

Price optimization for e-commerce: a case study




We have previously discussed how a data-driven price optimization is no longer an option for retailers, but a question of how and when to do it. With a world that's moving towards changing prices more and more dynamically, static pricing strategies can't keep up, and data-driven approaches have arrived to stay. In this post, we'll be focusing on how to perform data-driven price optimization, using a case study to showcase what can be done using sales data to predict demand and optimize prices.
Having read our previous post, you may now ask yourself:
- Is price optimization with Machine Learning worth the investment in my case?
- How do I know if the quality of my sales data is good enough?
- Or putting it simply: price optimization, here I go! But am I ready?
To address these and other questions, we will demonstrate a practical example using the tools we've developed in the past years while excelling in our client's pricing strategies. To do so, we will take the publicly available dataset from the Brazilian marketplace Olist as our use case foundation.
This will be a glimpse of what you can achieve by sharing your sales data with us. We could perform an opportunity summary report in line with this use case, and uncover your own opportunities regarding price optimization. So, fasten your seatbelt and get ready for the take-off.
Analyzing an E-Commerce's Sales Data
While diving into the practical example and explain how we solve these kinds of problems, let's refresh some price optimization concepts and introduce the work pipeline we will follow. There are different ways to tackle a price optimization problem and different strategies to perform a Machine Learning approach for this task.
Our price optimization pipeline will be based on six phases or steps:
- Data Collection and Integration: build a data asset that integrates all the relevant information for demand forecasting.
- Data analysis: generate explanatory data analysis reports and categorize items according to demand patterns.
- Anomaly detection report: generate an anomaly detection report to identify inconsistent fields, detect out-of-stock issues, observe sales distribution, and detect outliers.
- Demand forecasting: estimate the demand curves for each one of the items, i.e., understand the elasticity of the demand.
- Experimentation: elaborate the strategy on how to perform exploration and exploitation.
- Optimization: optimize the price for the items, subject to a list of specific business constraints.
In the remainder of the post we will describe each one of these steps using the Olist dataset as an explanatory example.

1. Data Collection and Integration
The first step is to build our data asset, taking different sources of information that will be used to train our demand forecasting models.
The cornerstone to begin working on any price optimization project is the sales dataset, i.e., to have the sales information of your business. Whether you are an e-commerce or a brick-and-mortar store, sales information is the first asset we have to focus on, and where our analysis will begin.
What do we mean by the sales dataset? To put it simply, we need access to the sales information of the business segment that the company is willing to optimize the pricing strategy for. If you already know beforehand which segment this is, great! You are one step ahead. But if you don't, no worries, we can help you decide which is the best segment to start based on your sales information, as we will see in our example.
Usually, companies choose to store their sales information in one of the following structures:
- By sales transactions: each transaction detail with its item identifier, the timestamp, the number of items sold, and its sell price. Other data fields that can be useful to complement this information are the payment method (cash, credit card, etc.) and the shipping information.
- By daily aggregation: some companies store their sales information this way because they need to have an accurate cash flow.
Complementing your sales data
Naturally, sales data won't be the only source of information we will consider when addressing the price optimization task. As demand is affected by several factors (such as the price, competitor's price, season, holidays, and macroeconomic variables), this is only one of the many factors to consider.
At this point, the knowledge of a business expert will play a big part to jointly work on a data structure that works for each specific problem.
Once again, don't worry if you are not storing all this data currently. We can quickly provide you with several of these public datasets.
Here we list other sources of information that are usually considered when collecting data:
- Items information: data such as category, sub-category, description, number of photos, photos, and general characteristics can be used to profile each item and relate it with others.
- Macroeconomics: different indicators such as GDP, unemployment rate, consumer confidence, and currency exchange. It is crucial to keep in mind that these indicators are all gathered during different periods. Some of them are calculated quarterly, some others monthly, and some others daily.
- Stores or seller information: location, size, etc.
- Holidays and events: certain holidays and events can have a direct impact on the number of sales of different items, e.g., Valentine's Day, Christmas, Mother's Day, etc.
- Item's reviews: reviews performed by customers can also be included in our forecasting model.
- Competitor(s)' price: the presence of one or several strong competitors can have a direct impact on the demand of our items, so having information about how they are pricing can potentially be used as insights for our models.
- Customer traffic: number of visitors (e-commerce and brick-and-mortar), average time on page, and number of clicks (e-commerce only).
- Other business-specific information.
2. Data Analysis
Now that the basics are clear let's dive into the Olist e-commerce data. We always start working on an exploratory data analysis of the sales data to gain insights about the different available items, their trends in the sales, and the pricing history as well.
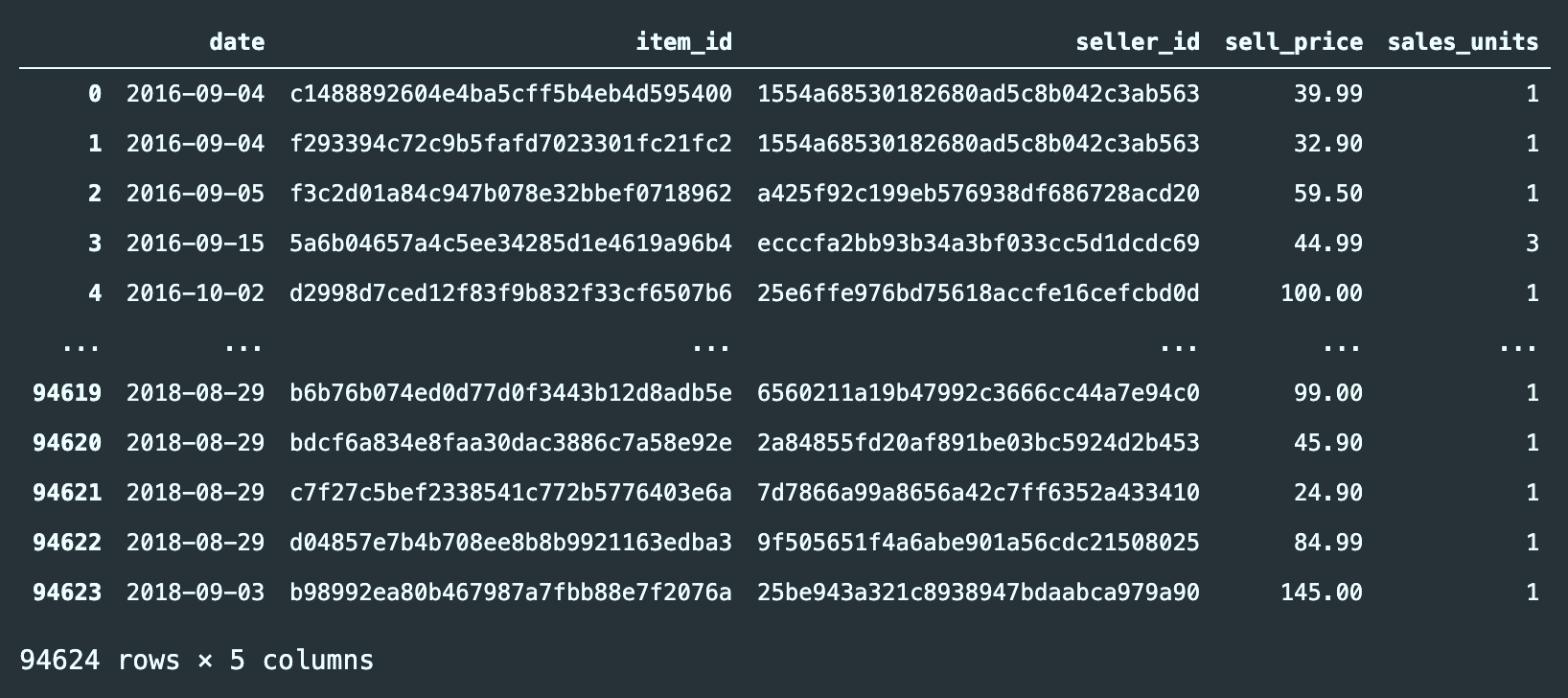
For the Olist example, the sales data is stored as transactions, divided into three different datasets:
order-items: which includes the items and sell price for each order.orders: contains all the information related to the orders, such as customer, seller, order status, order timestamp, and the estimated delivery date.order-payments: it includes the payment information for each order.
After processing these three datasets, we can build a standard sales dataset, as shown in the following figure, which aggregates item-seller sales per day:

Once we define the sales dataset, we should question ourselves how many items should we choose to begin the optimization? Or even further: are all items ready to be optimized?
To begin with, we will set a threshold on the number of historical sales observations. To estimate the future demand for a given item, we need historical sales data. Therefore, we will start considering those articles that have, at minimum, ten weeks with at least 1 unit sold.
Using this threshold, in our Olist use case, we will have a universe of 1,197 items. On the other hand, we could think of a price automation solution for those unique items that are sold only once or very few times.

Moreover, this subset of items can be further categorized. In particular, we will classify items based on demand history and the number of different prices that have historically been used. The shape of the demand history will have a direct impact on the modeling efforts, and so will the number of price changes on the experimentation strategy. Therefore, we will divide our approach into two different stages to select the first set of items:
- Study the variability of the demand history concerning timing and magnitude.
- Study the number of price changes and timing.
Variability of the demand history
At this first stage we will study the variability of the demand history, as we are looking to identify those items that have a simpler selling pattern than others. This approach will not only impact the final accuracy of the sales forecasting but also the feature engineering and modeling efforts.
To perform this categorization, we will use the one proposed by Syntetos et al. (2005), in which the demands are divided into four different categories:
- Intermittent, for items with infrequent demand occurrences but regular in magnitude
- Lumpy, for items whose demand is intermittent and highly variable in magnitude
- Smooth, for items whose demand is both frequent and regular in magnitude
- Erratic, for items whose demand is frequent but highly variable in magnitude
In the following figure, we show how each of these demands would look like in a typical scenario, plotting the demand magnitude to the time.

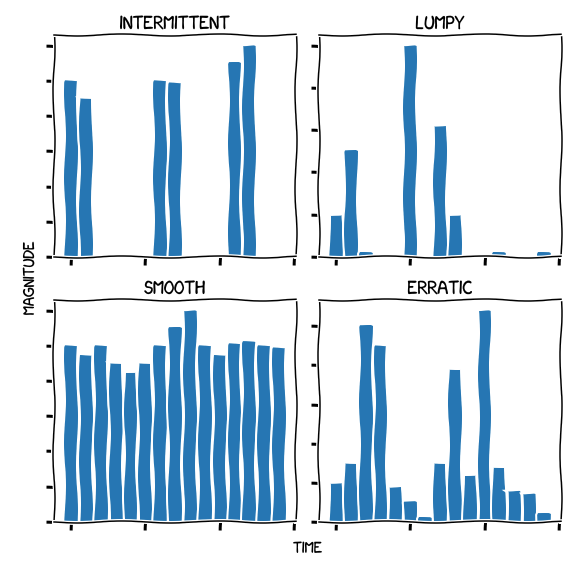
Smooth and intermittent demands are easier to model than lumpy and erratic. In particular, lumpy items are hard to model, because its demand shape is both erratic and irregular.
Instead of looking at the shape of each item's demand, we can calculate two magnitudes that will help us to classify all items at once:
- How spaced the sales are over time. Calculated as the mean inter-demand interval (p).
- A measure of how bumpy the sales are. Calculated as the squared coefficient of variation of demand sizes ().
Although we'll not dive into the details, we can use both values to perform a scatter plot of the items and cluster them into the four mentioned categories. This classification will also help us to define the level of aggregation of our data. In the following figures, we compare how the items are classified when aggregating the sales data daily and weekly.

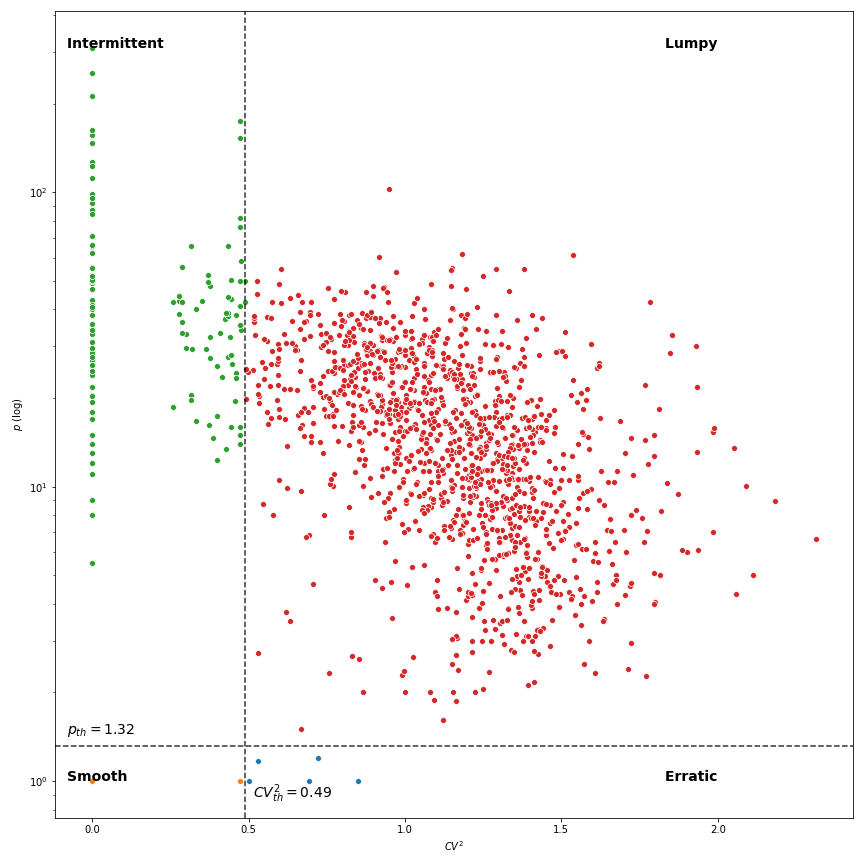
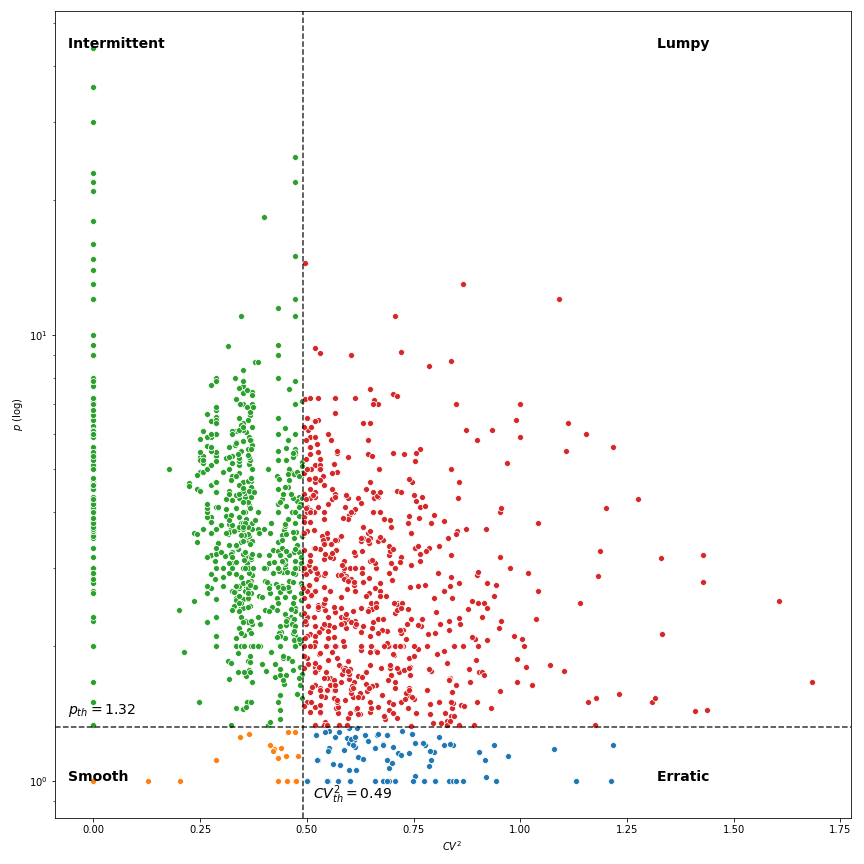
As you can see, a weekly aggregation of the data provides us a higher number of items to consider given our classification. This is also shown in the table below.
Items classification according to demand variability
| Category | Items weekly | Items weekly (%) | Items daily | Items daily (%) |
|---|---|---|---|---|
| Lumpy | 568 | 47,4 | 1.138 | 95,1 |
| Erratic | 57 | 4,8 | 0 | 0 |
| Smooth | 6 | 0,5 | 0 | 0 |
| Intermittent | 566 | 47,3 | 59 | 4,9 |
| Total | 1.197 | 100 | 1.197 | 100 |
We will aggregate our data by week and we will select those items that fall in the smooth, erratic, and intermittent categories (629 items), leaving out of the scope those with a lumpy demand (568 items) for which we should think of another level of aggregation.

