

Object Detection with Deep Learning: The Definitive Guide

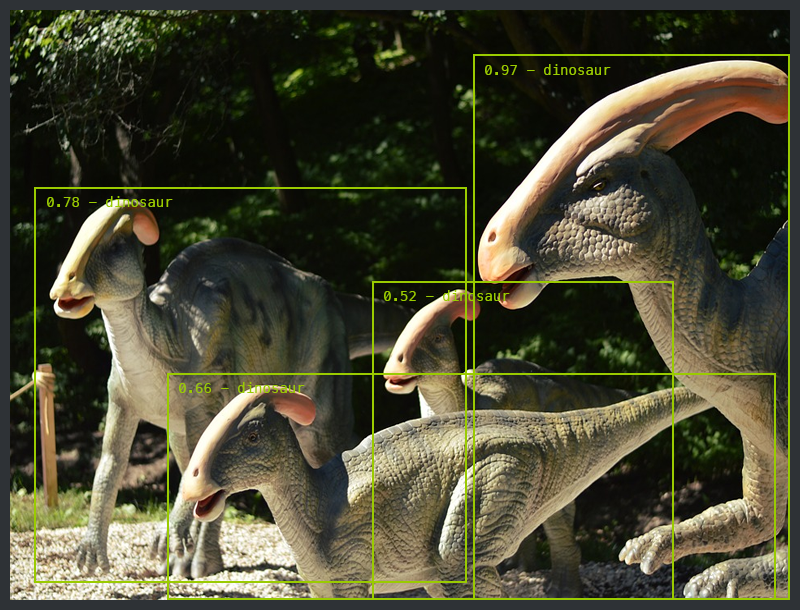
There's no shortage of interesting problems in computer vision, from simple image classification to 3D-pose estimation. One of the problems we’re most interested in and have worked on a bunch is object detection.
Like many other computer vision problems, there still isn't an obvious or even "best" way to approach object detection problems, meaning there’s still much room for improvement.
In this post, we'll do a quick rundown of the most common problems in object detection, go into the details of practical applications and understand how the way to tackle it has been shifting in the last years with deep learning.
Want to jump directly to the object detection with deep learning section? Click here.
Object detection vs. other computer vision problems
Image classification
Probably the most well-known problem in computer vision. It consists of classifying an image into one of many different categories. One of the most popular datasets used in academia is ImageNet, composed of millions of classified images, (partially) utilized in the ImageNet Large Scale Visual Recognition Challenge (ILSVRC) annual competition. In recent years classification models have surpassed human performance and it has been considered practically solved. While there are plenty of challenges to image classification, there are also plenty of write-ups on how it’s usually solved and which are the remaining challenges.


Localization
Similar to classification, localization finds the location of a single object inside the image.


Localization can be used for lots of useful real-life problems. For example, smart cropping (knowing where to crop images based on where the object is located), or even regular object extraction for further processing using different techniques. It can be combined with classification for not only locating the object but categorizing it into one of many possible categories.
Instance segmentation
Going one step further from object detection we would want to not only find objects inside an image, but find a pixel by pixel mask of each of the detected objects. We refer to this problem as instance or object segmentation.
Object detection
Iterating over the problem of localization plus classification we end up with the need for detecting and classifying multiple objects at the same time. Object detection is the problem of finding and classifying a variable number of objects on an image. The important difference is the "variable" part. In contrast with problems like classification, the output of object detection is variable in length, since the number of objects detected may change from image to image.

