

Machine Learning basics every manager should know



Last update: June 2018
Introduction
The use of Machine Learning for business is growing every day. Consequently, there's an increasing amount of available information about it, which makes it easy to get lost in the Machine Learning jungle.
In this article we'll provide an overview of the most important Machine Learning concepts, explain how they could be applied to businesses and how to measure the success of it.
What is Machine Learning?
According to Adam Geitgey, Machine learning is the idea that there are generic algorithms that can tell you something interesting about a set of data without you having to write any custom code specific to the problem. Instead of writing code, you feed data to the generic algorithm and it builds its own logic based on the data.


Why using Machine Learning for business?
Very often we get people contacting us for projects in which they envision the usage of some Machine Learning (ML) techniques to solve a specific problem they have. Sometimes these people do not have any automated system and are solving whatever problem they currently have with human labor. In these cases, the mere fact of being able to produce anything that works reasonably well can make a huge difference for them.
Imagine, for example, that your company wants you to review 100,000 tweets that make reference to its brand name, because they want to know which customers are not satisfied with products they are selling and why. Wouldn’t it be cool for you if I gave you a tool that can tell you that out of the 100,000 tweets, 95,000 are not even worth looking at because they don’t even talk about products or don’t express negative feelings? It would be a huge time saver.
But there are other times in which people already have working solutions in place. If the problem is very complex, they might not be happy with how their solution performs. Sometimes even a performant solution might need a replacement.
Imagine you have come up with a rule-based engine to process some type data, and then more data starts coming in that is not adequately handled with the rules you have. This can mean that most of the rules that once were good need to be rewritten, and probably also that new rules need to be created. The complexity of the system will not cease to increase. This is another case in which a ML solution might come in handy: let’s make an algorithm figure out the rules for us. Let’s hope it performs better than any non-ML solution we have come up with so far.
How is Machine Learning applied to business?
Some practical applications of Machine Learning in business are Image Processing, Text Analysis or Data Mining.
Image processing
This is the analysis of images/videos to extract data or do some transformations. Examples are face recognition (ie. Facebook's automatic photo tagging), self-driving cars and optical character recognition (digitize text found in images).
Text analysis
In text analysis, information from text is extracted or classified. Examples are spam filtering (as Gmail does), sentiment analysis (identify the mood of the text, ie. positive, negative or neutral) and information extraction (identify key data from a text, for example: an entity).
Data mining
The aim of data mining is to discover patterns or making predictions from data. Examples are anomaly detection (automatic credit card fraud detection), clustering (ie. grouping data based on some characteristics) and predicting variables (ie. predicting stock market prices based on past fluctuations and current events).
What are types of Machine Learning problems?
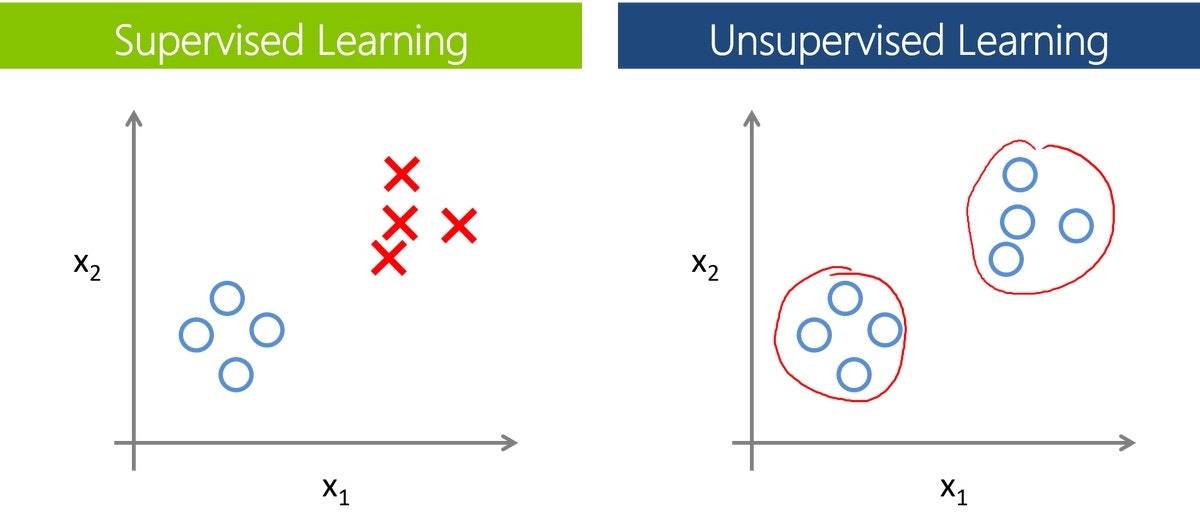
We can distinct between two main types of Machine Learning problems: Supervised learning and Unsupervised learning. There's also Semi-supervised learning, which is less used and not discussed further in this article.
Supervised learning
Supervised learning is the most popular type of Machine Learning algorithms. It is used to find patterns in raw data, based on the results of pretrained data.
To get the pretrained data, the data scientist feeds the algorithm with input data and lets the algorithm predict the outcome. For example, it feeds it with a set of dog and cat images and the algorithm needs to assign the corresponding animal to each of them. If it does not predict right, the data scientist acts like a teacher and corrects the results.
This training process goes on until the desired level of performance is achieved.
Unsupervised learning
Unsupervised learning refers to the task of extracting patterns and hidden structure from raw data without extra information, as opposed to supervised learning where labels are needed.
Unlike supervised learning, we don't have a "teacher" that tells what the correct labels are. In fact, we don't even know what the set of possible labels is. Algorithms are left to their own devices to find relevant structures in the data. There is no "wrong" or "right" answer here.

