

From DALL·E to Stable Diffusion: how do text-to-image generation models work?


The machine learning community lost its mind when OpenAI released DALL·E in early 2021. Previous years had seen a lot of progress in models that could generate increasingly better (and more realistic) images given a written caption, but with an unprecedented level of range and flexibility in the content and style of the images it could generate, DALL·E was the pinnacle of what one could expect from a text-to-image generation model… One year later, DALL·E is but a distant memory, and a new breed of generative models has absolutely shattered the state-of-the-art of image generation.





So what’s changed? We at Tryolabs are in full awareness that one year in Machine Learning research is equivalent to about a decade in other fields — but even for us, this is a massive leap in performance for such a short period. The answer isn’t hard to come by when analyzing the similarities between the latest models: a completely novel approach to text-to-image generation through the use of diffusion models has surfaced — and it’s here to stay.
If you haven’t been living under a rock for the last couple of months, the names DALL·E 2, Imagen, and Stable Diffusion should ring a bell. Each generated a new weeks-long wave of Twitter threads, discussing architectural details and showcasing results that escaped the very boundaries of the AI communities that managed to create them.
In this blog post, we will take a peek at how diffusion works for generating images, explain exactly where the differences between these three models lie, and analyze what real-world tasks these models might aid companies and individuals with in the long run. Don’t hesitate to read along if math isn’t your strongest suit — we’ll make sure to keep it to a minimum!
The DALL·E way
To better understand what has changed, let’s first dive into how OpenAI’s original DALL·E worked.
Released in January 2021 and following the release of GPT-3 a few months earlier, DALL·E made use of a Transformer, a deep learning architecture that surfaced in 2017 and has since then been the de facto choice for text encoding and processing sequential input, and a variational autoencoder (VAE), a model trained to encode an image into a low-dimensional probability distribution and then decode it off of it, that can be used for generating new images by sampling from the intermediate distribution and passing that through the decoder.
The Transformer was trained autoregressively (i.e., making it try to predict future values based on past ones) on the concatenation of a sequence of text tokens and a sequence of image tokens, the second of which were obtained with the VAE trained beforehand. During sampling, the Transformer is given the whole text prompt and generates each token in the image sequentially, to be later decoded by the VAE to obtain the full output image.
At the time of its release, DALL·E showed truly mind-blowing results — besides having some limitations, the most blatant of them being the trouble it had when trying to generate photorealistic images instead of cartoonish/artistic-looking ones.

2021 went by without much news in the image generation space, except for a single paper out of OpenAI titled GLIDE. GLIDE, which admittedly flew under our radar at the time, proposed using diffusion models for the problem of text-conditional image synthesis, guiding the diffusion process towards whatever researchers wanted the final image to look like. This approach, or variants of it, was then used by DALL·E 2, Imagen and Stable Diffusion in their respective models. Before diving into how this guidance works, let’s do a quick recap on what diffusion models are.
How does diffusion work?
Diffusion models are generative models able to synthesize high-quality images from a latent variable. Wait, isn’t that what GANs do? GANs and diffusion models (and VAEs and flow-based models, while we’re at it) are similar in that they pretend to produce an image from randomness — but different in every other way.
The GAN approach has been the standard for generating images for several years now, especially when needing to generate images belonging to a tight distribution, such as faces of people or breeds of dogs. We have written about GANs in the past, but in a nutshell, their training consists of spawning two models, called the generator and the discriminator, and having the generator try to generate image samples that trick the discriminator into thinking they come from the real data distribution being trained with. Although the paradigm of having two models train each other is quite amusing, GANs are also famous for being especially hard to train, with generators that straight up don’t learn or fall into mode collapse (i.e. that learn to generate the same image every time) being extremely common. For the interested reader, there are some hints as to why this is in this Twitter thread.
On the other hand, diffusion models consist of generating a chain of increasingly-noisy images by gradually adding Gaussian noise to an image, and then training a model to predict the noise that was added to the image from one step to the following one. If the steps are small enough, one can ensure that the image obtained at the end of the sequence can be approximated by the same Gaussian the noise is being sampled with — which allows us to generate a completely new image by sampling from that same distribution and then passing it times through our trained model. We won’t get into the math behind them here, but we recommend checking out Lilian Weng’s blog post if that’s your jam!


