

Robust Data Engineering: The force propelling AI forward




The Artificial Intelligence (AI) industry has seen unprecedented growth in recent years, reshaping how we interact with technology. The growth rate accelerated in 2023, with the release of human-like conversation chatbots like ChatGPT, and the plethora of subsequent technologies based on Large Language Models (LLMs) and generative algorithms. As a consequence, the industry is in the midst of an AI-driven revolution, which has the potential to lead the way for future-shaping business opportunities.
The fuel powering all of this AI machinery is data. However, data is only useful if properly processed and integrated into robust and scalable systems. In other words, data processing infrastructures constitute the foundations of high-quality AI products, and mastering the Data Engineering skills needed for their design and implementation holds paramount value.
This lesson has been ingrained in our practice at Tryolabs, borne out of more than 10 years of dedicated work in AI and advanced analytics consulting. Crafting bespoke Data Engineering strategies stands at the heart of our solutions, embodying the essential expertise we deliver to our clients. We've not only navigated the complexities of data-driven challenges but also unlocked tailored, innovative solutions across a diverse range of industries.
In this blog post, we are sharing the essential technical skills but more so the strategic approaches required for crafting scalable and robust data infrastructures. We're doing so through the lens of two projects undertaken by Tryolabs. These examples serve to illustrate how theory and practice intertwine, offering a comprehensive look at the challenges and solutions encountered in our quest to leverage the power of AI.
Exhibit 1: Web traffic analytics for SEO scaling
Back in 2018, this project marked a pivotal moment in our venture into the realm of large-scale Data Engineering. The mission was to architect and deploy a data infrastructure capable of supporting high-volume data reports on web traffic for a leading client in the digital marketing space.
Navigating high-volume data for strategic SEO
We embarked on developing an analytics tool for Search Engine Optimization (SEO), a core component of our client's digital marketing services. The goal was to empower web users—whether individuals or businesses— to boost their online visibility, drawing significantly more traffic by refining their web content strategies.
Faced with the need to process vast volumes of information, our task was to distill actionable data products from the ocean of online traffic data—covering keywords, pages, and domains search frequencies. This wasn't just about handling data; it was about unlocking strategies for SEO success by understanding what makes content appealing to search engines and potential visitors.

