

Can you beat this pricing algorithm?



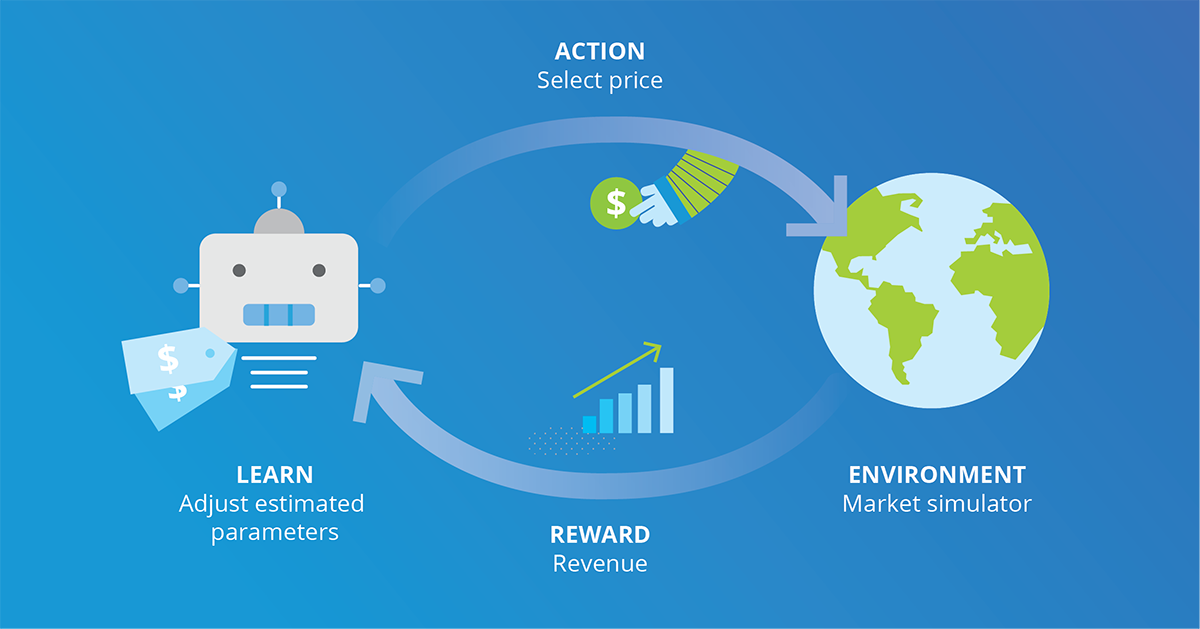
Deciding on the best price for a product or service you're providing, in order to maximize business profit, is not a trivial problem, not at all. Actually, it's always ongoing, since you can never tell if the price you chose is better than others you didn't. Even if you try other prices, market conditions may change, as they frequently do. Consider things like the client's buying capacity, new competitors, marketing campaigns, regulations, a tweet from an influencer or a viral trend out of control, and so on!
Basically, you can only estimate, to the best of your ability, and be ready to learn from the experience. Oh, and you had better be an excellent and quick learner.
Here at Tryolabs, we don't run a supermarket (we're actually a software company), but we are interested in examining our pricing abilities using machine learning and testing ourselves. So, how best to do this? Well, we built a small game, which you can also use to challenge yourself.
Spoiler alert: it's really hard to beat your competition, the machine. And even if you do beat it, consider that pricing algorithms can deal with any number of products at the same time.
TL;DR: Playing the game is no small matter, but if you just want to see what we're talking about...
So, what's the game about?