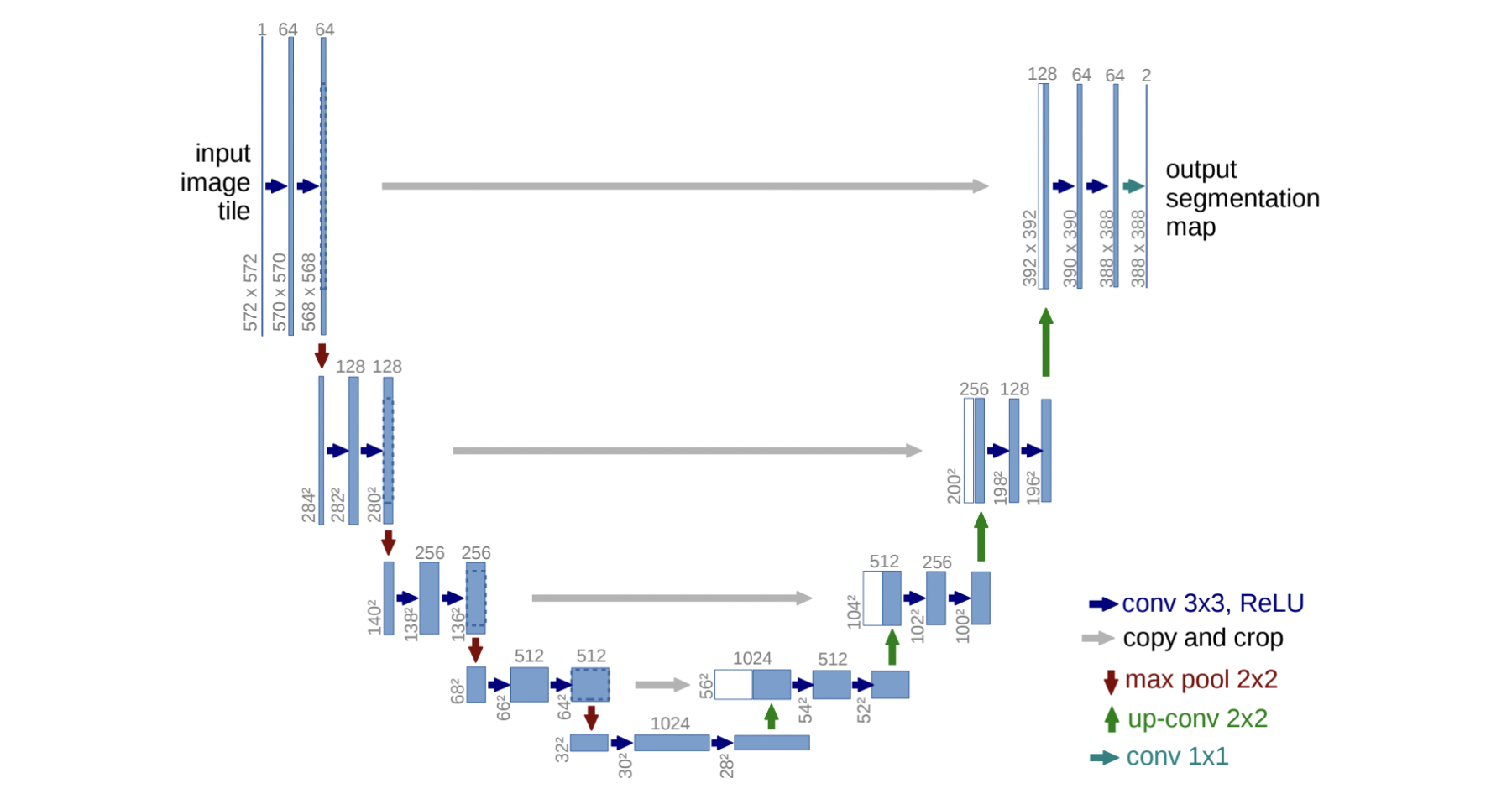
Not only do all the approaches we will dive into in this post use diffusion, but they also all use variants of the same model to predict the noise added to the image in each step of the chain: a U-Net. Surfaced in 2015 and initially proposed as a new way to tackle the problem of biomedical image segmentation, U-Nets possess the characteristic of having the same input and output shapes, which makes them ideal for inputting an image and obtaining how much noise was added to each of its pixels. They consist of a stack of residual layers and downsampling convolutions followed by a stack of residual layers with upsampling convolutions, with skip connections linking the layers with the same spatial size in the two symmetric halves of the network. The contracting path allows for capturing the general context of the input image, while the skip connections provide the upsampling layers with the detailed information needed at each step.