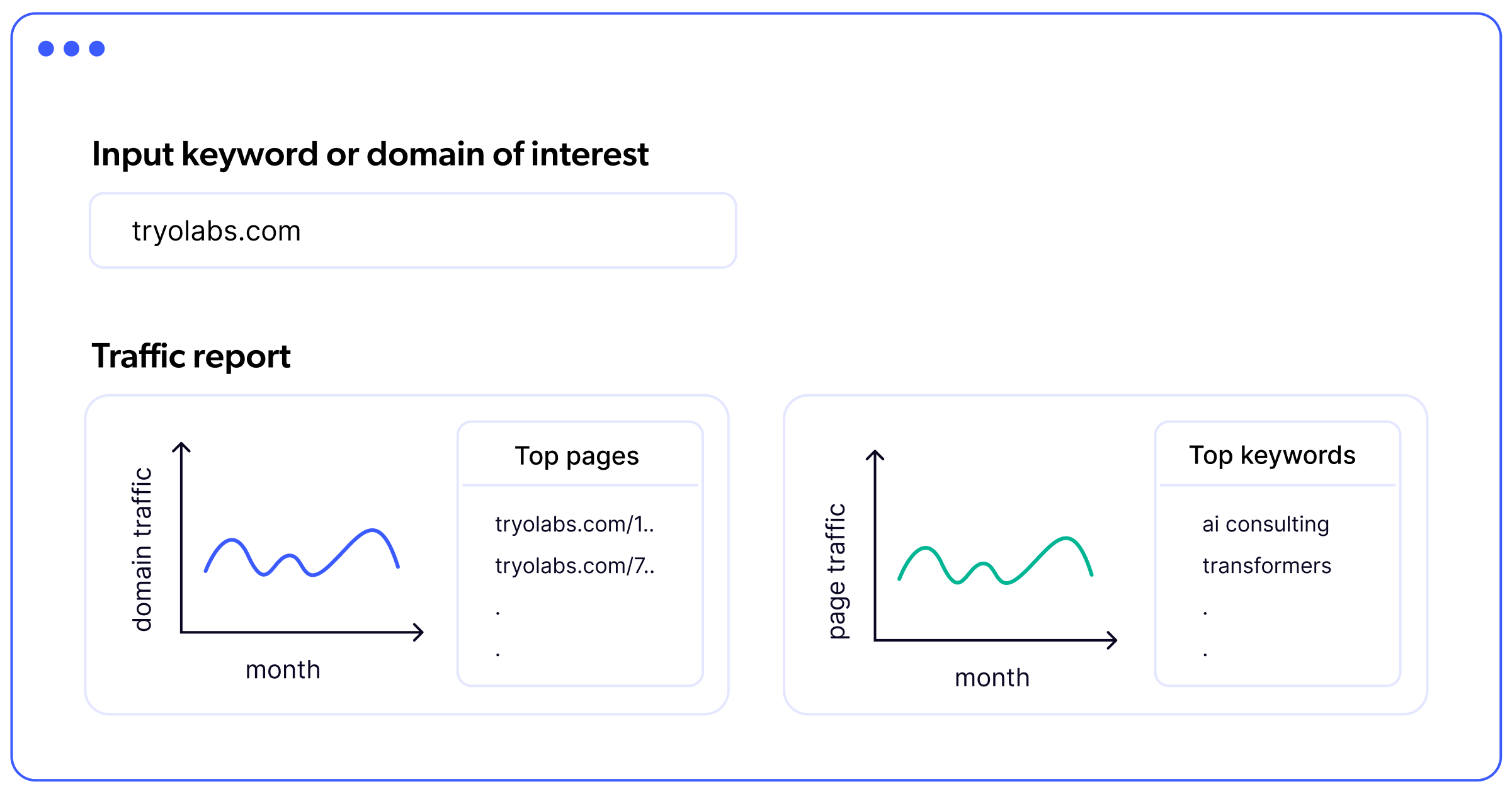

The Data Engineering challenge
To get an idea of the required data processing scale, close to 100 million keywords needed to be processed every day, and monthly aggregations required processing over two billion keywords in less than 48 hours every month.
Tackling this challenge was an ambitious task that demanded a robust, efficient, and scalable data management strategy.
Crafting the solution: Data Engineering in action
Our solution to this challenge was a meticulously planned data processing strategy that encompassed the entire data lifecycle, from acquisition to actionable data products. The approach was threefold:
- Data centralization. Data processing starts by gathering raw traffic data, primarily from Google's SERP, into a unified storage place, setting the stage for all subsequent data transformations.
- Extraction and processing. With raw data centralized, a carefully crafted data process is put in place to convert crude data into ripe data products relevant to the SEO tool.
- Storage and access. The final piece of the puzzle was storing this processed data in a way that made it easily accessible for analysis and reporting. This meant not only choosing the right storage solutions but also making design choices ensuring fast, efficient queries.
Using the Data Engineering lexicon, our infrastructure utilized a combination of data laking, ETL pipelines, and data warehousing (points 1, 2, and 3 above, respectively), ensuring seamless access to data products.
Data Engineering components of the solution
Data laking - gathering files containing Google generated data (e.g. SERP) about any given keyword.
ETL pipeline - extract keyword and associated SERP data from the raw gathered files, transform the data to a custom format and load to various databases.
Data warehousing - the ETL pipeline produces different types of processed data depending on the querying complexity of the required analytical reports, calling for different warehousing solutions.
To bring this vision to life, we leveraged the power and flexibility of Amazon Web Services (AWS). The AWS ecosystem offers a suite of managed and serverless products aligned with our need for scalability and efficiency. This choice allowed us to focus on optimizing our Data Engineering processes without being bogged down by infrastructure management.
Architecture design key decisions
Requirements
- Provision of raw data (batches) by 3rd party should trigger data processing.
- Data processing should be easily scalable.
- Data products should support both simple and complex queries as well as expensive aggregations.
Design decisions
This diagram illustrates the architecture of the implemented data infrastructure. It highlights the specific AWS services employed at each step of the Data Engineering process and the rationale behind our architectural choices.