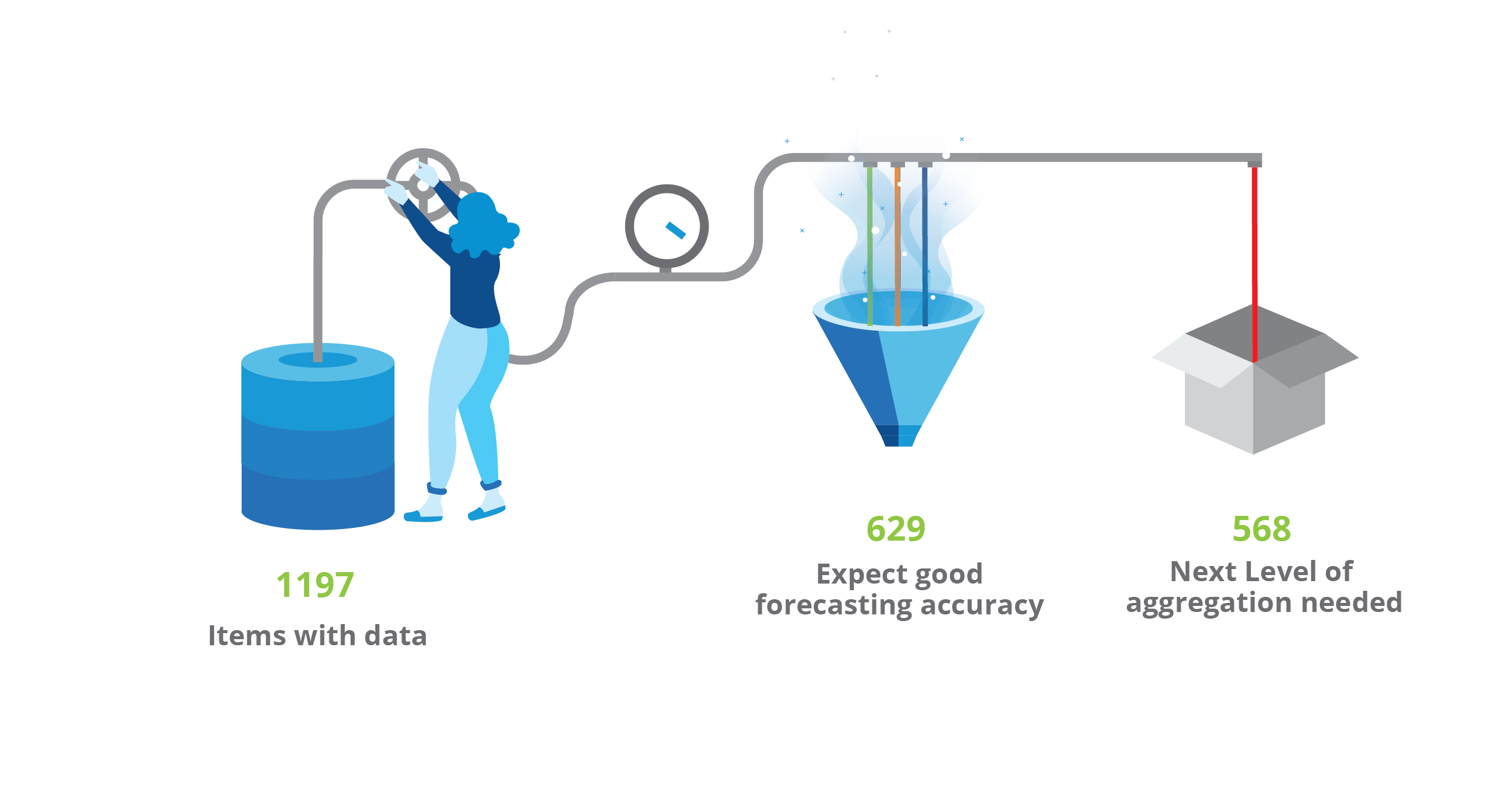
Number of price changes and timing
Another important aspect to consider for each one of the items is how many prices have been historically tried and during which period of time.
The more information we have about the demand changes relative to the price, the less the exploration efforts needed, as we will see later on.
These are the filters that we are considering for the Olist dataset:
- Have historically changed their price at least three times in the 2-year span
- Each of these prices has at least four days of sales.
With these constraints, we will be able to filter those items that have a significant amount of information. This allows us to estimate the demand curves within our historical sales, i.e., we want to select those items in which we have information about the sales behavior at different points in time, using different prices.
If we only filter by the number of price changes and timing specified in 1. and 2. the number of valid items is reduced to 144.
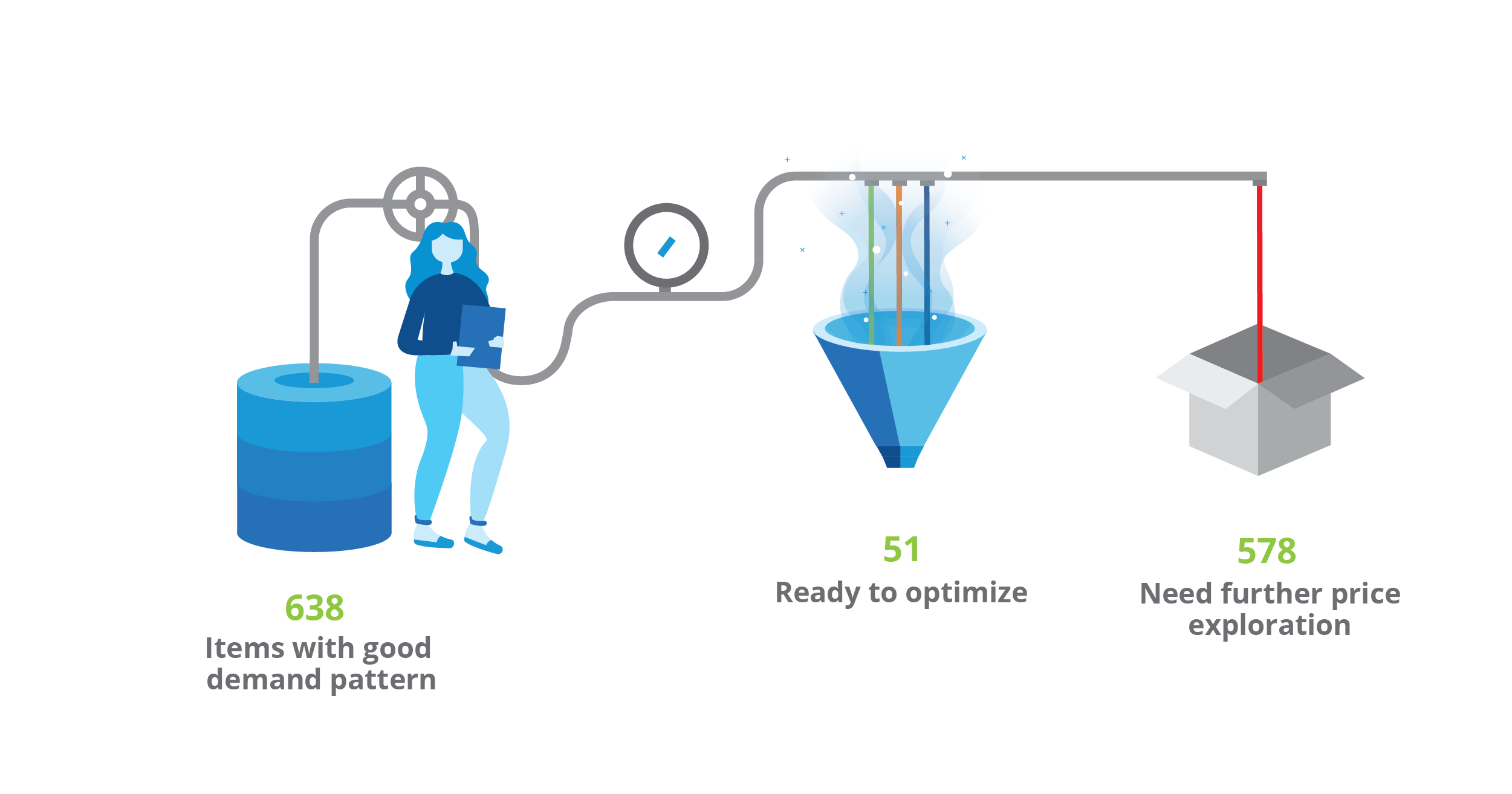
Items selection
We are now ready to join both conditions together —pattern shape of historical demand & the number of price changes and timing— to reach the final number of items that, without doing any other further experimentation, are ready to optimize. Taking both conditions into consideration, we reach a universe of 51 items that are ready to start.
As mentioned before, the rest of the items won't be discarded, but further price exploration will have to take place to generate meaningful datapoints. The price exploration strategy will be explained in the "Experimentation setup" section.
3. Anomaly detection
From our experience working with multiple datasets and several retailers, we have been able to develop an anomaly detection report. This report provides useful information to the data science team working with the dataset and provides meaningful insights to the business team. It has been of great help to identify missing information or misconceptions of the available data.
Anomaly detection involves identifying the differences, deviations, and exceptions from the norm in the data.
In a typical retail scenario, our anomaly detection report consists of three main topics:
- Identifying missing and inconsistent fields
- Detecting and handling out-of-stocks
- Observing sales distribution and detecting outliers
We will dig into the details of each one of these topics in the following sections.
1. Identify missing and inconsistent fields
1.1 Missing fields
Though there is a lot of meaningful information in the sales information of Olist, there are missing features that are essential to tackle our price optimization problem. For example, we don't have information about the manufacturer's suggested retail price (MSRP) of the items nor about its costs.
Let's say that we want to optimize our prices to maximize profit. Let's take a look then to the definition of the profit function:
Q represents the demand, p the price, and c the cost, and the sum is performed over our universe of items (N). As you can see, the cost is needed to calculate the profit, and so is to perform the optimization. If we don't have this information, we can assume a zero cost for the items, and then optimize our prices to maximize revenue instead of profit:
On the other hand, the MSRP can be used to compare the selling prices against the manufacturer's suggestion. It can be useful when analyzing each item's historical pricing strategy and its effects on the demand.
Also, we don't have much information about the items themselves. We lack information such as the item's description, images, name, sub-category, or brand, which are of great help to relate and cluster similar items. Nevertheless, as we will see, we can still get meaningful results.
1.2 Inconsistent fields
We can also run a series of inconsistency checks between the features. For example, if we have the sales data aggregated by date and not by order or basket, we can check if the "Total Sales" for a particular item/date is equal to the number of units sold times the price.
We would all expect this to be true, but what if:
- there have been refunds on that given date
- some units were sold with a privileged discount
- some customer paid with a different currency
We need to make sure that all of these details are correctly recorded, and if not, try to detect these anomalies automatically to take specific actions.
Moreover, many times retailers have business-specific rules which can be checked in a data-driven way to make sure they are being applied or not. Does any of the following business rules sound familiar to you?
- Prices for the same item must be consistent across stores
- No more than 40% discount from MSRP is allowed
- Sell price must always be lower than the competitor's price
- Different price promotions cannot overlap
With our anomaly detection report, you can specify the business rules, and we can check these quickly, easily, and automatically.
Going back to the Olist sample dataset, we don't have information about the MSRP, the cost of each item, or any specific business rule. However, we could still check for certain general inconsistent fields such as the following:
- Do we have negative values on sales units or prices?