How can we guide the diffusion process?
We’ve learned how diffusion can help us to generate an image from random noise, but if that were as much as there was to it we would end up with a model that is only able to generate random images. How can we make use of this model to synthesize images that correspond with a class name in our training data, a piece of text, or another image? This is where GLIDE, the paper we mentioned earlier, comes in. It builds on two important concepts proposed by papers that precede it:
- Conditioned diffusion, which comprises feeding conditioning data (such as a class label or a text embedding) to the diffusion model through its input layer and through attention at its inner layers, to aid it in producing a sample that corresponds to that data.
- Classifier guidance, which consists of adding the gradient with respect to a target class predicted by a classifier to the noise predicted by the diffusion model, thus forcing the diffusion process towards the expected class in every step of the way.
GLIDE proposes two novel ways of guiding a diffusion model towards a caption of our liking:
- CLIP guidance works in a very similar way to classifier guidance except it sums the gradient with respect to the CLIP loss between the partially-generated image and the caption (which measures how much the two correspond with each other — if you don’t know how CLIP works, we strongly recommend checking it out in OpenAI’s blog!)
- Classifier-free guidance works by training a conditioned model but with the caption being dropped randomly during training (thus obtaining a model that can work both conditioned and unconditioned), and during inference passing the image through the model both with and without a conditioning caption, taking the difference between the two and extrapolating the final prediction towards the direction of the conditioned prediction.