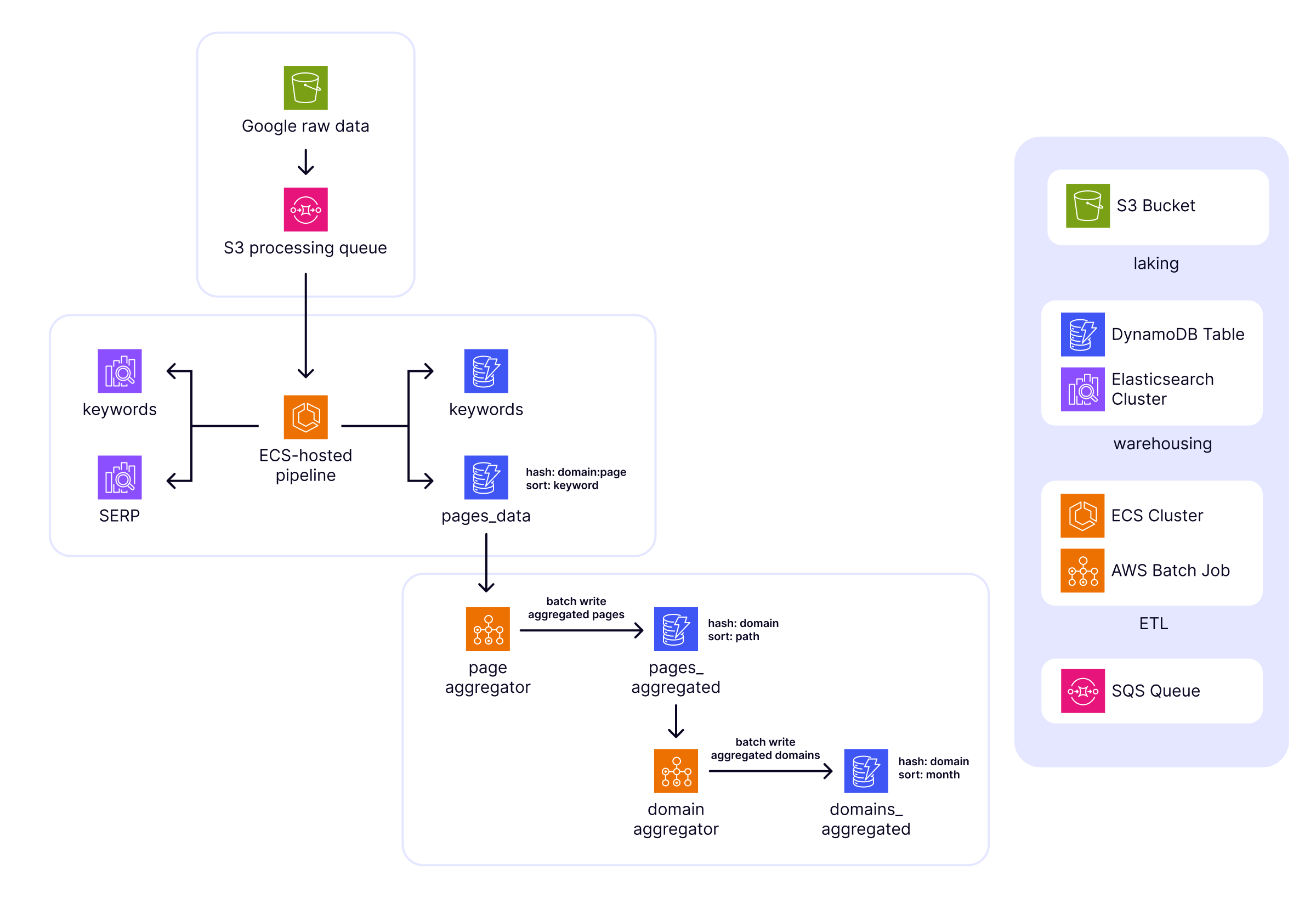
Key architectural insights
Delving into the architecture illustrated in Figure 1.2 provides deeper details about the inner workings of the solution, showcasing how each component contributes to an efficient data infrastructure.
Data laking
An S3 bucket was used as data lake, where raw data files, each containing 100 Google search results for a given keyword (along its metadata), were securely stored upon upload by a third-party provider. The latter triggered an S3 event, queueing a message in an SQS queue, readying the system for the next data processing phase.
ETL pipelines
The ETL pipelines were designed with a dual approach to cater event-based and batch data processing needs.
Event-based custom pipeline
An ECS cluster hosts a docker microservice that continuously listens to the SQS queue. Upon new messages arrival, it downloads the new raw data file from the S3 bucket, process the keyword-related data, and loads it, after custom formatting, into DynamoDB and Elasticsearch.
Batch (monthly) aggregation pipelines
A first AWS Batch Job is used to process the DynamoDB table pages_data to obtain aggregations at page level, writing into the DynamoDB table pages_aggregated, useful for page-level analytics reports.
A second AWS Batch Job is used to process the DynamoDB table pages_aggregated (first batch job) to obtain aggregations at domain level, writing into the DynamoDB table domains_aggregated, useful for domain-level analytics reports.
Data warehousing
The event-based ETL pipeline loads transformed data to two types of storage services:
DynamoDB
keywordsstores keyword metadata (simple queries)pages_dataa huge table partitioned by domain:page and sorted by keyword, that will be used downstream for additional processing (page/domain level aggregations)
Elasticsearch
keywordsstores keyword metadata (complex queries)SERPstores the SERP data for each keyword
Elasticsearch storage resources were needed to process queries of high complexity not possible with DynamoDB.