Practical uses of object detection
At Tryolabs we specialize in applying state of the art machine learning to solve business problems, so even though we love all the crazy machine learning research problems, at the end of the day we end up worrying a lot more about the applications.
Even though object detection is somewhat still of a new tool in the industry, there are already many useful and exciting applications using it.
Face detection
Since the mid-2000s some point and shoot cameras started to come with the feature of detecting faces for a more efficient auto-focus. While it’s a narrower type of object detection, the methods used apply to other types of objects as we’ll describe later.
Counting
One simple but often ignored use of object detection is counting. The ability to count people, cars, flowers, and even microorganisms, is a real world need that is broadly required for different types of systems using images. Recently with the ongoing surge of video surveillance devices, there’s a bigger than ever opportunity to turn that raw information into structured data using computer vision.
Visual Search Engine
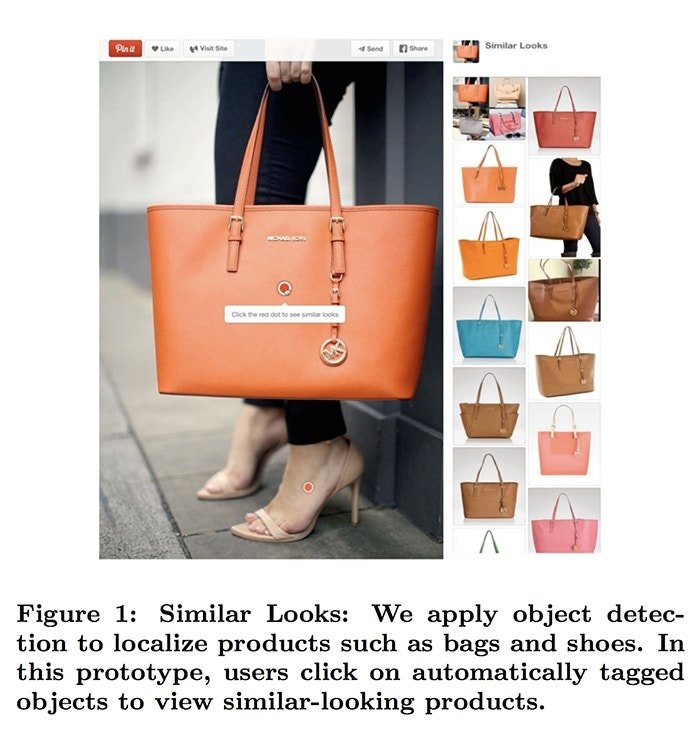
Finally, one use case we’re fond of is the visual search engine of Pinterest. They use object detection as part of the pipeline for indexing different parts of the image. This way when searching for a specific purse, you can find instances of purses similar to the one you want in a different context. This is much more powerful than just finding similar images, like Google Image's reverse search engine does.

Aerial image analysis
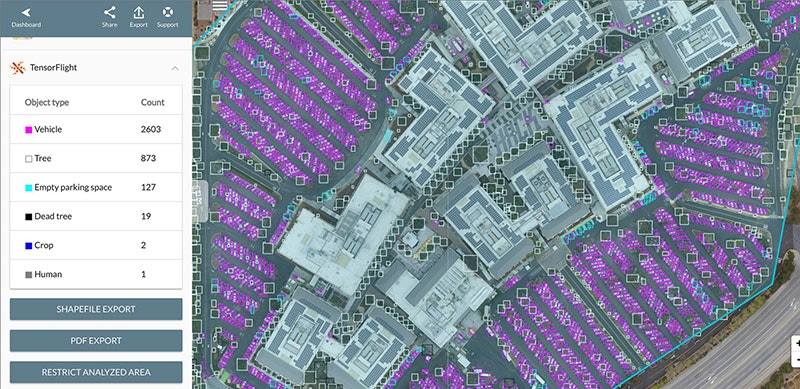
In the age of cheap drones and (close to) affordable satellite launches, there has never been that much data of our world from above. There are already companies using satellite imagery from companies like Planet and Descartes Labs, applying object detection to count cars, trees and ships. This has resulted in high quality data, which was impossible (or extremely expensive) to get before, now reaching a broader audience.
Some companies are using drone footage for automatic inspections on hard to reach places (e.g. BetterView) or using object detection for general purpose analysis (e.g. TensorFlight). On top of this, some companies add automatic detection and location of problems without the need for human intervention.

