

The major advancements in Deep Learning in 2016


Deep Learning has been the core topic in the Machine Learning community the last couple of years and 2016 was not the exception. In this article, we will go through the advancements we think have contributed the most (or have the potential) to move the field forward and how organizations and the community are making sure that these powerful technologies are going to be used in a way that is beneficial for all.
One of the main challenges researchers have historically struggled with has been unsupervised learning. We think 2016 has been a great year for this area, mainly because of the vast amount of work on Generative Models.
Moreover, the ability to naturally communicate with machines has been also one of the dream goals and several approaches have been presented by giants like Google and Facebook. In this context, 2016 was all about innovation in Natural Language Processing (NLP) problems which are crucial to reach this goal.
Unsupervised learning
Unsupervised learning refers to the task of extracting patterns and structure from raw data without extra information, as opposed to supervised learning where labels are needed.
The classical approach for this problem using neural networks has been autoencoders. The basic version consists of a Multilayer Perceptron (MLP) where the input and output layer have the same size and a smaller hidden layer is trained to recover the input. Once trained, the output from the hidden layer corresponds to data representation that can be useful for clustering, dimensionality reduction, improving supervised classification and even for data compression.
Generative Adversarial Networks (GANs)
Recently, a new approach based on generative models has emerged. Called Generative Adversarial Networks, it has enabled models to tackle unsupervised learning. GANs are a real revolution. Such has been the impact of this research that in this presentation, Yann LeCun (one of the fathers of Deep Learning) said that GANs are the most important idea in Machine Learning in the last 20 years.
Although introduced in 2014 by Ian Goodfellow, it is in 2016 that GANs have started to show their real potential. Improved techniques for helping training and better architectures (Deep Convolutional GAN) introduced this year have fixed some of the previous limitations, and new applications (we list some of them later) are revealing how powerful and flexible they can be.
The intuitive idea
Imagine an aspiring painter who wants to do art forgery (G), and someone who wants to earn his living by judging paintings (D). You start by showing D some examples of work by Picasso. Then G produces paintings in an attempt to fool D every time, making him believe they are Picasso originals. Sometimes it succeeds; however as D starts learning more about Picasso style (looking at more examples), G has a harder time fooling D, so he has to do better. As this process continues, not only D gets really good in telling apart what is Picasso and what is not, but also G gets really good at forging Picasso paintings. This is the idea behind GANs.
Technically GANs consist of a constant push between two networks (thus "adversarial"): a generator (G) and discriminator (D). Given a set of training examples (such as images), we can imagine that there is an underlying distribution (x) that governs them. With GANs, G will generate outputs and D will decide if they come from the same distribution of the the training set or not.
G will start from some noise z, so the generated images are G(z). D takes images from the distribution (real) and fake (from G) and classifies them: D(x) and D(G(z)).

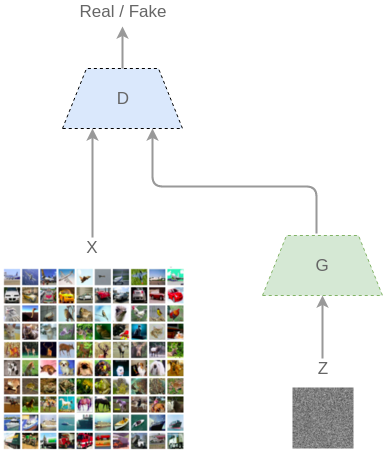
D and G are both learning at the same time, and once G is trained it knows enough about the distribution of the training samples that it can generate new samples that share very similar properties:


These images were generated by a GAN trained with CIFAR-10. If you pay attention to the details, you can see they are not indeed real objects. However, there is something to them that captures a certain concept that can make them look real from a distance.
InfoGAN
Recent developments have extended the GANs idea to not only to approximate the data distribution, but also to learn interpretable, useful vector representations of the data. These desired vector representations need to capture rich information (same as in autoencoders) and also need to be interpretable, meaning that we can distinguish parts of the vector that contribute to a specific type of shape transformation in the generated outputs.
The InfoGAN model proposed by OpenAI researchers in August addresses this issue. In a nutshell, InfoGAN is able to generate representations that contain information about the dataset in an unsupervised way. For instance, when applied to the MNIST dataset it is able to infer the type of number (1, 2, 3, ...), the rotation and the width of the generated samples without the need for manually tagged data.
Conditional GANs
Another extension of GANs is a class of models called Conditional GAN (cGAN). These models are able to generate samples taking into account external information (class label, text, another image), using it to force G to generate a particular type of output. Some applications that have recently surfaced are:
Text to image
Takes a textual description (encoded as a vector by a character level CNN or LSTM) as external information and it generates image based on it. See Generative Adversarial Text to Image Synthesis (Jun 2016).
Image-to-Image
Maps input image to output image. See Image-to-Image Translation with Conditional Adversarial Nets (Nov 2016).
Super resolution
It takes downsampled images (less details) and the generator tries to approximate them to more natural detailed version. Anyone who ever watched CSI knows what we are talking about :)
See Photo-Realistic Single Image Super-Resolution Using a Generative Adversarial Network (Nov 2016).