The first AWS Batch Job aggregates data at page level and loads the output to DynamoDB table pages_aggregated which, being partitioned by domain and sorted by website path, makes access to page level aggregated data more efficient and cost effective.
The second AWS Batch Job aggregates data at domain level and loads the output to DynamoDB table domains_aggregated which, being partitioned by domain and sorted by month, makes access to domain level aggregated data more efficient and cost effective.
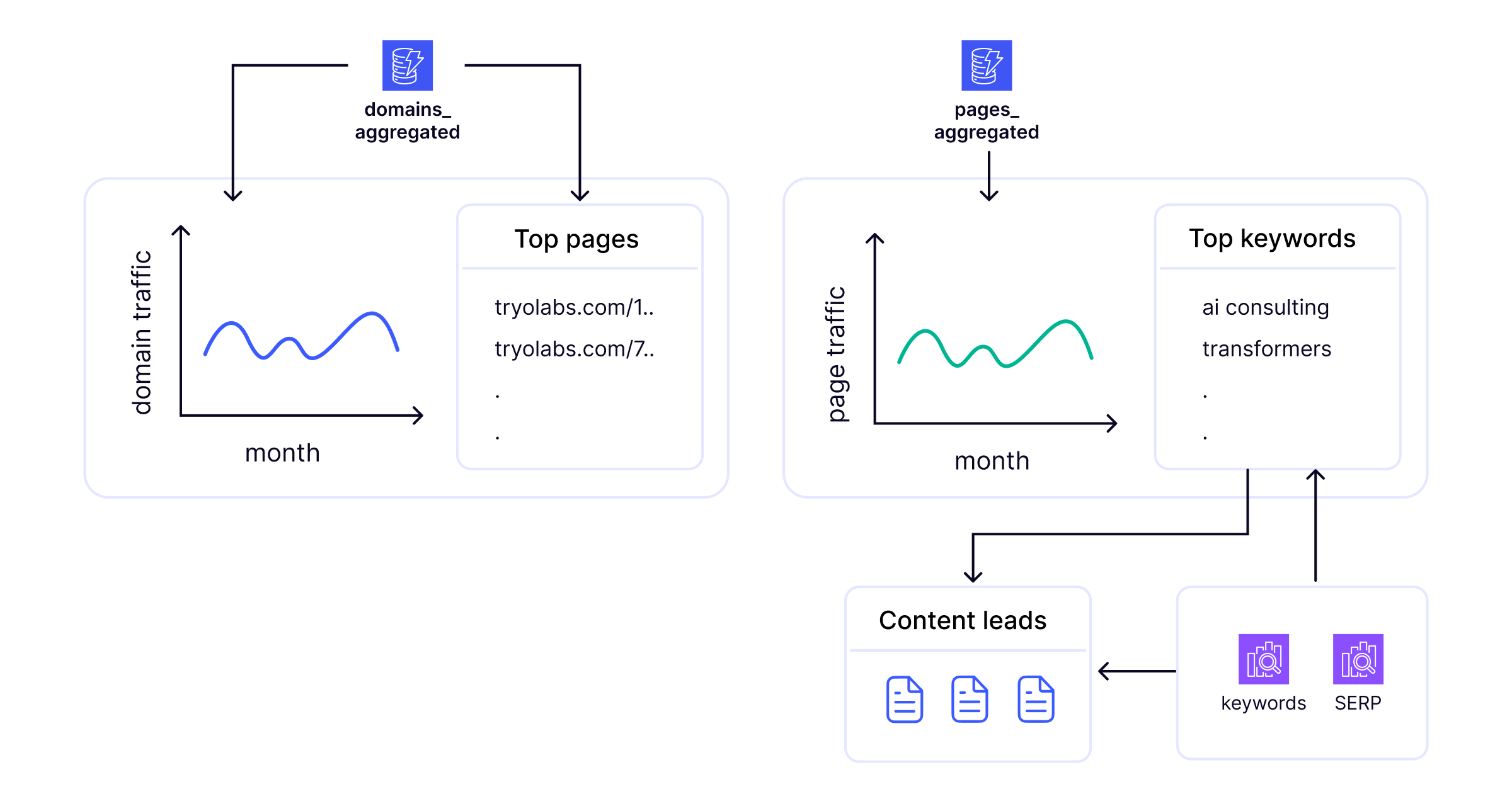
This data infrastructure allowed for the scalable generation of a set of key data products that supported the analytical reports required by the client’s SEO tool (see Figure 1.3).