Problems and challenges with object detection
Let's start getting deeper into which are the main issues of object detection.
Variable number of objects
We already mentioned the part about a variable number of objects, but we omitted why it’s a problem at all. When training machine learning models, you usually need to represent data into fixed-sized vectors. Since the number of objects in the image is not known beforehand, we would not know the correct number of outputs. Because of this, some post-processing is required, which adds complexity to the model.
Historically, the variable number of outputs has been tackled using a sliding window based approach, generating the fixed-sized features of that window for all the different positions of it. After getting all predictions, some are discarded and some are merged to get the final result.
 Sliding window based approach
Sliding window based approachSizing
Another big challenge is the different conceivable sizes of objects. When doing simple classification, you expect and want to classify objects that cover most of the image. On the other hand, some of the objects you may want to find could be a small as a dozen pixels (or a small percentage of the original image). Traditionally this has been solved with using sliding windows of different sizes, which is simple but very inefficient.
Modeling
A third challenge is solving two problems at the same time. How do we combine the two different types of requirements: location and classification into, ideally, a single model?
Before diving into deep learning and how to tackle these challenges, let's do a quick run-up of the classical methods.
Classical approach
Although there have been many different types of methods throughout the years, we want to focus on the two most popular ones (which are still widely used).
The first one is the Viola-Jones framework proposed in 2001 by Paul Viola and Michael Jones in the paper Robust Real-time Object Detection. The approach is fast and relatively simple, so much that it’s the algorithm implemented in point-and-shoot cameras which allows real-time face detection with little processing power.
We won’t go into details on how it works and how to train it, but at the high level, it works by generating different (possibly thousands) simple binary classifiers using Haar features. These classifiers are assessed with a multi-scale sliding window in cascade and dropped early in case of a negative classification.
Another traditional and similar method is using Histogram of Oriented Gradients (HOG) features and Support Vector Machine (SVM) for classification. It still requires a multi-scale sliding window, and even though it’s superior to Viola-Jones, it’s much slower.
Deep learning approach
It’s not news that deep learning has been a real game changer in machine learning, especially in computer vision. In a similar way that deep learning models have crushed other classical models on the task of image classification, deep learning models are now state of the art in object detection as well.
Now that you probably have a better intuition on what the challenges are and how to tackle them, we will do an overview on how the deep learning approach has evolved in the last couple of years.
OverFeat
One of the first advances in using deep learning for object detection was OverFeat from NYU published in 2013. They proposed a multi-scale sliding window algorithm using Convolutional Neural Networks (CNNs).
R-CNN
Quickly after OverFeat, Regions with CNN features or R-CNN from Ross Girshick, et al. at the UC Berkeley was published which boasted an almost 50% improvement on the object detection challenge. What they proposed was a three stage approach:
- Extract possible objects using a region proposal method (the most popular one being Selective Search).
- Extract features from each region using a CNN.
- Classify each region with SVMs.

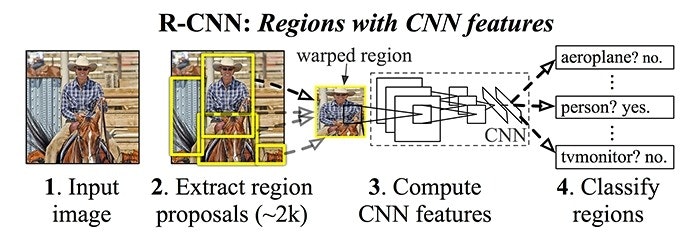
While it achieved great results, the training had lots of problems. To train it you first had to generate proposals for the training dataset, apply the CNN feature extraction to every single one (which usually takes over 200GB for the Pascal 2012 train dataset) and then finally train the SVM classifiers.
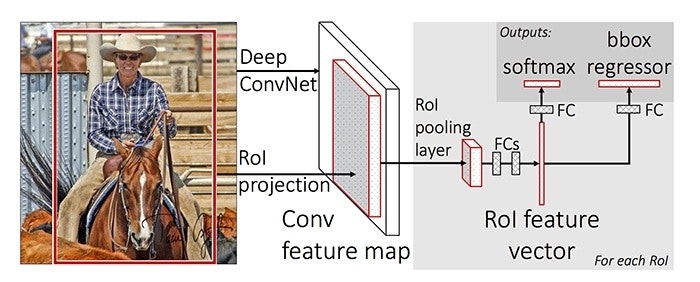
Fast R-CNN
This approach quickly evolved into a purer deep learning one, when a year later Ross Girshick (now at Microsoft Research) published Fast R-CNN. Similar to R-CNN, it used Selective Search to generate object proposals, but instead of extracting all of them independently and using SVM classifiers, it applied the CNN on the complete image and then used both Region of Interest (RoI) Pooling on the feature map with a final feed forward network for classification and regression.
Not only was this approach faster, but having the RoI Pooling layer and the fully connected layers allowed the model to be end-to-end differentiable and easier to train. The biggest downside was that the model still relied on Selective Search (or any other region proposal algorithm), which became the bottleneck when using it for inference.