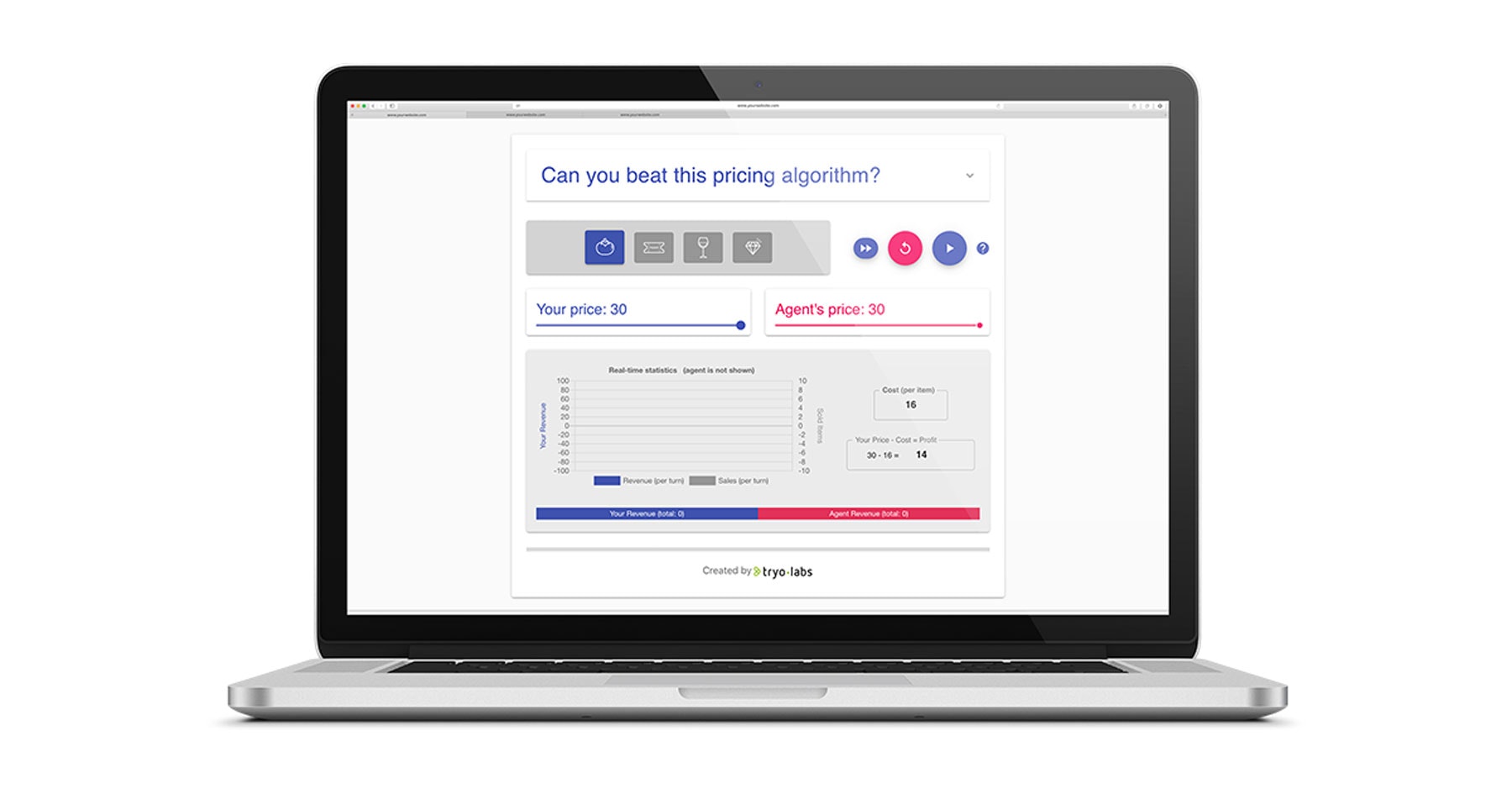
Essentially, it’s a market simulator. You play against our automatic pricing agent. Both of you will be selling a product at a specific starting price that you adjust throughout the game according to how well the product sells at each price level. Both players are independent, in the sense that they don't interfere with each other's product demand.
How many units of the product will you sell in the market? Well, it depends on how you price it. Inflate your price and you'll probably end up selling a lower quantity of the item, though you’ll make higher margins. Be a good samaritan and sell it at a very economical price and you'll be quite popular, though you won’t profit much per unit sold.
However, it's not always like that.