Key data products
Elasticsearch tables
SERP & keywords: support complex keyword based queries (e.g. top keywords) and complex text searches (e.g. content leads, which are the top ranking pages for a given keyword).
DynamoDB tables
keywords: supports fast and scalable basic reports on keywords related data
pages_aggregated and domains_aggregated: support fast and scalable reports on domain and website traffic evolution.

Takeaways
The implemented infrastructure provided the necessary data products to fulfill the analytics needs of the client, achieving the required throughput (e.g. over 2 billion keywords being processed in less than 48 hrs every month). This was a consequence of appropriate design decisions, some of which are worth highlighting.
Efficient partitioning and sorting keys
Appropriate design of the partitioning and sorting keys in DynamoDB tables played a central role in minimizing table scans, consequently reducing querying costs. This resulted in money-wise efficient data products that were able to support the analytics and reporting needs of the client’s SEO tool.
Deep understanding of DynamoDB
Detailed knowledge of not only partitioning and sorting keys, but also of read and write capacity units and pricing characteristics allowed for appropriate decisions on monthly quote reservations, and table writing mode (only once per record), resulting in performance maximization while keeping low costs.
Choosing the appropriate data warehouse
An appropriate combination of DynamoDB and Elasticsearch allowed for serving data products supporting different querying complexity levels, providing the required data processing flexibility in an affordable manner.
Choosing the appropriate computational scaling method
At the beginning of the project, Spark was an appealing option for data processing parallelization, allowing to leverage a rich environment and set of tools, and reducing maintainability (and future scalability issues). However, (in our hands) a custom parallelization approach resulted in higher throughput (probably a Spark initialization overhead issue). Although this should be revisited if working on a similar project nowadays (remember this project took place six years ago), it is a relevant learning to properly weight the available computational scaling methods, before blindly jumping into mainstream tools.
Exhibit 2: Enhancing online retail with image semantic search
As part of a long-lasting engagement with one of our clients, this project constituted a capstone in our journey towards integrating Data Engineering skills and AI expertise.
The challenge was to build a semantic search service for retail items, providing a robust data infrastructure capable of supporting various Machine Learning applications designed to tackle distinct business challenges.
Developing a unified semantic search engine
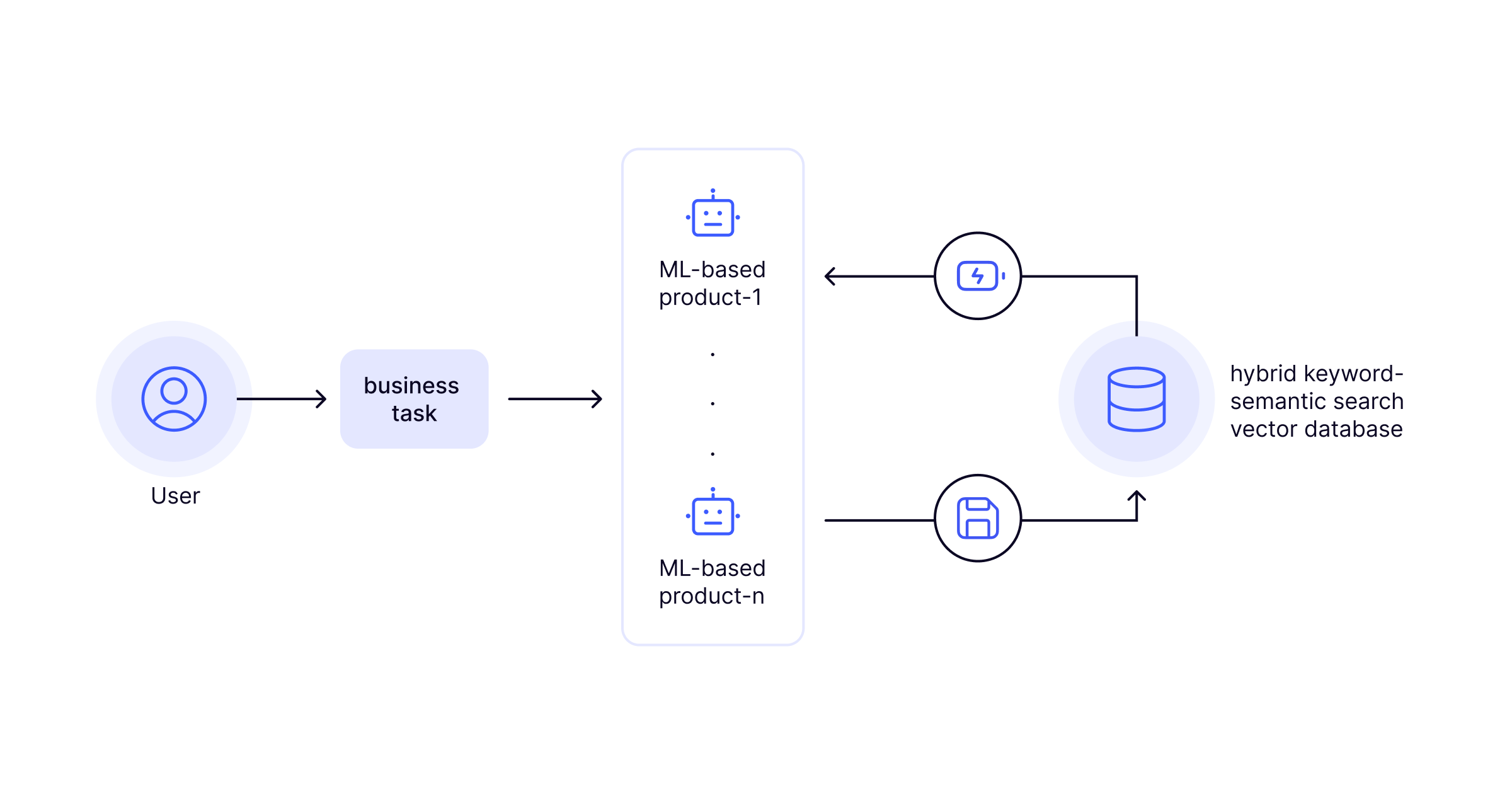
Our mission was to create an image-based semantic search service that could accurately and efficiently identify items similar to a given target, utilizing both image data and item metadata as inputs. This service was envisioned as a central hub, offering support to a suite of ML-driven products, including recommendation systems, dynamic pricing models, and automatic attribute tagging tools. These products work in synergy to address a broad spectrum of business needs (as illustrated in Figure 2.1).
