

Assembling your Data Science tool belt: a road to Machine Learning




Welcome to the first blog post of a 4-part series where we will shed some light on data science, what we do at Tryolabs, and how to approach your journey in case you wish to start your career in Machine Learning. This series is not the typical highly technical or business-oriented blog post. Instead, it is aimed at students, enthusiasts, and curious people who want to dive into this topic to specialize further or do a career shift, or just for the sake of acquiring new skills. Also, we hope it will help our families to finally understand what we do all day long sitting in front of the computer looking at code and graphics :)
In this first blog post, we will overview the basic concepts and tools that we understand a good data scientist should have in their tool belt. The second one will focus on basic machine learning concepts such as data processing, models, metrics, and others. The third one is where we review how deep learning revolutionized the field. And lastly, a fourth episode where we’ll talk about our culture and values.
Be warned, we are not reinventing the wheel with these blog posts, instead, we will stand on the shoulders of giants and point to many of the great resources out there, from essential YouTube channels, great online courses, to brilliant blog posts. We are big fans of learning by doing, so you’ll find a lot of this. Hope you enjoy your journey!
The road to Machine Learning
Say you wanted to become an astronaut (who didn’t at some point?). You could watch rocket launches all day and think that an astronaut's job is only about that epic, climactic moment. In reality, though, flying a rocket involves training in a wide set of skills.
With Data Science and Machine Learning, something similar occurs. You could read new and exciting applications for artificial intelligence every day, and learn about new, bleeding edge models. But, what are the necessary skills to actually become a professional in the field?
In 2010, Drew Conway proposed a simple framework for understanding the skills needed to excel as a data scientist.
His idea was first that Data Science was broader than Machine Learning. While Machine Learning involves the definition and fitting of models that can learn from data, Data Science would involve all activities necessary to actually gain insight and solve a problem with our modeling.

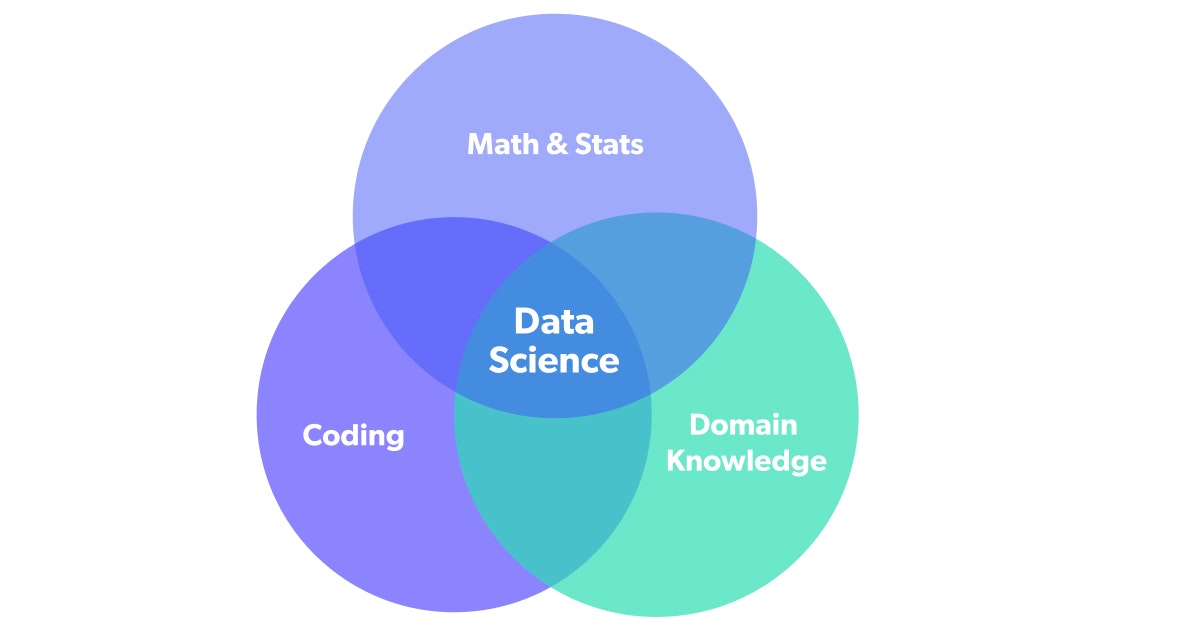
According to this framework, a solid Data Science Foundation requires knowledge in three areas: Statistics, Coding, and Domain i.e. knowledge of the specific problem at hand. Though there are other skills that could be included, we believe this is a great place to start. Let's get into it.
Fundamentals: Coding
Computer Science concepts
If we’re talking fundamentals, before we get into coding per se, there are some general computer science concepts with which you should get acquainted. Computer science is an endlessly vast field, but for Data Science purposes, you should at least manage the basics of data structures and algorithms.
Why focus on these two? Apart from the fact that these are arguably the most important topics in Computer Science, data doesn't live in the ether. It lives within data structures such as lists, hash maps, matrixes, and so on. And if you want to play with it, you will need algorithms to manipulate said structures effectively.
We have two resources to help you to dip your toes in the matter, but plenty of other resources on this topic are available.