Note that a diffusion model can use both conditioning and guidance at the same time, and the authors found that a combo of text conditioning plus classifier-free guidance worked best in their experiments, both in terms of photorealism and caption similarity.
DALL·E 2
Good news — if you followed this far and understood how guided diffusion works, you already know how DALL·E 2, Imagen, and Stable Diffusion work! Each of these uses conditioned diffusion models to attain the mind-shattering results we’ve grown accustomed to. The devil’s in the details though, so let’s dive into what makes each approach unique.
Released by OpenAI in April 2022, a little more than a year after its predecessor, this model should be called GLIDE 2 by the looks of it — but that doesn’t sound as catchy, does it? DALL·E 2 builds on the foundation established by GLIDE and takes it a step further by conditioning the diffusion process with CLIP image embeddings, instead of with raw text embeddings as proposed in GLIDE.
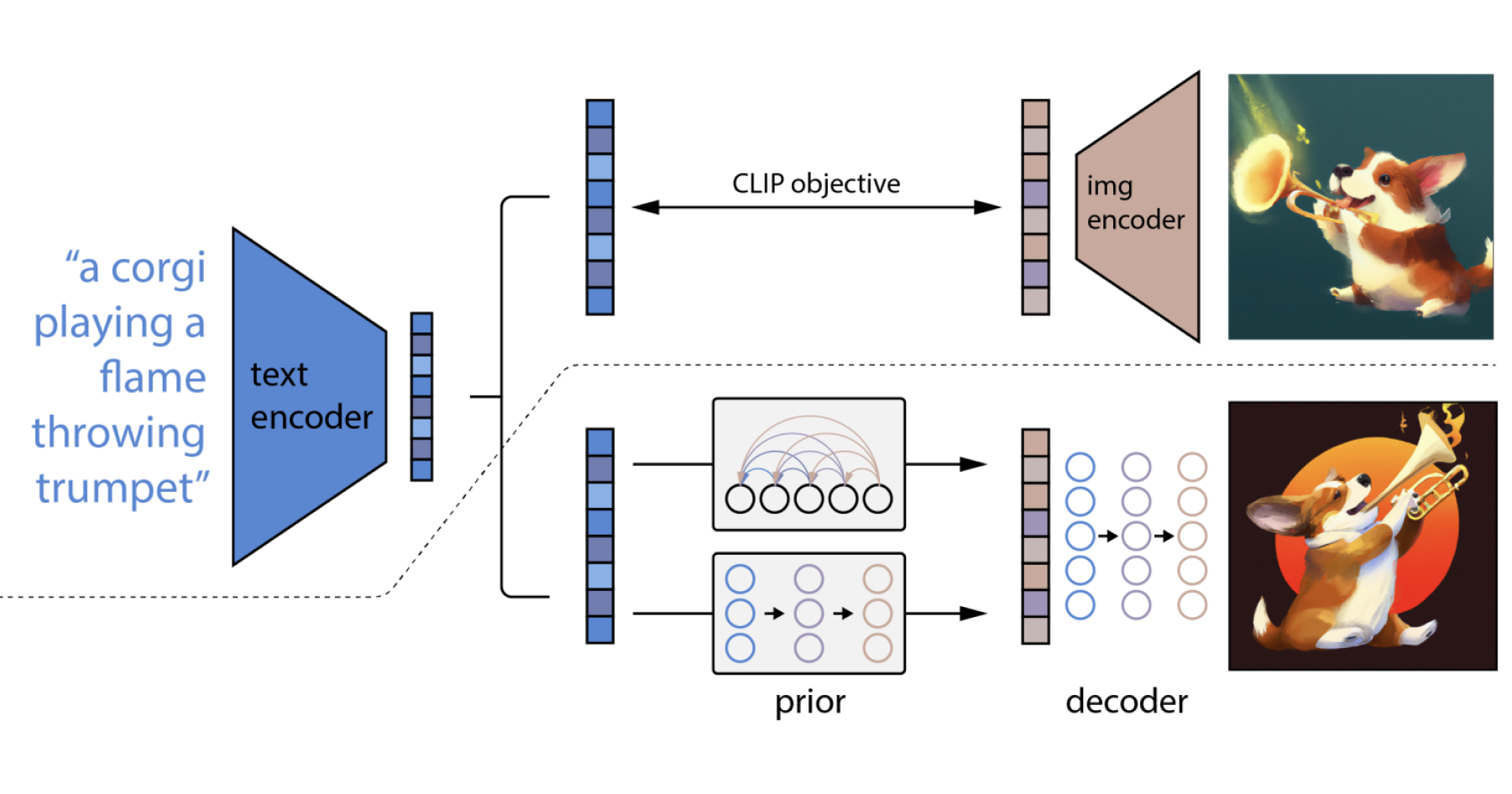
To obtain this image embedding, a CLIP model is trained on CLIP and DALL·E’s combined datasets, and an auxiliary model called the prior (for which they try both autoregressive and diffusion variants) is trained to produce the image embeddings conditioned on both the encoded captions and their CLIP embeddings. This image embedding (and optionally the encoded caption too) is then used to condition the diffusion model used to generate the final image, called the decoder. Classifier-free guidance is enabled too on the same conditioning information, which according to the paper “improves sample quality a lot”.
Using the generated CLIP image embeddings as conditioning not only improves sample diversity compared to GLIDE but also enables some cool byproducts, such as creating variations of an input image by encoding it and decoding it or generating variations between a pair of images or captions by interpolating their embeddings.