The challenge extended beyond the mere development of these services; it involved ensuring the system could handle the high volume of semantic search queries triggered by user interactions across the ML products. Addressing this required a focused effort on building scalable, real-time data processing capabilities. This endeavor was critical not only for enabling efficient semantic (and keyword-based) searches but also for optimizing the processing of retail items. The outcome was a system that could support timely and effective online product listings, significantly enhancing the retail experience and profitability.

The Data Engineering challenge
Supporting a semantic search service for retail item retrieval, covering over 3.5 million items, and handling close to 80 requests per second, from multiple business processes triggered by an end user that expects a latency below 500 milliseconds.
Fulfilling this endeavor was a challenging task requiring cloud orchestration savviness and proper integration of AI experience into data architecture design.
Building the solution: an AI and Data Engineering mix
The approach we adopted to solve this challenge was a carefully crafted data operation that transformed items metadata from multiple concurrent sources and items images, into entries of a vector database (the core data product) that efficiently serves hybrid keyword/semantic queries. This solution contained four main components:
Data centralization
The first data processing step is gathering all retail item images in a centralized storage location (supporting unstructured data), which works as the reference source for subsequent transformations resulting in vector encodings indexed in the vector database.
Streaming and batch processing
Once images are centrally stored, they are extracted and transformed into vector encodings using neural nets and custom transformations. This is done both in batch and streaming modes. Both modes are also used for items metadata processing, carefully considering a key requirement: the need to integrate multiple concurrent metadata sources.
Storage supporting semantic retrieval
The final step of this data operation is storing the items metadata and vector encoding in a vector database, providing efficient and fast hybrid keyword and semantic retrieval.
Monitoring
With the main components of the data infrastructure up and running, it is critical to ensure adequate performance levels are continuously delivered. To that end, a monitoring service was put in place to track and fire alerts about the health of the vector database.
In Data Engineering terms, this approach required the orchestration of data laking, neural network inference integrated into streaming and batch ETL pipelines, data warehousing, and data product health monitoring (points 1, 2, 3, and 4 above, respectively), resulting in a robust data operation.
Data Engineering components of the solution
Data laking: gathering raw input images of all retail items.
Batch ETL pipeline: items metadata processing, and neural net vector encoding of item images extracted from the data lake.
Streaming ETL pipeline: near real-time processing of multiple source items metadata, and neural net vector encoding of new item images added to the data lake.
Data warehousing: storing ETL pipelines products — processed items metadata and vector encodings — into a vector database supporting hybrid keyword-semantic search and approximate kNN methods.
Monitoring: keeping track of the data warehouse health to ensure the items retrieval service fulfills the performance requirements.