Playlists
CsDojo has a great playlist on data structures and algorithms fundamentals.
If you want to go deeper into these topics, MIT has a 24-lecture open course on YouTube.
Retrieving Data, SQL, and NoSQL
As you probably already know, data is the bread and butter of the discipline. Data comes in many forms, such as images, videos, documents of various formats, web data, etc.
Processing large amounts of data from different sources and making it available logically and efficiently is a complex problem on its own, from which a whole other discipline has emerged the Data Engineer.
But not every project has these kinds of roles. You may be a solo data scientist, the project may be in its early stages and lacks a fully developed team, or the person in charge may be on vacation. This means that you, as a Data Scientist, will find yourself using one of the most important tools in our field: databases. Databases come in two flavors: relational and non-relational. There’s an awful lot of theory regarding relational databases and the underlying relational model of data. However, very coarsely speaking, you can think of a relational database as a collection of tables related by id columns.
Several database management systems (DBMS) have been created over the decades to create, organize, and interact with relational databases. Some popular DBMS include PostgreSQL, MySQL, Oracle, and SQLite. In all of these systems, data is added, changed, or retrieved using the standardized programming language called SQL.
Here are some great resources where you can start about this topic:
SQL courses
Khan Academy offers a very good beginner SQL course that covers the basics and a bit more.
DataCamp has a five-part SQL skill track that focuses only on retrieving data and is fairly comprehensive in this regard.
Exercises and challenges
- Finally, if you feel like you’re getting the hang of SQL and want to test or expand your skills, you can try some of HackerRank or pgexercise’s challenges.
The second flavor is the NoSQL databases. Although we wouldn't include these in the basic path, we mention them for the sake of completeness on the topic. NoSQL databases are non-tabular databases that store data differently than relational tables. NoSQL databases come in various types based on their data model. The main types are document, key-value, wide-column, and graph. They provide flexible schemas and scale easily with large amounts of data and high user loads.
Depending on the particular needs of your NoSQL database, you can choose from several implementations. The ones we have used most at Tryolabs are:
NoSQL providers
- MongoDB: a disk-based document store.
- Redis: very fast and implements many data types (hashes, lists, sets, sorted sets, etc.). Usually very good for cache, but also has the persistence to disk.
- DynamoDB: very scalable, completely hosted in the AWS Cloud (no infrastructure maintenance needed).
- Free Course Camp offers a course on NoSQL databases if you feel inclined to delve deeper into this topic
Python
After loading your data, you’ll need to get busy coding to clean, visualize, model, and share insights.
As for the most common languages to code in the data science community, we don’t wish to initiate (or continue, you may say) a flame war about Python vs. R; to each their own. But here at Tryolabs, we believe that Python is the best tool for efficient, deployable, fast-paced, and maintainable machine learning projects.
Our recommendations are extensive. Because the reader’s level varies, we will point to several resources, and you can determine your level and what you need.
If you’re completely new to programming, do not despair. Python is not only really powerful, but it’s also easy to learn and a great language to start your programming journey.
Playlist