- Is the same item sold at different prices on the same date?


2. Detecting and handling out-of-stocks
Another chapter in our anomaly detection report for retailers consists of detecting out-of-stock issues. This is very important because of two main reasons:
- Revenue loss: having out-of-stock issues implies losing sales and sometimes even clients. Therefore, pricing and inventory management decisions have to be taken jointly.
- Demand curve estimation: to correctly estimate a demand curve for each item/store, we need to identify the causes for which we observe zero sales for certain items in certain moments. In particular, we need to distinguish between zero demand and zero supply.
Ideally, we could incorporate inventory data and flag days as out-of-stock if the stock level for a specific item is equal to zero. Nevertheless, from our experience working with retailers, we have learned that inventory data is not necessarily 100% accurate. For example, in a brick-and-mortar store, we may observe zero sales for consecutive days, even when the inventory data suggests there should be five or even ten items in-store. Still, these items are not properly displayed to the public.
Therefore, we have designed different heuristics according to the client's data to correctly identify out-of-stock days and better estimate the demand curves. Some of these heuristics are complex and client-specific, while others are simple and straightforward.
As a preliminary approach, we can identify per item/store long gaps of zero sales and assume these are out-of-stock problems. This definition of out-of-stock will depend on the consecutive zeros threshold we define. For example, we can determine the consecutive zeros threshold as 30 days; this is to say that an item will be considered as out-of-stock if there are no sales in 30 consecutive days. We can visualize the out-of-stock periods as the shadowed area on the following plot:

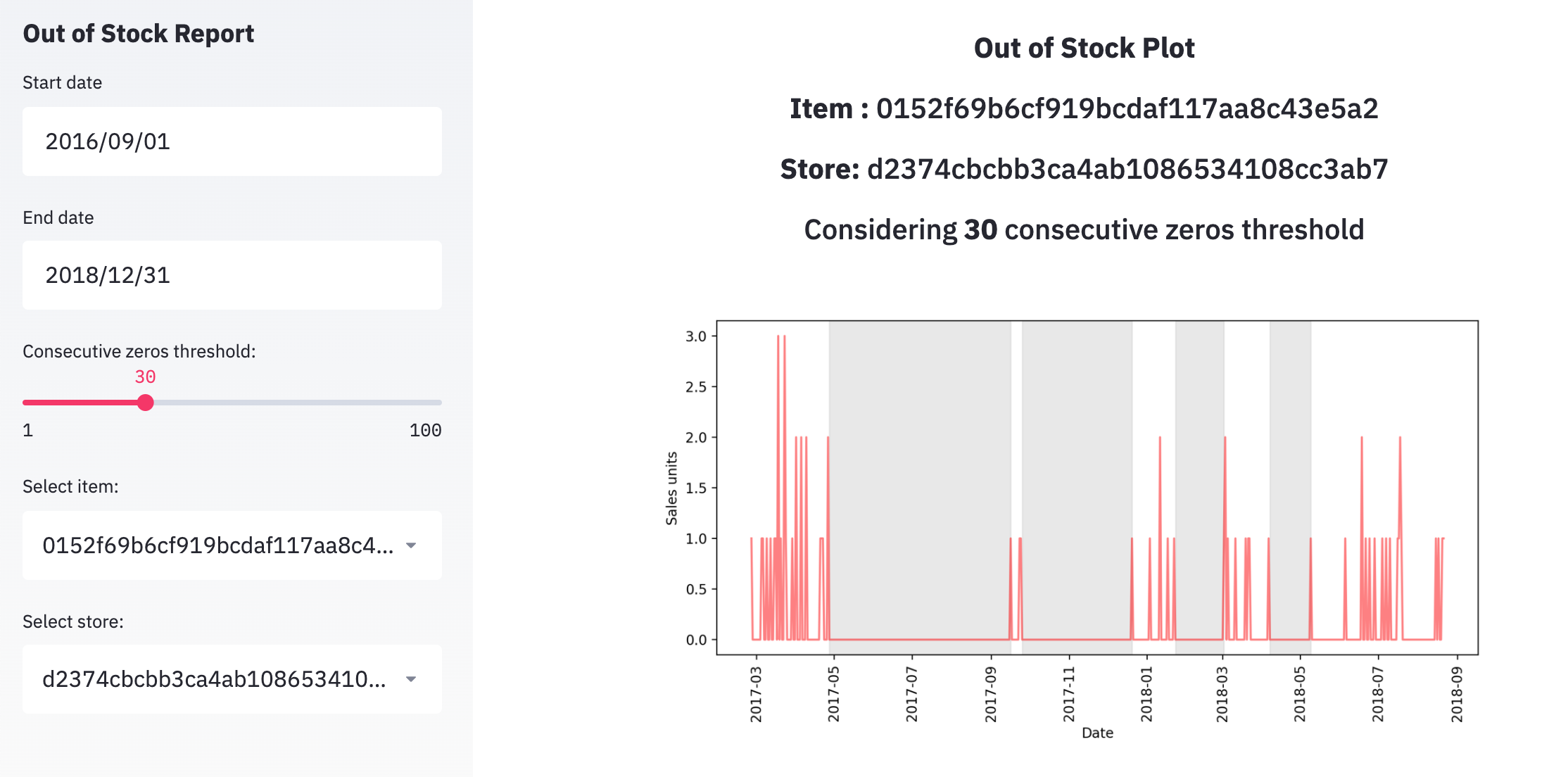
Given this definition, we can estimate the revenue lost as a consequence of out-of-stock problems, e.g., assuming that the sales during the out-of-stock periods would have been equal to an average date.
Furthermore, we could also download a report with the estimated revenue lost for each item/seller on each out-of-stock period. The Out-of-Stock Report would look something like this:

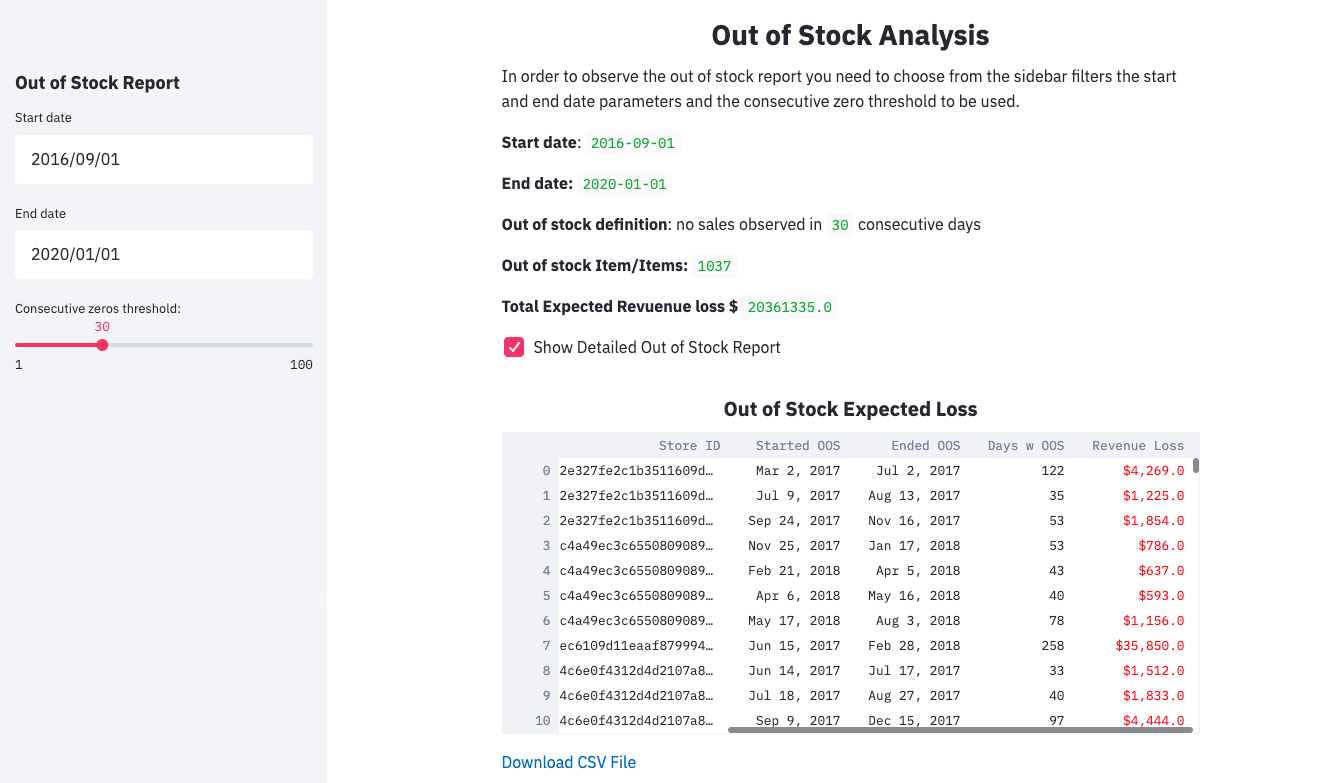
Even though this report gives us some insights into the impact that out-of-stocks is having on our revenue, these are just preliminary estimations. To better approximate the revenue loss and to identify the out-of-stock days better, we can use the same Machine Learning models we use to perform the forecast of the demands.
Let's picture this with an example. Imagine our Machine Learning model estimates that 53 units would've been sold of a specific item, on a particular date, given a certain price and conditions, and we observe that only 1 unit has been sold. This would raise an alert since it could be that a specific item has potentially run out-of-stock.
Finally, but not least important, once the Machine Learning models are trained, they can also be used in a proactive way instead of reactive. Several weeks in advance, we could estimate how many units will be sold and generate stock replenishment recommendations to avoid out-of-stock issues.
3. Observe sales distribution and detect outliers
To detect outliers, we can plot the daily sales distribution per seller or store by day of the week, month, or year. In particular, we can observe the distribution and detect outliers by generating different visualizations of the data.
For example, we can generate a boxplot to observe the distribution of units sold by day of the week. These plots are useful to understand how many units are sold on average, by a seller or store, per item on each category group.
As shown in the following figure, we can observe from the boxes sizes that, on average, all days have a similar behavior where most sellers per day sell only one unit per item. Nevertheless, there seem to be several outliers (dots that are far from the normal distribution). If we hover over the plot, for example, on the point which is farther away on the Friday category, we can see that it corresponds to a particular seller who sold 25 units for a specific item on Friday, 24th November 2017.

