
Wed, Mar 27, 2019


There's some great theory around about pricing with machine learning (ML) and, in particular, the importance of the "right" data to build a successful ML model.
In practice, though, we've seen that there's a lot of confusion around the data types and formats that retailers can use to automate pricing or to implement price optimization systems using ML.
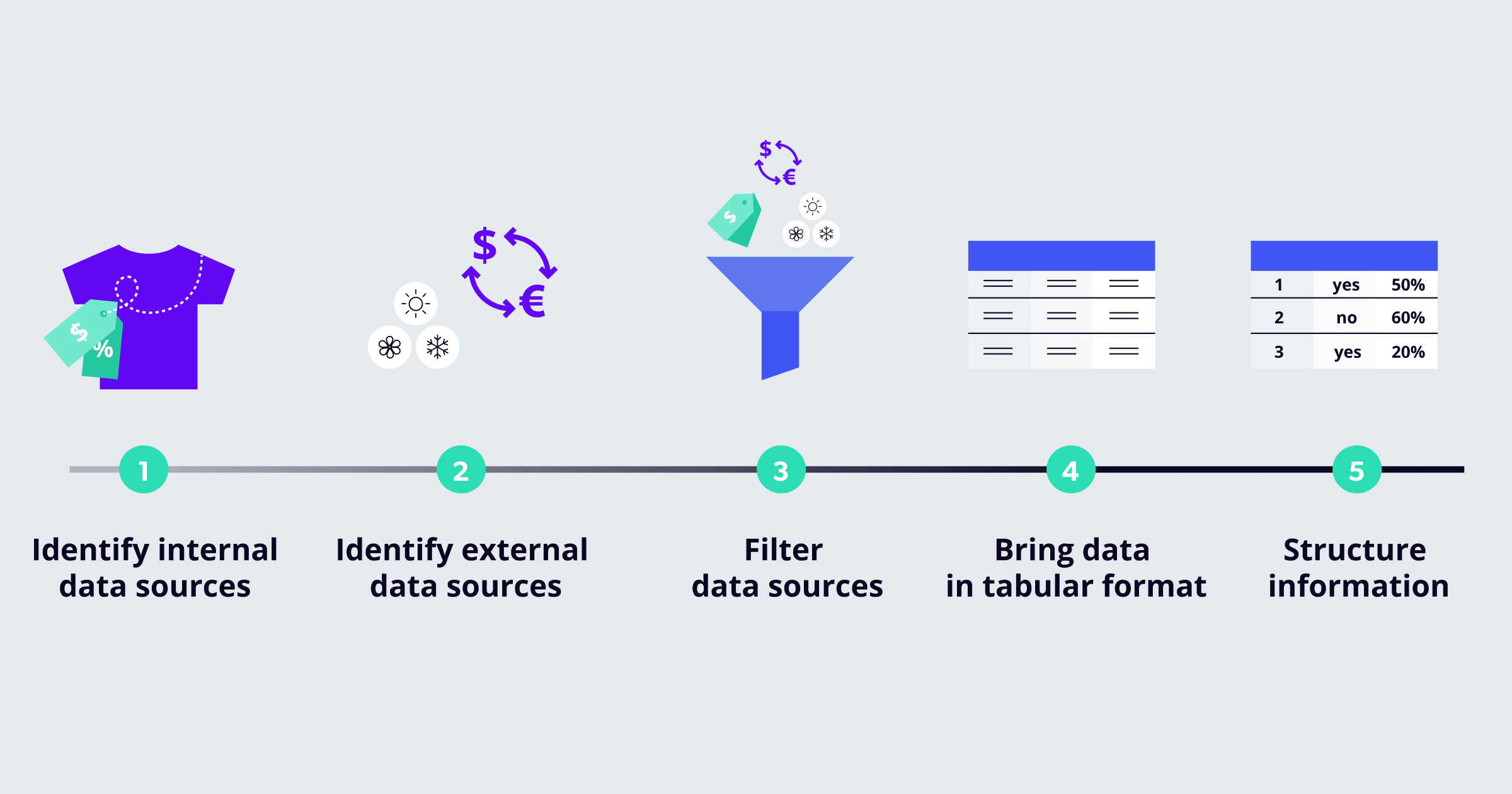
That's why we came up with 5 steps every company can take to prepare its data for price optimization. Follow them and you'll be ready to train your own ML model. Let's get started!