To construct this architecture we combined the AWS, the Google Cloud Platform (GCP), and third-party tools. This allowed us to take advantage of the different strengths offered by such platforms and services, while fulfilling client-specific requirements.
Architecture design key decisions
Requirements
- Integrates (near real-time) items metadata coming from different divisions in the client
- Supports hybrid keyword-semantic search queries
- Low latency serving to multiple internal ML-products
Design decisions
- AWS S3 bucket for images laking, and a Kafka server for multi-source real-time data processing
- GCP Dataflow for batch pipeline, and a combination of Cloud Scheduler and Cloud Run for streaming pipeline
- Warehousing: Elasticsearch (items metadata and image vector encoding) and BigQuery (items metadata)
Here you can see the architecture of the implemented data operation, indicating the particular platform-dependent services used in each piece of the Data Engineering puzzle, along the principles underlying the chosen design.

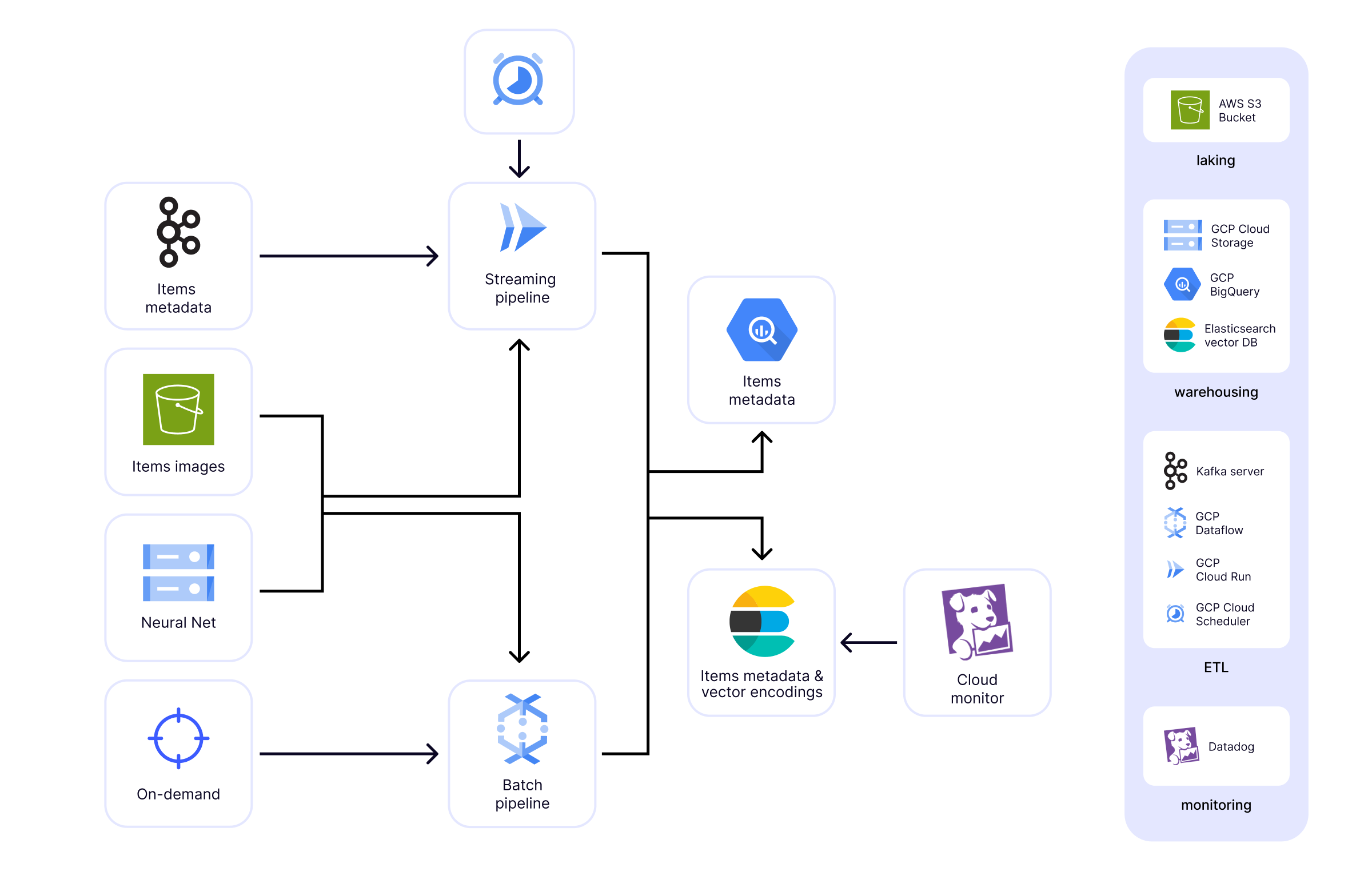
Key architectural insights
Digging into the architecture illustrated in Figure 2.2 sheds light on the features of the implemented solution in finer detail, depicting the interplay between each component, which resulted in a robust data infrastructure.