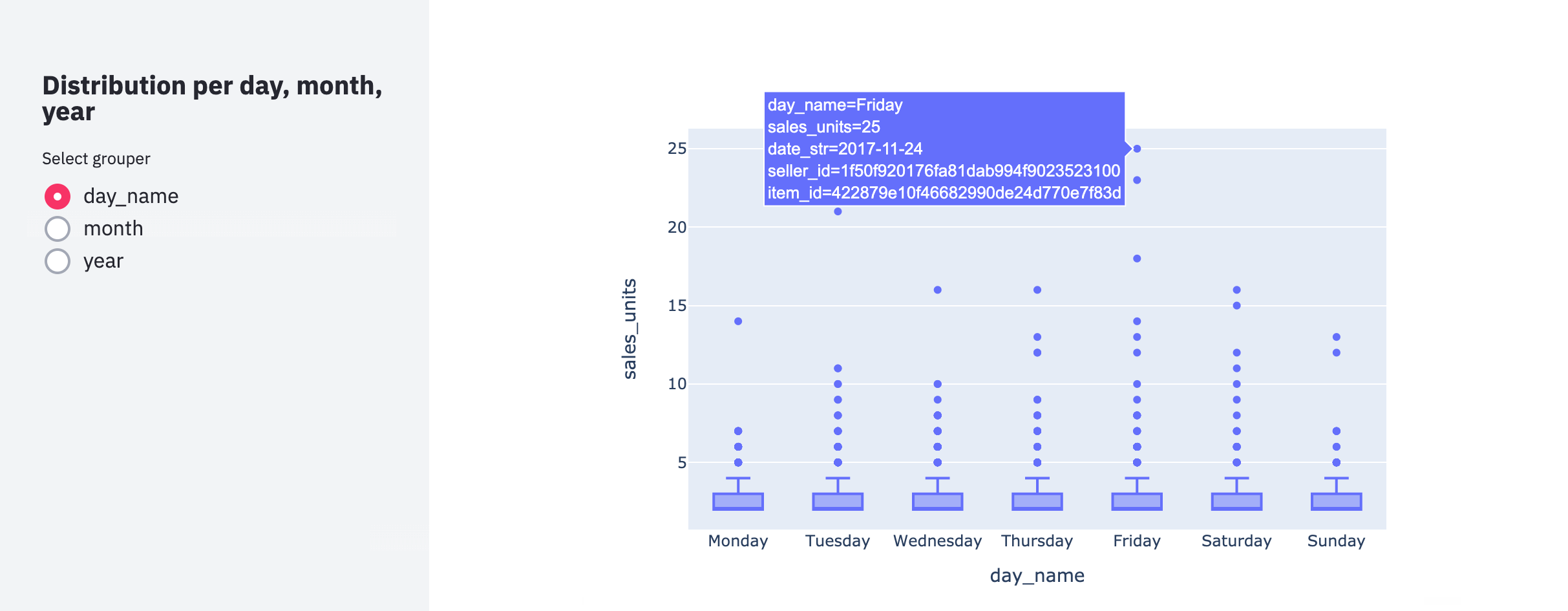
Does that date ring a bell to you? Why could you sell a totally different amount of units than what you usually sell? BINGO! That was Black Friday!
Even though we were considering national holidays as features for our demand estimation, from the data, we have learned that it may be relevant to include Black Friday as a special date.
However, we may also wonder what happened on Black Friday in other years? Was it also the date with the highest sales in 2018? Or what about Black Friday for other sellers? Did their sales increase dramatically too? By having a look at the boxplot by year, we can check what happened in 2018:

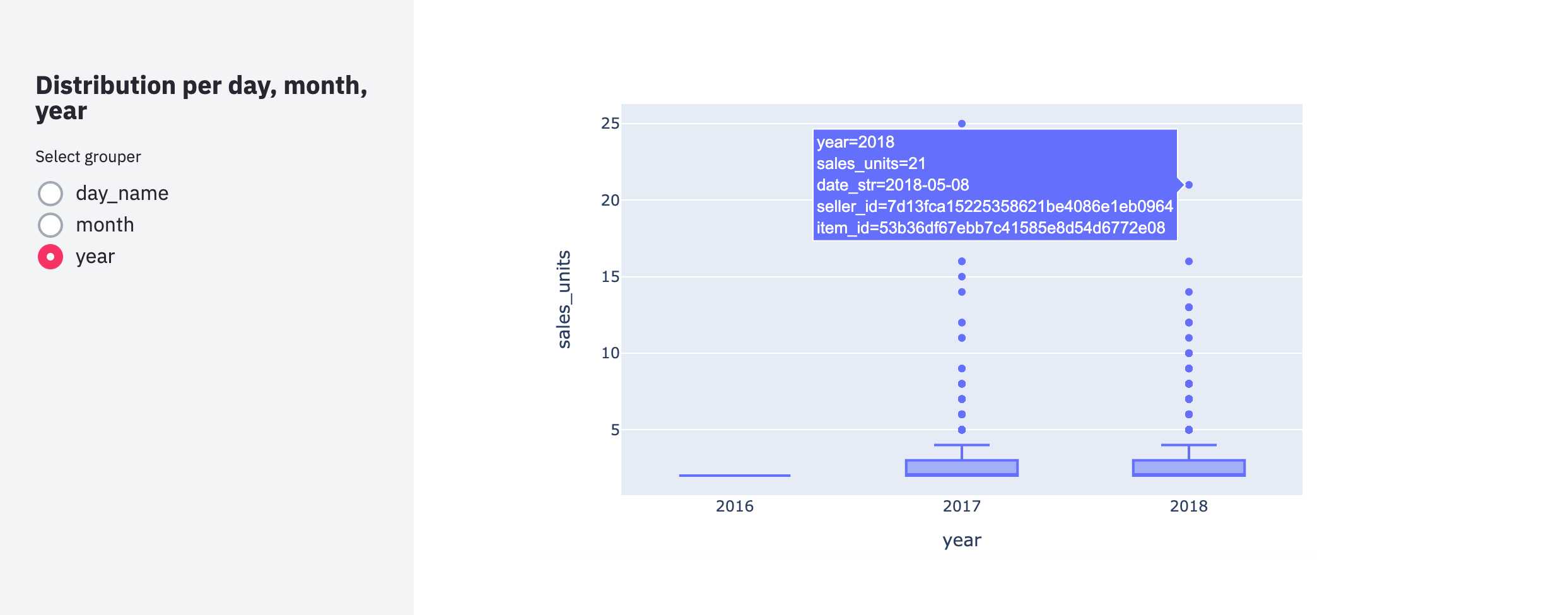
For 2016, we have almost no observations (data started in September 2016), but if we compare 2017 and 2018, the distribution seems very similar. Nevertheless, the seller who sold the maximum amount of units per item in 2018 was a different seller and did so on a different date. In particular, it was on May 8, 2018. What could have happened on that specific date?
When looking in detail at the list of holidays and events for Brazil in 2018, we can see that May 8 corresponds to the week before Sunday of Mother's Day (May 13). Also, this makes total sense when we see that the category of the item is marked as "watches gifts."
Taking consideration of holidays is important to detect and classify the outliers into different groups, i.e., those potentially related to errors in the data ingestion process —and that need to be treated as misleading— and those strictly associated with special events.
For sure, we need to continue exploring the data in order to gain more insights. We could, for example, observe the location for that particular outlier seller and check the sales distribution of the nearest stores to see whether it was one specific event that affected several stores or just this one. Or we could check if a sudden decrease in price can explain the increase in sales by plotting both variables together, as shown in the following plot.