In this particular case, we're describing the following demand curve:

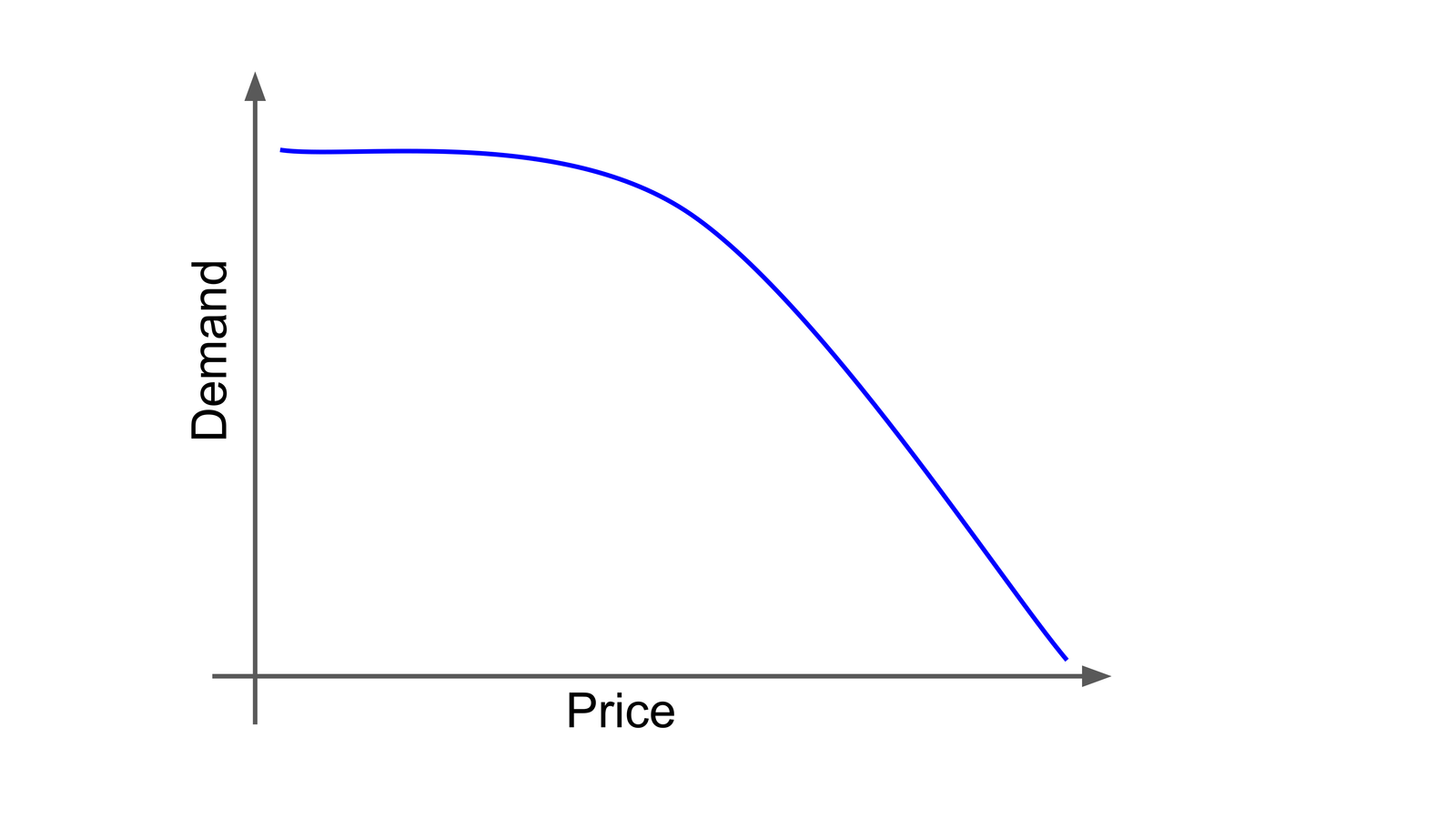
(*) This demand curve is based on a study of the onion market in India (Deblina Chatterjee, 2016), but it could apply to most vegetables and fruits. The flattening of demand when the price drops below a certain point, which breaks the "cheaper price, higher demand" relationship, is because the market needs for the item saturates at certain point.
This particular curve is specific to onions. There are many case studies that suggest utilizing different curves for other kinds of products and services. We wanted to see what would happen under as many scenarios as possible. By testing multiple hypothetical cases, it’s possible to evaluate the robustness of our automatic pricing algorithm.
The game incorporates a demand curve like the one above, as well as others that may apply to different products or services. Of course they're not true to life or quantitatively accurate (is that even possible to simulate?), but intended only to challenge you and our algorithm to identify the best price with unpredictable conditions.
This approach is called dynamic price optimization. Why “dynamic”? Well, now it's time to mention that the curve can move up and down during the game, simulating the “seasonality” that many products are subject to. Few people will be looking for sunscreen when winter is coming (they had better look for some dragonglass).