Step 1: Nail down available data sources
There's a wide range of useful information that retailers already have at their disposal when implementing a pricing solution with ML.
Kick off your data preparation project by considering all the inside information that you have that could be of value to your ML pricing solution. If you are unsure whether a variable could have an influence on a price or not, add it to the list. Further down the road, there will be a chance to prioritize and filter what data you’ll actually utilize.
Define example products. What are some typical products you sell?
Check the pricing of said example products. What do you currently charge for these products or, in the case of dynamic pricing, what is that range?
Identify internal data sources. What internal data do you have that you considered when you determined or changed this product's price? What internal data sources might you not be considering now but may eventually include down the road? Make a list. Insightful information can include product descriptions, product pictures, production costs, existing prices, or historical data.
Step 2: Go beyond the convenient data sources
Besides the internal data sources that you summarized in Step 1 above, there's external information that could affect customer demand and impact the determination of the best price. Examples include weather forecasts, exchange and inflation rates, local demand, and competitor pricing. These might be external data sources since retailers normally don't collect this type of information.
However, pricing systems that rely on machine learning have the sizeable advantage of being able to incorporate these factors. So, go wild and think of all the data you don't have internally that could have an impact on your customer's behavior and your pricing.
Define additional pricing factors. What are all the factors that you believe influence your buyers’ behavior and your pricing, but for which you'd need to obtain external data?
Find data sources. What are the possible sources for this information? Is the data publicly available? Are there third-party providers? List them out.
Check access to third-party data. If it’s possible to get the data from third-party providers, how is it accessed? Is there an API or would the provider agree to share the data in some other way with you? Could you scrape the data? If there's no way to access the data, you may want to start collecting the data yourself for future reference.
Tip: When choosing data providers, look for reputable organizations with relatively large infrastructures that are less likely to change over time and ideally offer web service APIs. This will save you future retooling when adapting to changes they make.
Step 3: Say goodbye to low-priority data
This is the time for a reality check regarding all that glorious, shiny, ideal data. It is a highly valued thing and usually not accessible without investing some considerable resources. There are financial and labor costs associated with the collection and preparation of data, and these require you to prioritize desirable data sources according to their capacity to determine the best pricing for your products.
Determine the impact of pricing factors. What's the impact of these factors from Steps 1 and 2 on your product pricing? Are your product sales strongly seasonal? Are related products frequently bought together? Try to come up with a low, moderate, or high impact ranking for each of them and you will begin to get an idea of what you can gain from all your information.
Determine the costs of collecting data. How hard will it be to add the factor to your current dataset given all of the external data? Can you query it from your database? Do you need to hire someone to collect that data for you? Again, it would be helpful to categorize the data using low, moderate, and high rankings based on how challenging it would be to incorporate it into your system.
Prioritize your data. What are the most valuable data sources according to their expected value and estimated costs, given your specific budget? Most of the time it's not necessary to have super duper completely perfect information to get good results, so if that's the case, don't feel discouraged! Start small and work your way up.
Step 4: Apply a tabular format to your data
It's far easier to train ML models if you have structured data. A basic structure that is universally used is the tabular format, where rows represent different items sold, and columns the attributes of each item. Here's how to formulate your own product-price table:
- Create a table for each product type. What is a typical product you sell that can be used as an example product? What type of product is it? Create a separate table for each product type.
- Determine the columns in the table. What are the pricing factors you identified in Steps 1-3? Add them to the column headings and make one for the sales price.
- Migrate your database. Now that you have defined the structure of your data, complete the table by adding the required information for every product given its product type. You'll need to do this for all the product types you want to automate pricing for. Most retailers already have the data available in the software they use, but it's likely to be spread out across several tables, formats, and possibly even sources. It's important to bring all this information into a single table.
Unstructured information of shirts sold:
| Product SKU | Unit price | Date sold | Fabric | Size | Competitor Unit Price | Description |
|---|---|---|---|---|---|---|
| 0001 | 50 | 19/01/08 | Silk | S | 40 | Winter 2018, long sleeved silk shirt. |
| 0002 | 40 | 18/08/30 | Cotton | XL | 35 | Summer 2016, short sleeved cotton shirt. Dinosaur print. |
| 0003 | 30 | 19/03/25 | Linen | M | 50 | 40 Spring 2015, short sleeved linen shirt. Floral pattern. |
Not sure if you're collecting the right data for a pricing solution with machine learning?