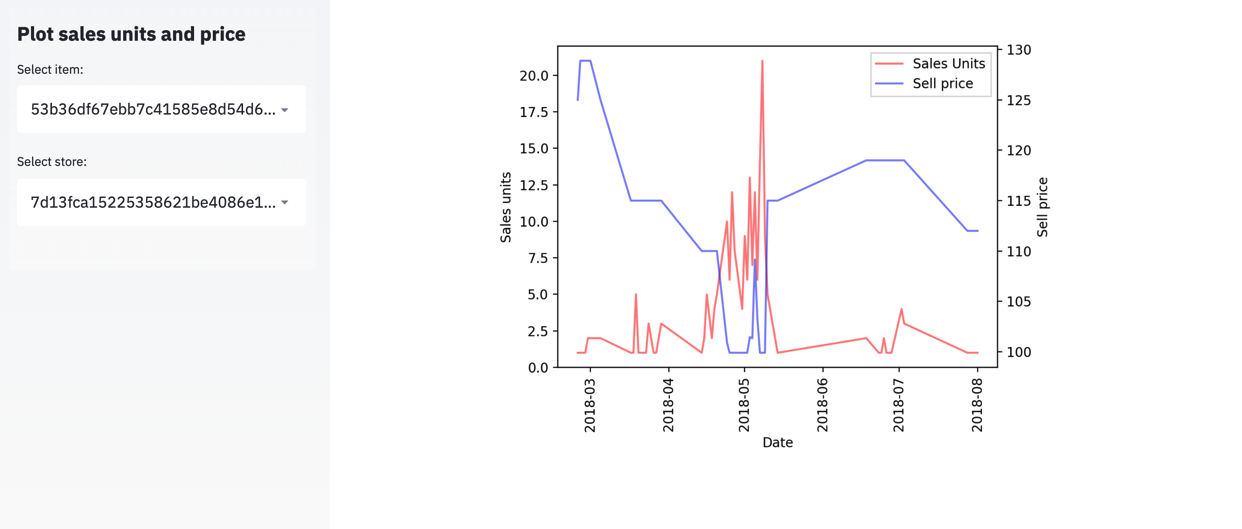
Following our intuition, this sudden increase in sales may be explained by a decrease in price. But we need to continue thinking of possible features that could help us better understand and explain the price elasticity of demand. This is where our Machine Learning models come into play. By including several different features, we can learn from the data which variables are mostly affecting the demand for each item. By modeling this particular item, we would have learned that it is not only the reduction in price that explained the increase in sales but also the days until Mother's Day, the day of the week, and several other variables.
Finally, it's important to stress the relevance of business expertise to help point out those relevant dates when you know sales go up or down. The Machine Learning models help you validate and test new hypotheses.
4. Modeling the demand
Having our data ready, we proceed to train the demand forecasting models. Our goal is to be able to build the demand curve for each item. The models will learn the relation between the demand and several factors such as the price, holidays/events, and macroeconomics.
During this phase, the collaboration with the business team is particularly important. Business insights help to validate the selected features and ensures that we are not missing any important aspect that can be potentially used to forecast the demand.
Below we show an example of the demand curve for an item in the garden tools category.