What the game is NOT about
There are countless situations a retailer must address on a daily basis that go far beyond maximizing profit. Price low and you'll increase your sales volume, but can you keep up with production demands? Price high and you'll increase your unit margin, but do you have enough space in the warehouse to store the goods until the right customer comes along?
Production and warehouse limitations are just two examples of restrictive variables that need to be taken into account to successfully run a business and, depending on the types of products being sold, there could be many more. For example, perhaps you are selling perishable goods or seasonal products. Or, you may need to stock up on merchandise months before selling it, making predictions as to how many items you will sell to avoid running out of stock or, conversely, having to apply discounts to sell the remaining items.
None of these challenges arise in our game, but this doesn't mean they can’t be taken into account by an automated solution; it simply means we decided to narrow down our market simulation to avoid giving birth to Skynet. Machine learning is all about using data to make better decisions, so if you have the data prepared, there are a lot of things you can do with it in order to optimize prices!
Tips to play
Before you play, understand this:
- You and our agent are faced with the exact same demand curve.
- The demand curve has a clearly-defined shape but unknown values outside of the market simulator.
- The number of items sold is randomized, but related to the price you select (i.e: where is your price along the demand curve?).
- Neither you nor the agent will have any additional information. Both of you will have to try out prices and see how the market responds.
We promise, our agent doesn't have access to the demand curve information that the game relies upon to simulate the market. It will have to estimate the best price by looking at sales, just like you.
Things to keep track of while playing:
- Your revenue plot (the blue line; if it goes up, the price is better).
- Unit cost. Careful! It changes throughout the game and you may end up with negative revenue (aka, losses) if your current price is lower than the cost.
- The game has “seasonality” built in: the shape of the demand curve doesn't change, but it moves up and down during the game, and that may impact the optimal price.
- You vs. agent bar: it displays accumulated revenue up to that turn. The player with the longest bar by the end of the game wins.
After the game finishes…
You’ll be able to review the game history once it’s over. This includes the revenue that you and the agent earned, and the prices you selected at each turn.
We've also added the “optimal” price and revenue plots in there. These are calculated throughout the game using demand curve information along the way.
As proof that we're not cheating here, you'll see that our agent's price doesn't always match the optimal price (because, like you, it doesn't have any inside knowledge about the demand curve; it learns from experience), and you'll see that if you selected the same price that our agent did, the revenue plots reveal the same expected value.
Dilemma: exploration vs. exploitation
Yeah, we know. You lost because you were curious about a price, then you moved the slider and almost went bankrupt. Or, you found the sweet spot and stuck tightly to it, but doing that could have led to missed opportunities that might have changed your life. Don't worry, it's just a game. But, it’s a known issue out in the real world: you need to test different scenarios before you conclude that something won’t work out the way you thought.
Well, reinforcement learning [RL] agents don't dream of their dreams coming true (or do they?), but they are definitely required to take situationally-dependent actions, and they face the same dilemma described above, which is known in the field as the title of this section, exploration vs. exploitation.
Reinforcement learning agents (and people) must explore in order to be able to estimate possible outcomes well. Once they've found a rewarding action, they should try to exploit it. Does that mean it’s a good idea to always repeat the same action?
Well, in an ideal world where nothing ever changes (we're not that conservative, but whatever), that may be the best choice based on a good estimate of the expected reward. But we don’t live in an immutable world, so we need to keep exploring different possibilities to sharpen our estimates and make the best decisions. Otherwise, we’ll become obsolete, or lose the game when the product cost or demand curve changes, in the current context.
Reinforcement what?
To be fair, we started talking about reinforcement learning without providing an introduction.
It's an extensive field presently on the bleeding edge of artificial intelligence research. It's basically about designing agents that learn from experience by executing actions and internalizing the corresponding feedback (positive/negative rewards), sort of like dogs do when being trained.
After a certain amount of experience, the actions determined to be more rewarding (short term or long term, there's another tradeoff there) tend to be repeated (reinforced). In the example of the dog, that's when you'll finally get it to do his deeds outside.