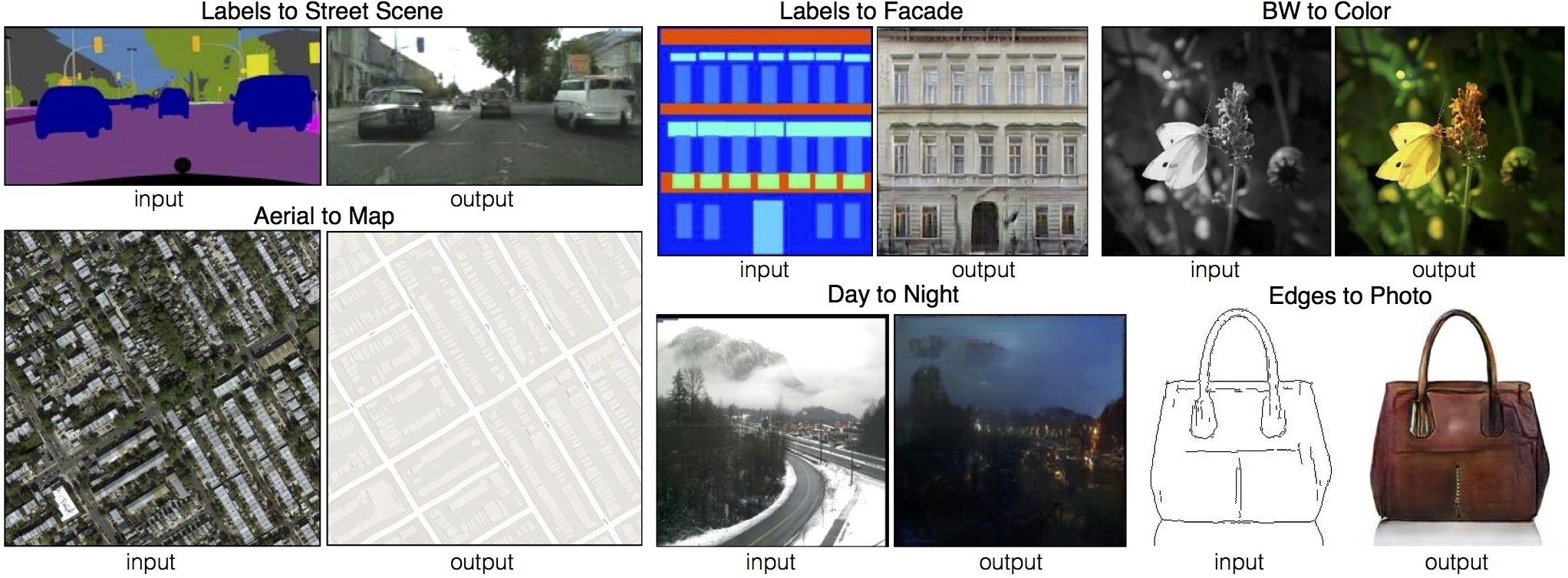


You can check more about generative models in this blog post or in this talk by Ian Goodfellow.
Natural Language Processing
In order to be able to have fluent conversations with machines, several issues need to be solved first: text understanding, question answering and machine translation.
Text understanding
Salesforce MetaMind has built a new model called Joint Many-Tasks (JMT) with the objective of creating a single model able to learn five common NLP tasks:
Part-of-speech tagging : Assign parts of speech to each word, such as noun, verb, adjective.
Chunking : Also called shallow parsing. Involves a range of tasks, like finding noun or verb groups.
Dependency parsing : Identify syntactic relationships (such as an adjective modifying a noun) between words.
Semantic relatedness : Measure the semantic distance between two sentences. The result is a real-valued score.
Textual entailment : Determine whether a premise sentences entails a hypothesis sentence. Possible classes: entailment, contradiction, and neutral.
The magic behind this model is that it is end-to-end trainable. This means it allows collaboration between different layers, resulting in improvements on lower layers tasks (which are less complex), with the results from higher layers (more complex tasks). This is something new compared to older ideas, which could only use lower layers to improve higher level ones, but not the other way around. As a result, this model achieves state of the art results in all but POS tagging (where it came out in second place).
Question Answering
MetaMind also presented a new model called Dynamic Coattention Network (DCN) for the question answering problem, which builds on a pretty intuitive idea.
Imagine I was going to give you a long text and ask you some question. Would you prefer to read the text first and then be asked the question, or be given the question before you actually start reading the text? Naturally, knowing in advance what the question will be conditions you so you know what to pay attention to. If not, you would have to pay equal attention and keep track of every detail and dependencies, to cover for all possible future questions.
DCN does the same thing. First, it generates an internal representation of the documents conditioned on the question that it is trying to answer, and then starts iterating over a list of possible answers converging to the final answer.
Machine Translation
In September, Google presented a new model used by their translation service called Google Neural Machine Translation (GNMT). This model is trained separately for each pair of languages like Chinese-English.
A new GNMT version was announced in November. It goes a step further, training a single model that is able to translate between multiple pairs of languages. The only difference with the previous model is that it now GNMT takes a new input that specifies the target language. It also enables zero-shot translation meaning that it is able to translate a pair of language that it wasn't trained to.
GNMT results show that training it on multiple pairs of languages is better than training on a single pair, demonstrating that it is able to transfer the "translation knowledge" from one language pair to another.
Community
Several corporations and entrepreneurs have created non-profits and partnerships to discuss about the future of Machine Learning and making sure that these impressive technologies are used properly in favor of the community.
OpenAI is a non-profit organization that aims to collaborate with the research and industry community, and releasing the results to public for free. It was created in late 2015, and started delivering the first results (publications like InfoGAN, platforms like Universe and (un)conferences like this one) in 2016. The motivation behind it is to make sure that AI technology is reachable for as many people as possible, and by doing so, avoiding the creation of AI superpowers.
On the other hand, a partnership on AI was signed by Amazon, DeepMind, Google, Facebook, IBM and Microsoft. The goal is to advance public understanding of the field, support best practices and develop an open platform for discussion and engagement.
Another aspect worth highlighting is the openness of the research community. Not only can you find almost any publication on sites like Arxiv (or Arxiv-Sanity) for free, but you can also now replicate their experiments by using the same code. One useful tool is GitXiv, which links Arxiv papers with their open source project repository.
Open source tools are everywhere (as we highlighted in our 10 main takeaways from MLconf SF blog post). They are used and created by researchers and companies. Here is a list of the most popular tools in 2016 for Deep Learning:
- TensorFlow by Google.
- Keras by François Chollet.
- CNTK by Microsoft.
- MXNET by Distributed (Deep) Machine Learning Community. Adapted by Amazon.
- Theano by Université de Montréal.
- Torch by Ronan Collobert, Koray Kavukcuoglu, Clement Farabet. Widely used by Facebook.
Final Thoughts
It is a great time to be part of the recent Machine Learning developments. As you can see this year has been particularly exciting; the research is moving at such a rapid pace that it's hard to keep up with latest advancements. We are truly lucky to be living in an era where AI has been democratized.
At Tryolabs we are working in some very interesting projects with these technologies. We promise to keep you all posted with our findings and continue sharing experiences with the industry and all the interested developers out there.
We reviewed a lot in this post, but there were many other great developments that we had to leave out. If you feel we have not done enough justice to some of these, please feel free to say so in the comments below!
Update (12/09/2016): there have been really good contributions on the discussion of this post on Reddit and HackerNews (see links below). In particular, the arguments about AlphaGo (Deep Reinforcement Learning), ByteNet, WaveNet, PixelRNN / PixelCNN and some others are very interesting. Make sure you read through and enlighten yourself!

Wondering how AI
can help you?

Terms and Conditions | © 2026. All rights reserved.