- Fundamentals of Programming Languages is a great resource for programming first-timers. It takes you through the basic concepts you need to understand before starting with Python.
Courses & notes
Learn Python in Y Minutes is an excellent crash course in the language. If you aren’t familiar with Python, you will be after 30 minutes of reading.
If you speak Spanish, Majo's notebooks are great to start learning about Python Basics. She has two Python notebooks. In the first one, she explains the basics of the language, and in the second one, she explains Object Oriented Programming in Python.
In this case, DataCamp offers a fairly comprehensive Python Programmer career track with almost 60 hours of hands-on content focused on what you’ll need for Data Science.
Exercises
- If you feel inspired, you can test your skills with some exercises.
Git
Virtually every project needs a repository, and virtually every project uses git. Getting familiar with this tool takes some time, and even when you finally master it, you will still find yourself reading the documentation from time to time.
Regarding global skills beyond the specifics of Machine Learning that can greatly further your career, developing solid git skills is among the best investments you can make. Being able to keep your code in order and collaborate with others efficiently really is a must.
Interactive resources
- This interactive tool is something that we have used extensively during our onboarding process. It has proven to be an excellent visual tool for beginners, with some seasoned folks also learning a trick or two.
Documentation & notes
- The official documentation is an excellent reference.
- For Spanish speakers, again, Majo has an awesome notebook for git.
Don’t worry too much about trying with a real project here. We will have time for that.
Deployment: REST APIs
By this point, you already know how to extract data from a database. You’ve built some solid Python foundations and know how to organize your code in git, great job! To further our journey through the fundamental skills adjacent to Machine Learning, we’ll skip the specifics of modeling and assume that you’ve already trained an amazing model.
You should ask yourself, if a decision tree predicts in a random forest and there’s no one around to see the result, is it really predicting? Ok, I’m not proud of this pun, but I think it really nails what I want to say because sharing your model with other applications or other people is an essential part of doing data science.
APIs (Application Programming Interfaces) allow us to take the model we built and actually send it out there to receive data and output results. REST APIs are a form of API that obeys a series of design constraints aimed at standardizing and speeding up communication.
In this regard, Python really flexes its muscles and shows its versatility, with many web frameworks from which to choose. In Tryolabs, we’ve used FastAPI, Flask and Django.
Courses & documentation
Bitfumes FastApi course covers almost everything you’ll need to learn about FastAPI.
For specific questions, FastAPI has great documentation. The same applies to Django's documentation.
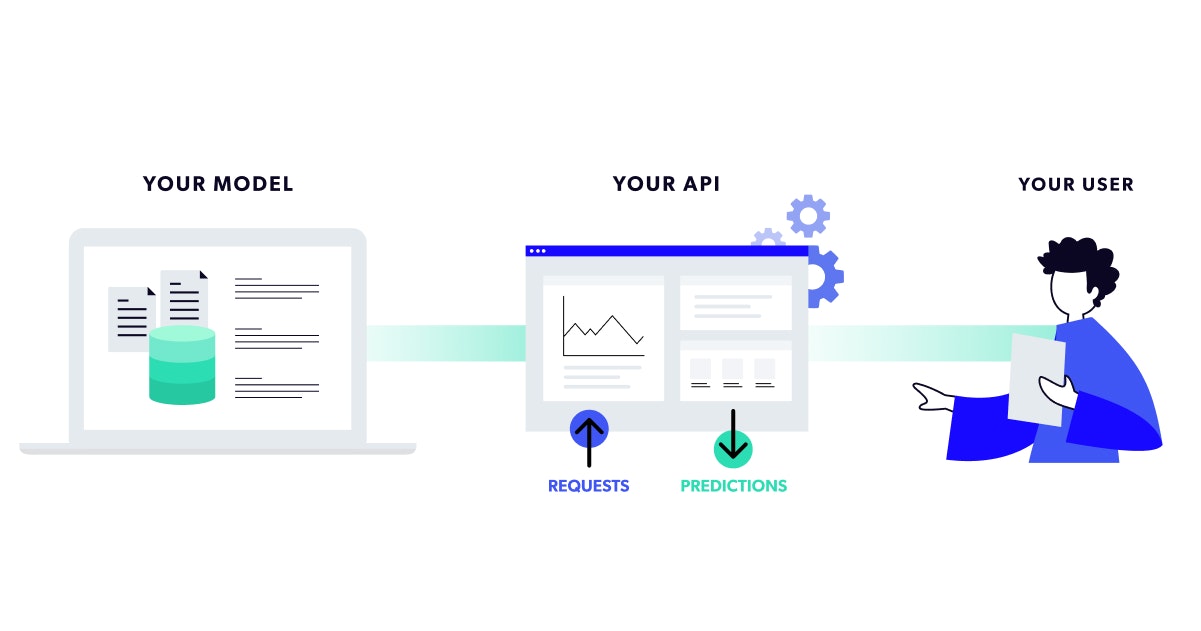
Deployment: Docker
Ok, so, say you have your data, your model, your beautifully written Python code with perfect version control on git, and your API code. Are you production ready?
Well, not really. You need to host your service in some environment, and you’ll need to keep your code updated in said environment. This is a problem because what worked perfectly in your local environment might behave differently in production. Even what worked in production might suddenly crash due to new installations and upgrades.
What can we do? Is there any hope we can make sure our AI systems always work as intended? The answer is yes, there is! Introducing Docker.