In the game, each step requires that we take specific action, that being price selection, and the reward is the immediate revenue we earn, which we want to maximize throughout the game. The market is the agent’s external environment and is relevant to the development of each move (it reacts to the price selection action and is the source of the reward),
All of these concepts, central to reinforcement learning theory, can be further explored within the context of this game, and that's why we primarily decided to write this blog post combining dynamic pricing with reinforcement learning. We don't want to get too technical here, with the exception of the below section Going technical. But don’t worry, it's short.
Maybe one day we'll put together a more technical blog post about how the agent works (the more interest you show, the more likely that’ll be ;-)).
How greedy are you?
Remember the exploration/exploitation dilemma? Well, when an agent sticks to the estimate with the best results and doesn't frequently explore other available options, it is said to be “greedy” for only exploiting the best-known option. That reality gives name to one of the simplest algorithms: Epsilon-Greedy.
You don’t need to fear the word “epsilon”, but rather learn one powerful thing: when an engineer or scientist talks about a small number approaching zero but not reaching it — with an exact value that is not known — they refer to it as “epsilon”.
An Epsilon-Greedy algorithm will select the best action almost all of the time (greedy), except when there is a certain “epsilon” probability, in which case it selects a random action so as to keep exploring a bit. It does this in order to adapt to eventual changes or achieve a better estimate.
Going technical...
The Epsilon-Greedy algorithm is not the most intelligent way to explore the possibilities. Why would we want to select a random action when we're not being 100% greedy? If there's another option that is only slightly worse than the optimal one, we should try to perform that action more often.
On the other hand, if there's an option where choosing it always results in us losing, it seems wise to begin avoiding that option at all costs.
Between these two extremes, there must exist other options that haven’t been sampled enough times to establish the mean value. Therefore, we should assess them further to become more certain.
In the game, we employed several algorithms that deal with this issue in intelligent ways, but the best solution depends to a great extent on the problem’s specific characteristics (e.g. how fast does the environment change? And, what information can we use to improve our estimates?).
We’d like to mention a few algorithms we employed with respect to the case of the multi-armed bandits problem (you might already know something about this). We started with Epsilon-Greedy and compared it to UCB (several approaches), the log-derivative trick (aka reinforce trick), and other variations of them that we tweaked, some of which make assumptions about the shape of the demand curve (yes, some of which are even specifically designed for price optimization).


After reading through various research papers and completing a couple iterations of the implementation, we ended up with a detailed understanding of each algorithm and a clear picture of the challenges that this particular problem presents.
How we implemented our agent
The first thing to note is that our agent runs in the browser and only learns during the game. Therefore, we're not dealing with agent states, and we’re limiting our solution to the solving of a variant of the multi-armed bandits problem.
Many of the algorithms described above performed well after some tweaking. However, in the end we designed an agent inspired by the reinforce-trick and Epsilon-Greedy, which use the decoupled sales quantity and profit margin (instead of looking directly at revenue), so as to be able to make best use of all the available information.
We refer to our new algorithm as “Softmax-Greedy”, since we maintain and update our sales at each price point in the same way that Epsilon-Greedy does, but then take actions with a high probability of success as related to the expected revenue, using a Softmax function. This is similar to the way it's done with the reinforce-trick.
With this algorithm, we accumulated revenue above a certain threshold that was 90% of the optimal price, which is a great result considering that the agent doesn't know the shape of the demand curve nor its seasonality parameters, and it plays possessing the same information that the human player has access to: selected price (of course), product cost, and number of sales at each stage. In addition, it does so without information about the specific product it is selling, so it could be applied to virtually any product and all of them at the same time.
What's next?
The whole idea behind the game was to create a kind of playground to test simple reinforcement learning algorithms for pricing in a fun and intuitive way, while also gaining first-hand insight into how these algorithms compare with a human making the same decisions in the most basic case of a single product. All this within a very simplistic environment.
In our line of work, we’ve already had contact with tackling real pricing issues on some of our projects, and we realize that real world complexity is not even close to being approximated by this game (as mentioned in What the game is NOT about). It just represents a starting point for reviewing some general concepts.
Do you want to learn more about pricing with machine learning algorithms? Dig a little deeper by having a look at these posts:
- 5 actionable steps to get your data ready for price optimization with machine learning
- How machine learning is reshaping price optimization
We hope you find them interesting!

Wondering how AI
can help you?

Terms and Conditions | © 2026. All rights reserved.