell, that is what discrete choice models do. These models can classify all the products offered in a store by the probability of being purchased.
One of its most significant contributors is Dr. Daniel MacFadden, who received the Nobel Prize in Economic Sciences in 2000 for his advances in the theory of Discrete Choice Models.
A glimpse of the math behind the discrete choice models
The discrete choice models belong to the more general Random Utility Models. Based on the historical sales data, client characteristics, and product features, the client is assigned a vector of the utilities that the products provide, where ranges in the total number of products.
These utilities are modeled having a deterministic part and a random part .
is the utility of the alternative perceived by the agent .
The agent will choose the alternative if and only if .
The random parts are treated as random variables. They are modeled with an Extreme Value distribution where is a localization parameter, and is a scale parameter.
In this setting, the Gumble Theorem can be applied to compute the density probability function.
One of the most surprising facts is the well-known and straightforward outcome after solving a complicated multidimensional integral involving the density function seen above.
The probability that the customer purchases the product is:
It is a softmax, and it does not depend on the random part—two great news!
So, the Nested Logit models apply softmax at each tree level where all alternatives are structured, considering only the deterministic parts—the known product and customer characteristics.
Certain luxuries are provided to only those companies investing in Machine Learning:
- knowing which products have the highest propensity for being purchased
- differentiating the products that generate the most significant profit
- being able to have this knowledge about thousands of stores

Custom-built models
One of the advantages of custom-built Discrete Choice models is the interpretability, the opportunity to know what happens under the hood. This enables the possibility of making code improvements, which is advantageous over models that function as a black box.
Choice models in a bundle: collaborative filtering
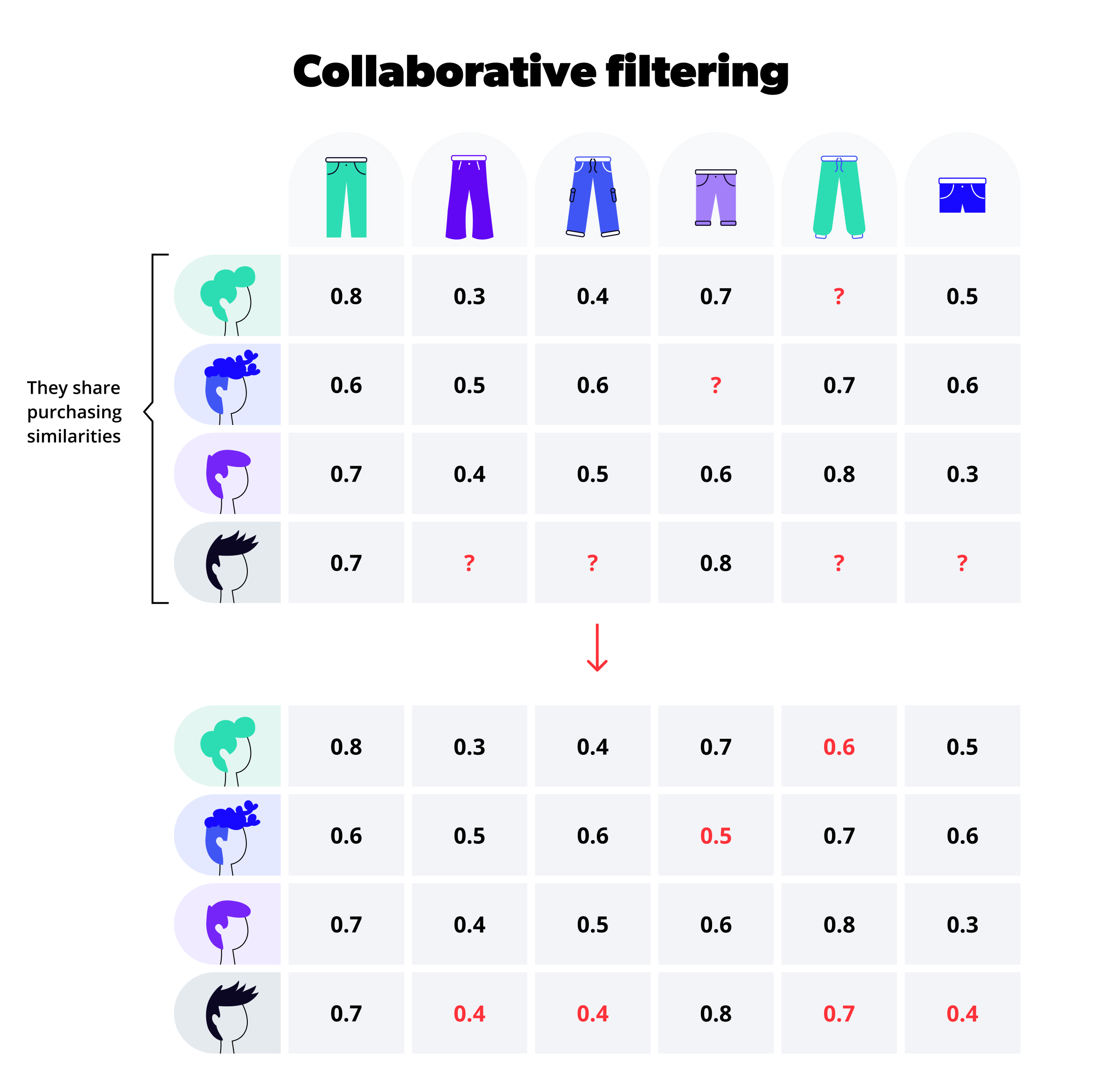
It is not always possible to find all the utility products provided to each customer, ending up with sparse matrices as the model outcome—matrices with many entries without information. Methods of Collaborative Filter can be applied to obtain even more information from the data, where the algorithm SoftImpute plays an important role. SoftImpute is a mechanism to infer missing propensities from the inclinations of similar clients. The idea behind it is that customers with multiple similar characteristics might have similar interests in products.
Pricing strategies with significant uplifts
To further improve the choice model strategy, it can be combined with pricing techniques. By doing so, we can characterize the structure of the optimal prices.
Pricing is a widely used marketing strategy to attract consumers and win market competition. In pricing problems, AI learns to determine prices for all the products to maximize the aggregate expected revenue or profit. We have vast experience with Auto Pricing and Pricing Optimization, you can check more about these solutions on this article.
At Tryolabs, we have enhanced our client's tech toolboxes with AI models based on Discrete Choice Models, Collaborative filtering, optimization, and pricing techniques for assortment optimization.
For instance, we have successfully delivered a model for a large B2B company in the CPG (Consumer Packaged Goods) sector. This giant company operates in virtually all the countries around the globe. We built a Machine Learning model with monthly product recommendations to each of its clients, crossing over optimal propensities and profits.
As a result, in one of their operating countries, our client computed a nearly 10 million dollar profit increase in the first six months, representing a 2% uplift of total profits. These numbers will keep increasing in the future.
As it is easy to infer, the ideas described here can be applied to any business where the clients are faced with substitutable products. Many sectors of the economy are also profiting by applying the bundle choice models + collaborative filtering + optimizers + pricing, and retailing being one of the hot ones.
If you're interested in exploring solutions based on Discrete Choice Models, contact us to chat and see how we can build a solution that fits your business.

Wondering how AI
can help you?

Terms and Conditions | © 2026. All rights reserved.