Even though DALL·E 2 clearly solves its predecessor’s issues with generating photorealistic pictures, it has some limitations. It struggles with some common issues in multimodal learning, such as compositionality and variable binding — and amusingly, with generating written text.


Imagen
If you felt DALL·E 2’s approach seemed overly complicated, Google is here to tell you they agree. Released only a month after its competitor in May 2022, and claiming “an unprecedented degree of photorealism and a deep level of language understanding”, Imagen improves on GLIDE by simply swapping its custom-trained text encoder for a generic large language model pre-trained on text-only corpora.
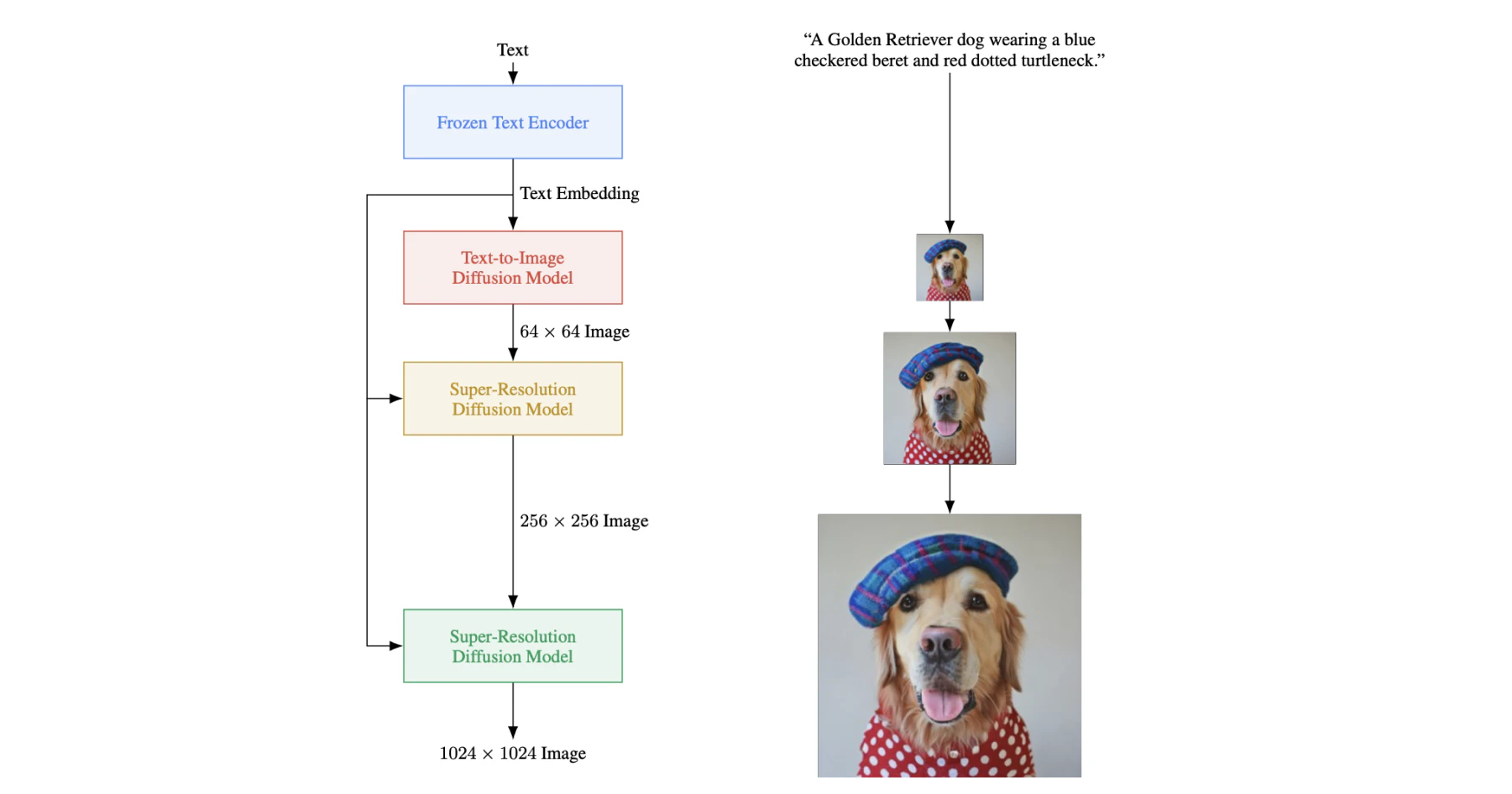
Instead of the 1.2B-parameter Transformer that GLIDE’s authors train on DALL·E’s dataset as part of their training regime, Imagen decides to use a frozen T5-XXL model, which is a huge 4.6B-parameter Transformer trained on a much larger dataset. In the published paper they state to have found generic large language models to be surprisingly effective text encoders for text-to-image generation, and that scaling the size of the frozen text encoder improves sample quality significantly more than scaling the size of the image diffusion model. Note that apart from the core text encoder and text-to-image models, two more diffusion ones are used to scale the output image up from 64x64 to a whopping 1024x1024 px — this is common practice, and is done in a similar way by the other approaches.

Imagen additionally introduces:
- Dynamic thresholding, a neat trick to allow performing stronger guidance during sampling to improve photorealism and text-alignment without generating overly-saturated images.
- Efficient U-Net, a new U-Net which is simpler, more memory-efficient and converges faster.
- DrawBench, a proposed set of prompts to be used to standardize the evaluation of text-to-image models, according to which Imagen outperformed all other existing alternatives at that time.
As if the image generation landscape wasn’t competitive enough as-is, a second team at Google Research working in parallel with Imagen’s decided to put some more wood in the fire by releasing Parti, yet another text-to-image model. Parti takes the autoregressive approach the original DALL·E took (but scaling it to a mindblowing 20B parameters!) instead of the diffusion one so we won’t explore it in detail in this post, but its just as good, if not better, as its diffusion-based counterparts — specially at generating images from longer input descriptions!