Data laking
An AWS S3 bucket was used as data lake to store all retail item images, providing a secure and consistent reference point for data extraction by streaming and batch pipelines.
ETL pipelines
An on-demand batch pipeline, implemented using GCP Dataflow (Apache Beam), extracts items images from the AWS S3 bucket, loads a cost effective resnet-50 convolutional neural net (stored on GCP Cloud storage), and uses the latter plus custom normalization (enhances similarity distance accuracy), to generate vector encodings from the images. Items metadata and vector encodings are pushed to an Elasticsearch vector database. In addition, items metadata is also stored in BigQuery to facilitate custom analytics and Elasticsearch backfilling.
A streaming pipeline receives items metadata messages published by different divisions within the client to a Kafka server, which is connected to Cloud Run (triggered using Cloud Scheduler), for near real-time data processing. The latter includes i) the addition of new items, applying the same transformations and storage as used in the batch pipeline, and ii) the continuous integration of items metadata updates published by different teams in the client.
Data warehousing
- A resnet-50 convolutional neural net is stored in a GCP Cloud Storage bucket. This model is used to generate image vector encodings supporting semantic search.
- Items metadata is stored in GCP BigQuery to support custom analytics and Elasticsearch backfilling.
- Items metadata and image vector encodings are stored in an Elasticsearch vector database supporting hybrid keyword-semantic search, and using the Hierarchical Navigable Small World (HNSW) approximate kNN method for efficient similarity-based retrieval.
Monitoring
The status of the vector database is monitored using Datadog, keeping track, for example, of index rates and search rates.
This system robustly supports the generation of key data products, the most relevant being the Elasticsearch vector database providing a hybrid keyword-semantic search service to a battery of ML-products (see Figure 2.1).
Key data products
Elasticsearch vector database: Provides hybrid keyword-semantic search service to multiple ML-based products, allowing for efficient retrieval of business-relevant retail items.
BigQuery tables: Support custom analysis on items metadata and vector database backfilling.
Takeaways
The implemented system provided the necessary data products to fulfill the infrastructure requirements of the client. Appropriate design decisions were key for this result, some worth highlighting.
Processing items metadata coming from multiple sources
An aspect of high importance when designing the data infrastructure for this client was that the metadata of a given item is produced in parallel by multiple teams within the client’s enterprise. Moreover, integration and processing of such metadata needed to be done in near real time. This requirement could be appropriately fulfilled by combining a Kafka server with the Cloud Scheduler and Cloud Run services in GCP. An improvement over the implemented streaming pipeline would be to use Dataflow instead of Cloud Scheduler and Cloud Run, simplifying the design and leveraging a service that is tailored to handle both streaming and batch pipelines.
Relevance of hybrid keyword-semantic search in retail
An advantage of vector databases like Elasticsearch is their ability to combine keyword-based and semantic-based (vector encodings) queries. This is particularly relevant for a retail company, where retrieving items based only on image similarity might not be sufficient to capture the nuances of the items being targeted. Complementing the semantic search with specific text keywords can help cope with such limitations.
Serving multiple ML-based products
The core use of the semantic search service was the support of queries from multiple ML-based products achieving specific throughput and latency thresholds. This requirement was successfully met thanks to the scalability features and efficient approximate kNN search algorithm offered by the Elasticsearch vector database. Such a data infrastructure provided the foundations for key ML services, including recommendations and automatic attribute tagging systems, working in concert to increase business productivity.
Looking ahead
It’s clear that the journey of integrating advanced Data Engineering with AI is both a challenging and immensely rewarding endeavor. The projects we've shared exemplify not just the technical and strategic depths we navigate at Tryolabs but also our commitment to pushing the boundaries of what's possible in AI and analytics.
The evolution of the AI industry demands continuous innovation and adaptability. Our experiences underscore the importance of solid Data Engineering foundations to not only meet current needs but also to anticipate future challenges and opportunities.
Stay tuned for for more insights and stories from the forefront of AI and Data Engineering, which will serve as useful references to your path to building AI-based innovative technologies.

Wondering how Data Engineering + AI can help you?

Terms and Conditions | © 2026. All rights reserved.