We can help you evaluate your datasets.
Step 5: Transform values into structured data types
Many retailers store data about their products in free-form text, such as the text in "description" in the example table “Unstructured information of shirts sold” above. Thing is, free-form text is not easily understood by machines and should be avoided as often as possible.
So, if you have free-form text, try to identify text patterns in your product descriptions. Is any of the information in your descriptions repeated for different products? In the example above, repeat information would be the year of the collection and information about short/long sleeves. These details can be extracted to separate, structured columns.
It's also very common to find categorical data among free text entries. You will likely have a list of brands that you deal with. Besides extracting the brand from the description and making it a separate field, you can provide a choice input and make data entry easier, as well as avoid typos and other mistakes.
Here’s what you can do if you have free-form text with repeat information:
- Detect repeating patterns in free-form text. What information seems to be repeated or duplicated in your free-form text? If you find any, separate it out from the text.
- Determine the type of data. What type of data is the information you’ve separated out? Data types that are utilized include:
- Boolean: Yes/No values.
- Numeric: integer or real values. Are there limits involved? Prices can't be negative, components can't be larger than 100%. Try to enforce such boundaries on the data.
- Categorical: one value out of a set of options. The states of a country are a good example of a categorical field.
- Ordinal: like categorical but where the options follow some order. Zip codes can be an example of an ordinal field.
- Transform your data and enforce each type. Once you've determined the fields and types you can extract from the text, you should try converting previous data into the new formats and adapting your data entry to conform to it. If you have validation rules to apply, such as the aforementioned limits, this is a good time to do it.
Continuing with the example table from Step 3, the table below shows what structuring the original description field would look like. Notice here that collection is now an ordinal field while sleeve length and pattern/print are categorical ones.
Structured information of shirts sold:
| Product SKU | Unit price | Date sold | Fabric | Size | Competitor Unit Price | Collection | Sleeve length | |
|---|---|---|---|---|---|---|---|---|
| 0001 | 50 | 19/01/08 | Silk | S | 40 | Winter 2018 | Long | None |
| 0002 | 30 | 18/08/30 | Cotton | XL | 35 | Summer 2016 | Long | Dinosaur |
| 0003 | 40 | 19/03/25 | Linen | M | 50 | Spring 2015 | Short | Floral |
Tryolabs tip: Store data, as much as you can
Data is at the heart of every successful ML model. This is why we cannot emphasize enough the importance of storing your data. Here are some typical scenarios you should keep in mind when doing so:
- I have identified data that is relevant to determining my product pricing but I'm currently not storing that data. → Start doing it right away!
- I've made a price correction. → Write down the reason why you did it and save it!
- I've used a specific method to measure a certain attribute (e.g. T-shirt sizes are measured manually, not taken from the tag). → Describe the method in the notes.
- I've applied quality control to my data (revised my data and corrected wrong information). → Take note of how you did it and what data was involved.
Sometimes, there's information we use for decision making at a point in time and then forget, thinking we won't use it in the future. Well, with ML, just like with any learning, this works a bit differently. Those reasons you based your decision on can be useful input for an ML algorithm. Maybe when pricing reveals a certain trend, a correction is in order; perhaps one method of measurement provides more accurate results; maybe the reason this data is off is because the last quality check was performed a long time ago.
All of these inputs can be of use in understanding and modeling a process more precisely. Thus, whenever possible try to keep track not only of what you did but also why and how you did it.
What's next?
The amount of data needed to train an ML model depends on individual business needs and unique goals. Generally-speaking, the more data you have, the better. Data collected over the last 3-12 months is a good start, whereas data from more than a year will allow you to account for seasonal pricing factors.
Once you've gathered enough data, it can be used by engineers to train the ML model to start automating and optimizing your pricing process. If you'd like to learn the next steps of the price optimization process, you can check out this detailed article.
We hope this post helps you transform your data into usable information and brings you one step closer to implementing a successful pricing solution using ML.
Wondering how AI can help you?

© 2025. All rights reserved.