Stable Diffusion
Although DALL·E 2, Imagen and Parti produce astonishing results, the former is currently under a beta only select users have limited free access to, and the latter have not been released to the public at all. While seeing these huge advancements being made in the field is a feat in itself, at the moment it is impossible for external organizations or individuals to do follow-up research on them nor to build AI-powered products that make use of such technology. Well, that was up until a few days ago, when Stability AI open-sourced Stable Diffusion to the world.
Not only is Stable Diffusion’s model public (and with public we really do mean public — both code and weights have been released and the model can be set up in minutes through HuggingFace’s diffusers library!), but it is also small enough to fit inside consumer GPUs — which is definitely not the case for the massive models used by the previous two approaches. We obviously had to give it a try on our own and didn’t miss the opportunity to generate some cool dinos that might just end up decorating our office’s walls.


Still not sold on what a big deal open-sourcing months of research in this manner can mean for the whole AI community? Since its release users have obviously used the model to create true masterpieces — even in video format, giving birth to what could even be called a new kind of art. But Stability’s license for their models doesn’t just allow using it for free for personal purposes: it can be baked into new or existing products to expose its whole array of capabilities to less tech-savvy users! This post provides a comprehensive list of the myriad of services, user interfaces and integrations based on Stable Diffusion that have already emerged and that will most surely keep sprouting and evolving in the upcoming months.
So how exactly does Stable Diffusion manage to compress a model comparable to DALL·E 2 into such a tiny footprint? The secret lies in latent diffusion models, a paper published earlier this year, which found that running diffusion directly on an image’s pixel space is not only super slow and computationally expensive, but also unnecessary. Instead, they propose applying diffusion models on the lower-dimensional latent space of a powerful pre-trained autoencoder (similar to the one we mentioned when explaining DALL·E’s approach), and then using the autoencoder itself to decode the final image off it. This allows to separate the compressive from the generative learning phase — i.e. let diffusion models shine at what they do best by generating a sample on a space that is perceptually equivalent to the image space but that offers significantly reduced computational complexity, and let a tried and tested autoencoder do the heavy lifting to obtain the full-sized final image.
Commercial applications
We get it — we’ve gotten really, really good at generating cool images off of a short description… but what for? Are there any real-world applications for this tech? Or is it just for show?
According to a recent article in TechCrunch some businesses are already experimenting with DALL·E 2’s beta, testing out possible use cases for when it becomes stable enough to be knit into their products. StitchFix has experimented using the model to generate images of clothing based on customers’ descriptions, which a stylist could then match with an item in their inventory. Klaviyo, Cosmopolitan, and Heinz have all given DALL·E 2 a spin for marketing purposes, having it generate product visualizations, magazine covers, and brand art respectively, with mixed results. BTW, we have been partnering with companies in the retail industry for a while now, and we curated a guide full of use cases that go further than text-to-image generation models.
The general consensus between these companies seems to be that the model provides value to the people using it, but when used as a tool in the creative process to generate the final image, rather than to generate the final image itself. The ability to produce several different variants for one same prompt can improve creativity or provide an original idea of what the final product should look like — even if none of them is good enough in itself to be used commercially without alterations. It is worth mentioning that prompt engineering, a.k.a. the art of crafting the correct prompts to get a generative model to output exactly what you want, is almost as important as the models’ capabilities themselves, with even books being written to help users make the most out of them!
Diffusion models might have a future in the world of gaming, with some designers testing them out for generating video game assets to then be animated. Although this does raise the age-old question of whether these systems could be used to replace their human counterparts, it seems collaboration between the two is the direction both parts seem to be moving in. It looks like if anyone were to panic because of advancements in this field, it should be the people running stock photo websites, rather than graphic designers and digital artists.
Another possible application sprouts out of these models’ inpainting capabilities, which allow modification of an image on command given a text prompt and a mask. This could not only enable automatic photo editing but also iteratively creating complex scenes from scratch. One can’t fail to imagine such a tool being commercialized in the same way as DALL·E — or even making its way into a new feature in your favorite photo editing software.

Final thoughts
This year has been quite a journey for generative AI. The increase in capabilities these models have experienced in such a short time is truly mind-boggling — and the fact that you are now able to run one for free in consumer GPUs even more so. Having several organizations and the hundreds of brilliant individuals that work at them competing to outdo each other is perfect proof that competition drives innovation.
For several years, it looked like AI could be a tool for solving some challenging problems, but would never help much with those soft ones that require human skills or creativity. Now, it looks like AI progress has surprised us, once again acting as a reminder about how hard it is to predict the direction that things will take — even to field experts.
We hope this new breed of powerful AI models can empower more individuals to be creative, giving them tools that — just a few months back — would have only been a dream.

Wondering how AI
can help you?

Terms and Conditions | © 2026. All rights reserved.