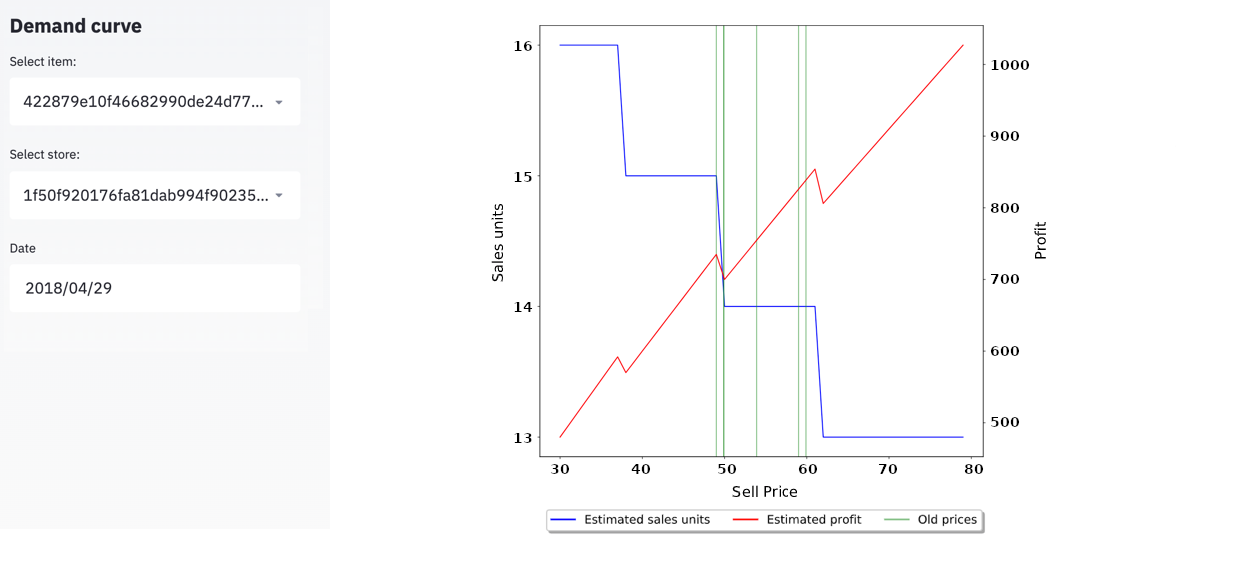
This plot shows the predicted demand curve (blue line) for a particular date (April 29, 2018). The vertical green lines are the historically tested prices (from where our model learned the price elasticity). The red line shows the expected profit (assuming item cost equal to zero, as we don't have this information).
What insights do we get from the estimated demand curve? In this case, we can see that between $50 and $60, the number of units sold would be equal to 14, meaning that in this particular price range and week, the demand curve is completely inelastic. Nevertheless, if we increase the price somewhere close to $63, the number of units sold will decrease, one unit less will be sold but still obtain higher revenue. According to our model estimations, without having a retailer and business background, we would recommend starting with a price between $63 and $70 to explore how the demand behaves on this point.
Once we have information about the demand using this price, we can use the latest information to feed the model and then decide which is the following price to set. The advantage of trying prices far from the historically tested ones would be that we may find a new optimum price (exploring). Still, trying prices that have never been tested before brings more uncertainty as the accuracy of the model in those regions is lower.
Moreover, explainability is a desired feature of the models in price optimization. Most of the time, it provides new business insights to retailers and validates that the model is learning correctly. Our models can tell us which features were the most relevant to fit the data. Below we show the top-10 feature importance for the model associated with our garden tool item.
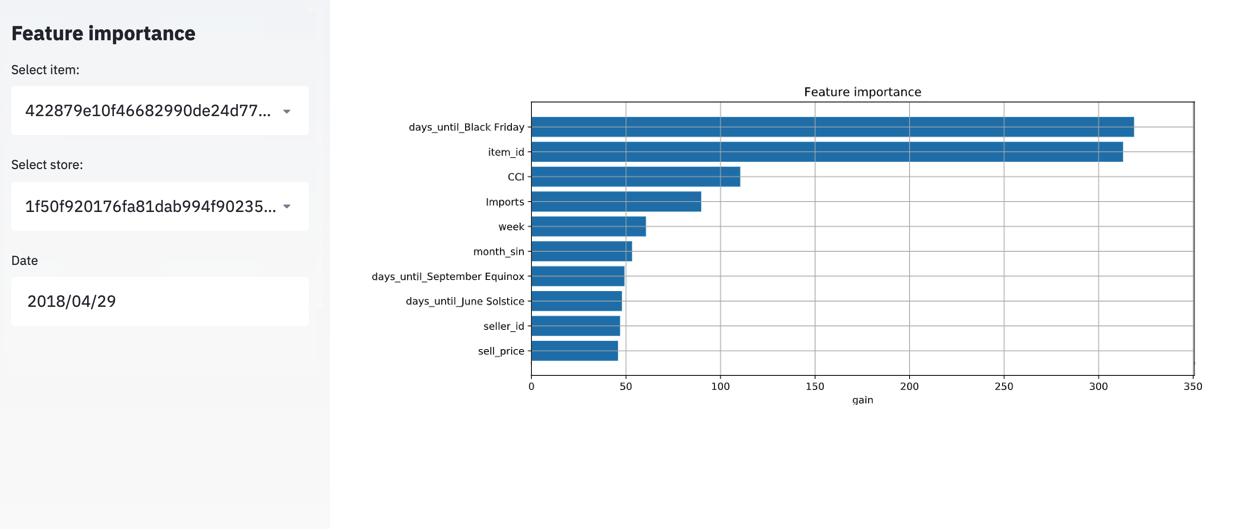
The most important features according to the model are:
- Days until Black Friday
- Item ID
- Consumer Confidence Index
- Total imports in USD
- Week number of the year
- Month number of the year
- Days until Spring
- Days until Winter
- Seller ID
- Sell price
As you can see, Black Friday is the most important event for this retailer. This means that each time the feature was used, the model achieves a greater increase in its accuracy. Also, the Consumer Confidence Index (CCI) and the total imports in USD (Imports) are the most relevant macroeconomic factors for this particular item. Furthermore, the beginning of Winter and Spring seasons also play an important role in explaining the demand for our garden tool item.
5. Experimental setup
Once we have our demand curves, we need to decide what exact prices we will try. This is to say, we have to plan what concrete actions we will take, and these actions or strategies will depend on our experimental setup. Three main questions need to be answered to define the experimental setup:
1. How are we going to measure the profit gain for the business as usual?
We need to define a measure against which we will be compared in order to evaluate the progress of our pricing system. We can have different options here, for example:
Control store: we can start by comparing our store's performance against a control one, that will keep using the same business-as-usual pricing strategy. This scenario usually applies to brick-and-mortar stores.
Synthetic control: when we lack a reference or control metric to compare against, we can synthesize one using other available metrics. This is known as synthetic control and provides us a way to measure the profit gain with respect to the business-as-usual even when there is no clear control measure. This method can be used for both e-commerce and brick-and-mortar retail companies.
2. Which price change frequency is best suited in my case?
We need to define the frequency of the price changes, that is if we are going to change the prices hourly, daily, weekly, etc. This will depend on two major factors:
Is your business Brick-and-mortar or e-commerce?
Brick-and-mortar stores, due to the operational limitations of physically changing price tags, usually use weekly or bi-weekly frequencies.
Some of these companies use digital price tags that remove this limitation and let them change prices more frequently. However, if the frequency is too high, customers may feel that the prices in the store are unfair, so this should be taken cautiously.
On the other hand, e-commerce retailers usually select their prices more dynamically, changing prices in the hour-daily range. Often, customers are more likely to accept these higher pricing frequencies since they see this behavior in big players like Amazon.
How accurate are our models for each price change frequency?
The other major factor to consider is the ability of the models to accurately predict the sales units in different time windows. This will depend on various factors, such as the shapes of the demands and the amount of historically price changes, as we discussed in the previous section.
So as a general rule, we should choose the frequency in which our models are accurate enough to perform the predictions, and that maximizes our objective function (e.g., profit) while remaining operationally viable.
3. What will be the Exploration vs. Exploitation strategy.
During exploration, we try new unseen prices that will add crucial information to the data about the shape of the demand curve. On the other hand, during exploitation, we exploit the information that we already know from the demand curves and try to maximize our objective function.
Different strategies can be applied depending on the necessities of the retailer and the quality of the data regarding historical prices. In the Olist dataset, we have 51 items ready to start exploitation. The rest of the items have very few prices tried or very few historical sales and will require some level of exploration.
Here below, we list some recommendations that are useful when defining the exploration strategy:
- If we count on the MSRP, start at this price, and make variations around this price to see how the demand behaves.
- If not, start setting a price near the ones that have been historically tried and make variations around this price to see how the demand behaves.
- With the business team, set a reasonable threshold to the upper and lower boundaries of the exploration price range.
6. Optimization
Once all these questions have been answered, you have everything set to optimize your pricing strategy, as many other retailers are already doing.
Optimizing your pricing strategy means defining your function to be maximized and consider any restrictions to include as constraints. In most scenarios, the objective function to be maximized will be the overall profit subject to the stock level or sales velocity preferred. However, you may be willing to maximize sales volume or customer’s lifetime value. The definition of the optimization problem must be clearly defined with the client.
All in all, we show the opportunity summary report that showcases several promising lines of work.
Opportunity summary report
| Solution | Opportunity | Details |
|---|---|---|
| Price optimization | High | +50 items ready to optimize / +1,000 items for exploration |
| Inventory management | High | +1,000 items run out-of-stock |
| Price automation | High | +20,000 unique items sold |
Final thoughts and concluding remarks
We have shown how a typical price optimization pipeline would look like, and how we would asses the potential opportunities for a pricing model.
In this particular example, working with the publicly available sales data of the Brazilian marketplace Olist and with no further information nor insights from their side, we have shown that there is room for improvement regarding their pricing decisions.
Combining their available dataset and other publicly available information, such as holidays/events data and macroeconomic series, we have been able to estimate demand curves for a subset of the items which would allow them to take optimal pricing decisions. The remaining items should undergo an exploration phase where new prices would be tried in order to be able to estimate their demand curves accurately. The exploration strategy is generally decided jointly with the client.
For this example, given the data available and our past experience, we would suggest performing weekly price changes during the exploration phase. Furthermore, we have shown that there is plenty of room for inventory management improvement since there seems to be an important amount of revenue lost due to understock.
Finally, during this analysis, we have focused on working with items that have been sold several times during the two years time span. Nevertheless, it is essential to note that there are thousands of items that have been sold only once. For those items, we could think of a price automation solution that could also help your company boost its profit.
In summary, we have shown that price optimization results are immediate and disruptive for companies using traditional pricing. We have also demonstrated that demand forecasting can also be used in other areas of operations, including assortment optimization, marketing, and inventory planning. In other words, investing in a good demand forecasting system opens the door for new opportunities that can be developed component by component based on business priorities.
We can show you how this works, and help you find the opportunities you may be missing.
Get the latest news about price optimization
Subscribe to our pricing with ML newsletter.

Wondering how AI
can help you?

Terms and Conditions | © 2026. All rights reserved.