What are examples of Machine Learning algorithms?
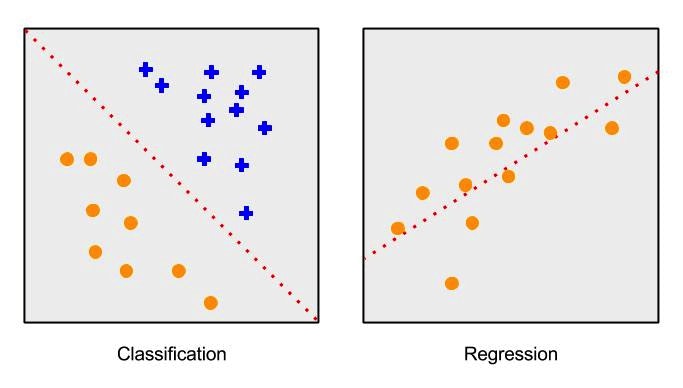
Classification
A classification task means identifying or predicting which out of a set of categories/labels should be assigned to some data. The output variable is discrete, such as "black" or "white" and "positive" or "negative". An example of such as task is the spam filter, which assigns a spam or no spam status to every email.
Regression
In contrast to classification problems, the output variable in regression tasks is a real value, such as "dollars" or "weight", making the prediction a continuous, non-discrete output. A common example of regression is predicting stock market prices.

What are Machine Learning metrics?
It happened in the past that we received contracts, in which the client wanted us to commit to the fact that, by the end of the a classification project, our system would have to achieve 95% accuracy in a classification task. I immediately asked myself two questions:
- Why 95%?
- Why accuracy?
In what follows, we're going to analyze the first question. This post deals with measures of performance and why accuracy in particular is deceiving.
It is clear that when developing a classification system, its going to be very useful to have an objective metric by which we can know how well it performs. But saying 95% because it sounds good is arbitrary unless you have previously done some work to make sure this is indeed achievable.
Why 95% accuracy is not an objective metric
As arbitrary as it is, being right 95% of the times may be an indicator of a great performance for some tasks, while a sign of terrible performance in some others. For example, imagine a dataset in which 99% of the data belongs to class A, and the remaining 1% belongs to class B. Dataset likes this are called imbalanced datasets (guess you weren't expecting that, huh?). A classifier that always says "class A" will be right 99% of the time. I guess no customer would be happy if a contract-compliant solution turned out to be a one-liner like return True or such :-)
Establishing a baseline
What we do in ML tasks first is establishing a baseline. A baseline can be the measure of performance of a very simple system. For example, for a spam detection task a baseline may very well be the output of a system which classifies an email as spam if it contains words such as viagra, pharmacy, etc. Ideally it should be a bit more complex than that. A baseline could also be the performance of a previous, existing system which we wish to improve upon. After establishing what the baseline is, we know a ML solution has to perform at least as good as it. If it doesn't achieve that then we are doing something wrong or need a larger tagged dataset for training (learning), unless the baseline was a really complex system in itself (then maybe it wasn't so much base-line after all).
But even knowing the baseline, and assuming it is less than the 95% our client wanted us to achieve, one cannot promise a certain level of accuracy above it before the ML algorithm is actually built (and 'tweaked' and tested).
Defining the ceiling
How good could it possibly get? For many tasks, achieving 100% accuracy is never possible. And I don't mean just really hard, I actually mean impossible. This is not always the fault of the algorithms: there are algorithms and implementations which can make computers achieve human level performance for certain tasks. The problem is this: when using two humans to classify data independently of each other they might not agree 100% of the time. Say they agree 97% of the time. This is called ceiling and is the absolute maximum performance a ML system will ever be able to achieve. Asking more than that is meaningless. Knowing this, the performance of any ML solution will lie between the baseline and a ceiling (unknown but probably less than 100%).
Getting to know the actual value of the ceiling takes some more effort: you would have to assign at least two persons (with deep knowledge of the data they are going to tag) to tag examples, each one independently of the other, and then calculate their so called agreement rate. There are several metrics used for this, but I will not go in the details. If one were focusing on research this would be a must, but its definitely possible to build a great system (ie. one that saves money by reducing human labour) without knowing the value of the ceiling.
Summing up
- One can never say something like: the baseline is 90% so we are going to get to 95% by the end of this project.
- One can say something like: the baseline is 90%, so we are going to commit to improve that by as much as we can; until we actually do it, we cannot say by how much.

Wondering how AI
can help you?

Terms and Conditions | © 2026. All rights reserved.