Docker is one of the most widespread tools for DevOps out there. It manages to create identical environments using something called containers. In a nutshell, a container is an isolated user space that shares a restricted portion of the host operating system's kernel.
Even though Docker is not the only container manager that exists, it is certainly the most popular. At Tryolabs, we virtually use it in every project because of its versatility. The usual use cases have been creating containers for web applications with the database, web server, and application server running virtualized, Machine Learning projects, and virtualization of ARM-based operating systems.
Courses & documentation
TechWorld has a great introductory tutorial for Docker.
For more specific concerns, you can always read the official documentation.
Beyond the essentials
You can take Andrew Ng’s Intro to Machine Learning in Production for a more complete approach.
Beyond Andrews's specialization, we recommend this full-stack deep learning course that gets deeper into real industry problems.
Fundamentals: Math and Statistics
If you are a student, I’ve got great news for you. Remember when you were studying algebra and calculus, and you asked: what’s the use for this anyways? Remember when your teacher told you that you would discover how useful they are in time? Well, I don’t want to say he told you so, but he told you so.
The general good news is that, even though algebra and calculus are necessary to understand the logic behind machine learning algorithms, it’s not like you need to be an expert to work as a data scientist. Having an understanding of the underlying principles, you can rely on higher-level abstractions for the operations.
Now, statistics is a different matter. To be a half-decent data scientist, you should be able to do statistics like a fish swims, a bird flies, and a T-Rex claps (oh, sorry, T-Rex). Well, maybe not so much, but statistics are actually a part of day-to-day data science. It takes time to learn, but it’s definitely a great investment.
Essentials
Among the great contents of the 3Blue1Brown YouTube channel, you can find playlists on the basics of calculus and algebra.
Beyond these conceptual introductions, the first three lectures of the MIT C229 Machine Learning course of 2019 are great for the basics of algebra and statistics.
Beyond the essentials
Digging deeper into these topics, you can take Stanford's Statistics for applications and Single variable calculus courses.
We recommend the Mathematics for Machine Learning book for a deep and hands-on take on all previous concepts.
Fundamentals: Domain Knowledge
So, you’re a 33rd-degree master coder. You’ve become a total math bender, drunk from Mimir’s well, and have thus attained supreme machine learning knowledge. Is there anything else you need to know?
Well, it might seem obvious, but you still need to know about the specific problem you’re trying to solve. Be it manufacturing, finance, fashion, retail, security, or any of the tens of industries where you want to apply ML. Knowing the context of the problem you’ll be working on is important.
It's actually quite easy to get caught up on the tech problem and forget to look beyond and ask questions about the business. The knowledge gained from such business insights often becomes the key to a powerful solution.
At Tryolabs, we have worked with almost all verticals, ranging from real estate to finance to retail.
Takeaways
Data Science can’t be reduced to modeling. Many skills are involved, and learning them from the beginning can make a difference in your career.
We covered many topics in this post. We know it can feel overwhelming, but, as Lao Tse said, “A journey of a thousand miles begins with a single step.” Just start with whatever excites you the most and move outwards from there. You don’t need to know every topic to start your career.
Many of us here at Tryolabs have started from absolute scratch and managed to become rockstar data scientists (not me, of course, but you should see my teammates; they really know what they’re doing!).
Just be bold and go for it. If you have any questions about your journey, contact us at academy@tryolabs.com.
Get more resources, insights and knowledge

Wondering how AI
can help you?

Terms and Conditions | © 2026. All rights reserved.