YOLO
Shortly after that, You Only Look Once: Unified, Real-Time Object Detection (YOLO) paper published by Joseph Redmon (with Girshick appearing as one of the co-authors). YOLO proposed a simple convolutional neural network approach which has both great results and high speed, allowing for the first time real time object detection.


Faster R-CNN
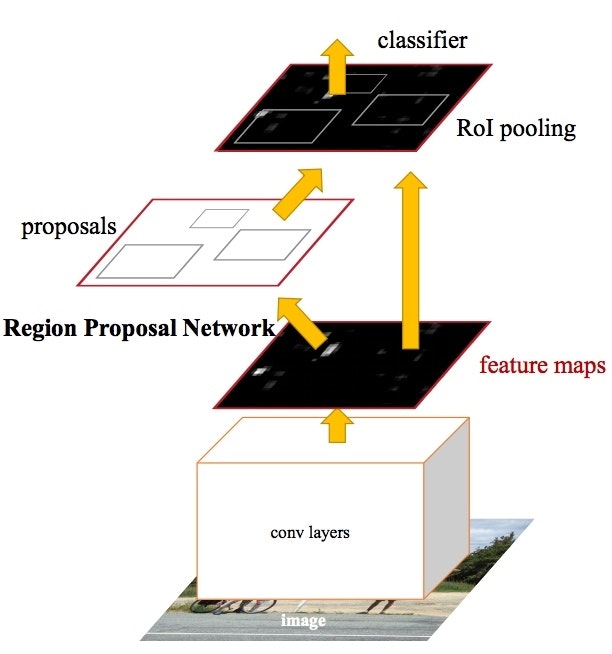
Subsequently, Faster R-CNN authored by Shaoqing Ren (also co-authored by Girshick, now at Facebook Research), the third iteration of the R-CNN series. Faster R-CNN added what they called a Region Proposal Network (RPN), in an attempt to get rid of the Selective Search algorithm and make the model completely trainable end-to-end. We won’t go into details on what the RPNs does, but in abstract it has the task to output objects based on an "objectness" score. These objects are used by the RoI Pooling and fully connected layers for classification.
Read this blog post to get a deeper understanding of the Faster R-CNN architecture and how you can tweak it for your specific case.

SSD and R-FCN
Finally, there are two notable papers, Single Shot Detector (SSD) which takes on YOLO by using multiple sized convolutional feature maps achieving better results and speed, and Region-based Fully Convolutional Networks (R-FCN) which takes the architecture of Faster R-CNN but with only convolutional networks.
Importance of datasets
Datasets play a very important (and sometimes underrated) role in research. Every time a new dataset is released, papers are released, and new models are compared and often improved upon, pushing the limits of what’s possible.
Unfortunately, there aren’t enough datasets for object detection. Data is harder (and more expensive) to generate, companies probably don't feel like freely giving away their investment, and universities do not have that many resources.
There are still some great ones, below is a list of the main available datasets.
| Name | # Images (trainval) | # Classes | Last updated |
|---|---|---|---|
| ImageNet | 450k | 200 | 2015 |
| COCO | 120K | 80 | 2014 |
| Pascal VOC | 12k | 20 | 2012 |
| Oxford-IIIT Pet | 7K | 37 | 2012 |
| KITTI Vision | 7K | 3 | 2014 |
Conclusion
In conclusion, there are many opportunities regarding object detection, both in unseen applications and in new methods for pushing state of the art results. Even though this was just a general overview of object detection, we hope it gives you a basic understanding and a baseline for getting deeper knowledge (no pun intended).

Wondering how AI
can help you?

Terms and Conditions | © 2026. All rights reserved.